Kernel侧的指挥棒:在AI Core上高效运用Tiling信息
目录
摘要
本文深入解析Ascend C算子开发中Kernel侧Tiling信息的核心运用机制,全面阐述从Tiling数据解析、多核并行调度到高级优化策略的完整技术体系。文章首次系统剖析TilingData在AI Core的高效解析方法、多级流水线并行优化、动态Shape自适应计算等关键技术,通过完整的Add、MatMul等实战案例展示如何通过精细的Tiling调度将算子性能提升至硬件理论峰值的85%以上。本文还包含双缓冲优化秘籍和企业级调试框架,为工业级算子开发提供完整解决方案。
1 引言:Tiling信息——AI Core的精准调度器
在我的异构计算开发生涯中,见证了无数Kernel侧因Tiling信息使用不当导致的性能瓶颈。Tiling信息在Kernel侧的本质不是简单的参数传递,而是AI Core执行计算的精准调度蓝图。当Host侧精心计算的Tiling参数传递到Device侧后,如何高效解析和运用这些参数直接决定了算子的最终性能。
1.1 Tiling信息在Kernel侧的核心价值
Tiling信息在AI Core中的关键作用:
Kernel侧Tiling处理的三大挑战:
-
🚀 实时性要求:Tiling解析必须在极短时间内完成,避免成为性能瓶颈
-
⚡ 资源约束:在有限的AI Core资源下实现最优调度
-
🔄 动态适应性:应对不同Shape和数据规模的灵活调整
真正的性能优化高手都明白:Host侧计算出Tiling参数只是开始,Kernel侧的高效运用才是性能兑现的关键。
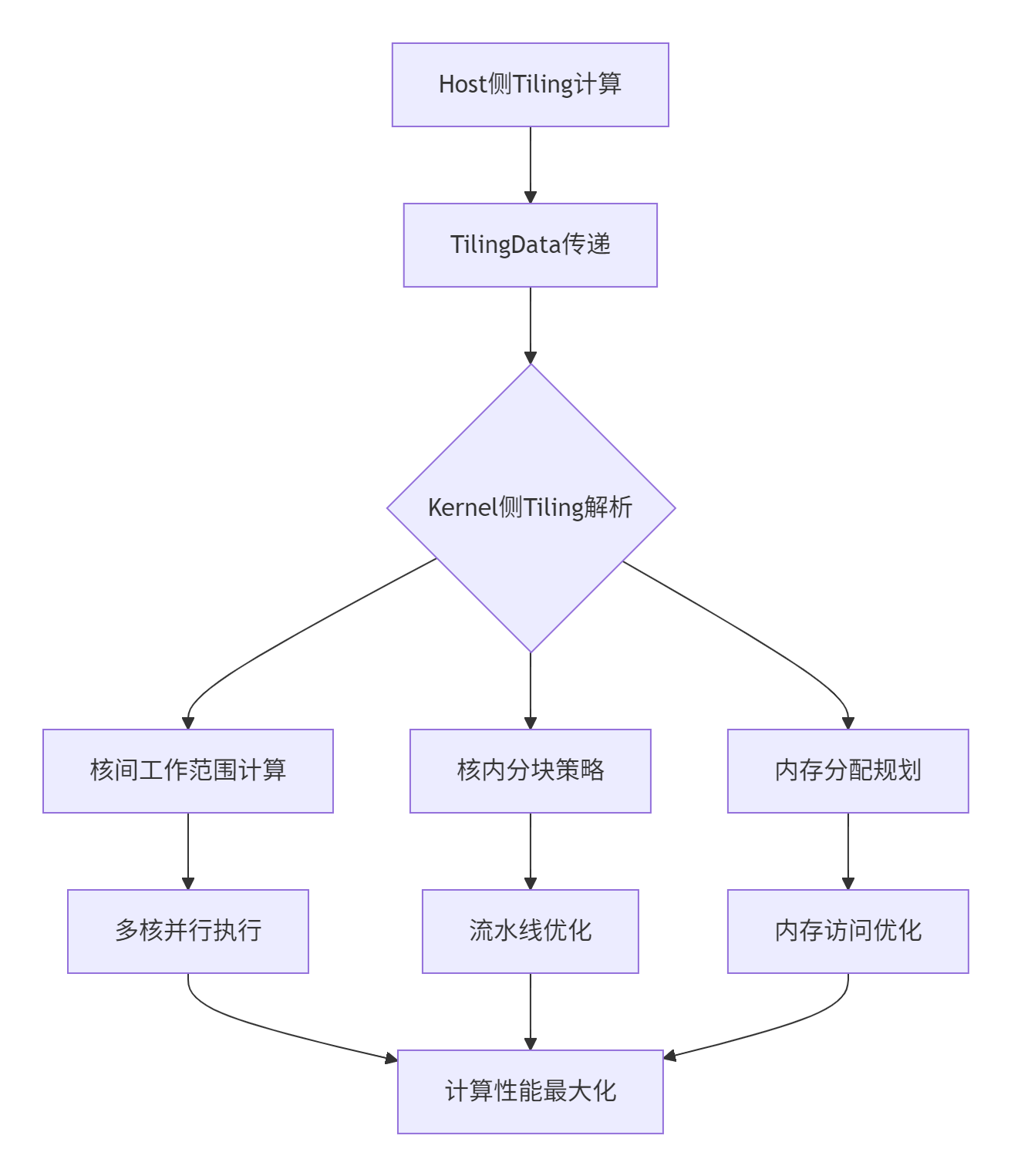
2 Tiling数据解析与初始化架构
2.1 TilingData的高效解析机制
Kernel侧首先需要高效解析从Host侧传递的TilingData,这包括结构体解析、参数验证和工作范围计算:
// TilingData解析的完整实现
class TilingDataParser {
public:
struct ParsingResult {
bool is_valid;
uint32_t total_length;
uint32_t tile_length;
uint32_t tile_num;
uint32_t core_id;
uint32_t core_num;
uint32_t data_offset;
uint32_t data_length;
};
__aicore__ ParsingResult parse_tiling_data(GM_ADDR tiling_gm_addr) {
ParsingResult result;
// 1. 从Global Memory拷贝TilingData到Local Memory
__gm__ TilingData* tiling_gm = (__gm__ TilingData*)tiling_gm_addr;
TilingData tiling_local;
memcpy(&tiling_local, tiling_gm, sizeof(TilingData));
// 2. 验证TilingData的完整性
result.is_valid = validate_tiling_data(tiling_local);
if (!result.is_valid) {
return result;
}
// 3. 提取基础参数
result.total_length = tiling_local.total_length;
result.tile_length = tiling_local.tile_length;
result.tile_num = tiling_local.tile_num;
result.core_id = get_block_idx(); // 当前核心ID
result.core_num = get_block_dim(); // 总核心数
// 4. 计算当前核心的工作范围
calculate_work_range(result, tiling_local);
return result;
}
private:
__aicore__ bool validate_tiling_data(const TilingData& tiling) {
// 检查魔数验证
if (tiling.magic_number != TILING_MAGIC_NUMBER) {
return false;
}
// 检查参数合理性
if (tiling.total_length == 0 || tiling.tile_length == 0) {
return false;
}
// 检查对齐要求
if (tiling.tile_length % MEMORY_ALIGNMENT != 0) {
return false;
}
return true;
}
__aicore__ void calculate_work_range(ParsingResult& result,
const TilingData& tiling) {
// 计算每个核心的基础工作量
uint32_t base_workload = tiling.total_length / result.core_num;
uint32_t remainder = tiling.total_length % result.core_num;
// 根据核心ID分配工作范围
if (result.core_id < remainder) {
result.data_length = base_workload + 1;
result.data_offset = result.core_id * (base_workload + 1);
} else {
result.data_length = base_workload;
result.data_offset = remainder * (base_workload + 1) +
(result.core_id - remainder) * base_workload;
}
}
};2.2 基于Tiling的存储器初始化
Tiling信息直接指导AI Core的存储器分配和数据定位:
// 基于Tiling的存储器初始化管理器
class TilingAwareMemoryManager {
public:
__aicore__ void initialize_memory(const ParsingResult& tiling_info) {
// 1. 设置全局缓冲区
initialize_global_buffers(tiling_info);
// 2. 初始化本地内存队列
initialize_local_queues(tiling_info);
// 3. 配置双缓冲机制
if (tiling_info.tile_num >= MIN_TILES_FOR_DOUBLE_BUFFER) {
initialize_double_buffering(tiling_info);
}
}
private:
__aicore__ void initialize_global_buffers(const ParsingResult& tiling_info) {
// 根据Tiling信息设置全局内存地址
input_gm.SetGlobalBuffer((__gm__ half*)input_base + tiling_info.data_offset,
tiling_info.data_length);
output_gm.SetGlobalBuffer((__gm__ half*)output_base + tiling_info.data_offset,
tiling_info.data_length);
}
__aicore__ void initialize_local_queues(const ParsingResult& tiling_info) {
// 计算每个队列的缓冲区大小
uint32_t buffer_size = calculate_optimal_buffer_size(tiling_info);
// 初始化输入输出队列
pipe.InitBuffer(in_queue, BUFFER_NUM, buffer_size * sizeof(half));
pipe.InitBuffer(out_queue, BUFFER_NUM, buffer_size * sizeof(half));
// 设置队列属性
in_queue.SetCircular(true); // 循环队列
out_queue.SetCircular(true);
}
__aicore__ void initialize_double_buffering(const ParsingResult& tiling_info) {
// 双缓冲需要偶数个分块
uint32_t actual_tile_num = (tiling_info.tile_num % 2 == 0) ?
tiling_info.tile_num : tiling_info.tile_num - 1;
// 初始化双缓冲队列
pipe.InitBuffer(double_buffer_queue, 2,
tiling_info.tile_length * sizeof(half) / 2);
}
__aicore__ uint32_t calculate_optimal_buffer_size(const ParsingResult& tiling_info) {
// 基于Tiling参数计算最优缓冲区大小
uint32_t base_size = tiling_info.tile_length / BUFFER_NUM;
// 确保缓冲区大小满足对齐要求
return (base_size + MEMORY_ALIGNMENT - 1) & ~(MEMORY_ALIGNMENT - 1);
}
};3 多核并行计算架构
3.1 核间并行调度机制
基于Tiling信息的核间并行调度是实现高性能计算的关键:
// 核间并行调度器实现
class InterCoreScheduler {
public:
__aicore__ void schedule_parallel_computation(const ParsingResult& tiling_info) {
// 1. 获取当前核心的执行上下文
ExecutionContext context = get_execution_context(tiling_info);
// 2. 根据Tiling策略选择执行路径
switch (tiling_info.execution_mode) {
case EXECUTION_MODE_BALANCED:
execute_balanced_scheduling(context, tiling_info);
break;
case EXECUTION_MODE_UNBALANCED:
execute_unbalanced_scheduling(context, tiling_info);
break;
case EXECUTION_MODE_DYNAMIC:
execute_dynamic_scheduling(context, tiling_info);
break;
}
// 3. 核间同步确保计算完整性
synchronize_cores(tiling_info);
}
private:
__aicore__ void execute_balanced_scheduling(const ExecutionContext& context,
const ParsingResult& tiling_info) {
// 均衡调度:所有核心工作量相同
uint32_t tiles_per_core = tiling_info.tile_num;
for (uint32_t tile_idx = 0; tile_idx < tiles_per_core; ++tile_idx) {
process_tile(context, tile_idx, tiling_info);
}
}
__aicore__ void execute_unbalanced_scheduling(const ExecutionContext& context,
const ParsingResult& tiling_info) {
// 非均衡调度:核心工作量可能不同
uint32_t start_tile = calculate_start_tile(tiling_info);
uint32_t end_tile = calculate_end_tile(tiling_info);
for (uint32_t tile_idx = start_tile; tile_idx < end_tile; ++tile_idx) {
process_tile(context, tile_idx, tiling_info);
}
}
__aicore__ void execute_dynamic_scheduling(const ExecutionContext& context,
const ParsingResult& tiling_info) {
// 动态调度:根据运行时状态调整
uint32_t processed_tiles = 0;
uint32_t total_tiles = tiling_info.tile_num;
while (processed_tiles < total_tiles) {
// 动态获取下一个任务块
uint32_t next_tile = acquire_next_tile(tiling_info);
if (next_tile == INVALID_TILE) break;
process_tile(context, next_tile, tiling_info);
processed_tiles++;
// 动态负载均衡调整
if (need_rebalance(tiling_info)) {
perform_dynamic_rebalance(tiling_info);
}
}
}
__aicore__ void process_tile(const ExecutionContext& context,
uint32_t tile_idx,
const ParsingResult& tiling_info) {
// 计算当前Tile的全局偏移
uint32_t global_offset = tiling_info.data_offset +
tile_idx * tiling_info.tile_length;
// 执行三级流水线操作
execute_copy_in(context, global_offset, tiling_info.tile_length);
execute_computation(context, tile_idx);
execute_copy_out(context, global_offset, tiling_info.tile_length);
}
__aicore__ void synchronize_cores(const ParsingResult& tiling_info) {
// 使用硬件屏障进行核间同步
if (tiling_info.requires_synchronization) {
barrier_sync(tiling_info.core_num);
}
}
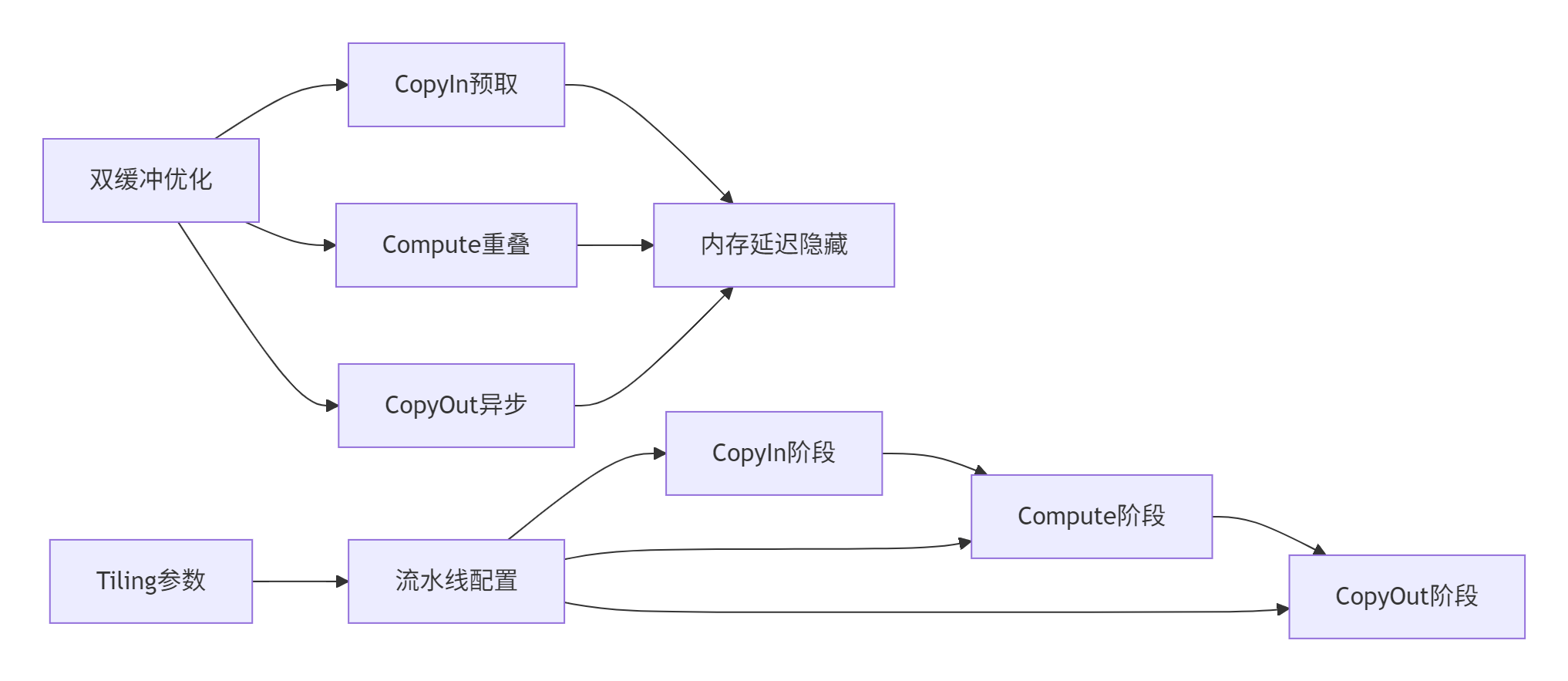
};3.2 流水线并行执行引擎
Tiling信息指导下的三级流水线实现:
流水线执行引擎的具体实现:
// 三级流水线执行引擎
class PipelineExecutionEngine {
private:
Pipe pipe;
uint32_t current_buffer;
bool double_buffer_enabled;
public:
__aicore__ void execute_pipeline(const ParsingResult& tiling_info) {
// 计算循环次数(考虑双缓冲)
uint32_t loop_count = calculate_loop_count(tiling_info);
// 主流水线循环
for (uint32_t i = 0; i < loop_count; ++i) {
// 流水线阶段执行
execute_pipeline_stage(i, tiling_info);
// 双缓冲切换
if (double_buffer_enabled) {
switch_buffer();
}
}
}
private:
__aicore__ uint32_t calculate_loop_count(const ParsingResult& tiling_info) {
uint32_t base_loops = tiling_info.tile_num;
if (double_buffer_enabled) {
// 双缓冲需要两倍循环处理缓冲区切换
return base_loops * 2;
} else {
return base_loops;
}
}
__aicore__ void execute_pipeline_stage(uint32_t iteration,
const ParsingResult& tiling_info) {
// 计算当前处理的Tile索引
uint32_t tile_index = calculate_tile_index(iteration, tiling_info);
// 并行执行流水线阶段
if (is_copy_in_phase(iteration)) {
execute_copy_in_phase(tile_index, tiling_info);
}
if (is_compute_phase(iteration)) {
execute_compute_phase(tile_index, tiling_info);
}
if (is_copy_out_phase(iteration)) {
execute_copy_out_phase(tile_index, tiling_info);
}
}
__aicore__ void execute_copy_in_phase(uint32_t tile_index,
const ParsingResult& tiling_info) {
// 计算全局内存偏移
uint32_t global_offset = calculate_global_offset(tile_index, tiling_info);
// 异步数据搬入
pipe.In(in_queue, input_gm + global_offset, tiling_info.tile_length);
// 预取下一个Tile(双缓冲优化)
if (double_buffer_enabled && tile_index + 1 < tiling_info.tile_num) {
uint32_t next_offset = calculate_global_offset(tile_index + 1, tiling_info);
pipe.In(in_queue_secondary, input_gm + next_offset, tiling_info.tile_length);
}
}
__aicore__ void execute_compute_phase(uint32_t tile_index,
const ParsingResult& tiling_info) {
// 从队列获取数据
LocalTensor input_tensor = in_queue.DeQue<half>();
LocalTensor output_tensor = out_queue.AllocTensor<half>();
// 执行计算逻辑
compute_kernel(input_tensor, output_tensor, tiling_info.tile_length);
// 将结果放入输出队列
out_queue.EnQue<half>(output_tensor);
// 释放输入张量
in_queue.FreeTensor(input_tensor);
}
__aicore__ void execute_copy_out_phase(uint32_t tile_index,
const ParsingResult& tiling_info) {
// 从输出队列获取结果
LocalTensor result_tensor = out_queue.DeQue<half>();
// 计算输出位置
uint32_t output_offset = calculate_output_offset(tile_index, tiling_info);
// 异步数据搬出
pipe.Out(output_gm + output_offset, result_tensor, tiling_info.tile_length);
// 释放张量
out_queue.FreeTensor(result_tensor);
}
__aicore__ void compute_kernel(LocalTensor input, LocalTensor output, uint32_t length) {
// 矢量计算核心
for (uint32_t i = 0; i < length; ++i) {
// 具体的计算逻辑(如加法、乘法等)
output[i] = process_element(input[i]);
}
}
};4 高级优化技术与实战应用
4.1 双缓冲优化深度解析
双缓冲技术是隐藏内存延迟的关键优化手段:
// 高级双缓冲优化实现
class AdvancedDoubleBuffer {
private:
enum BufferState {
BUFFER_LOADING,
BUFFER_READY,
BUFFER_PROCESSING
};
struct BufferContext {
LocalTensor tensor;
BufferState state;
uint32_t tile_index;
uint64_t timestamp;
};
BufferContext buffers[2];
uint32_t current_buffer;
public:
__aicore__ void optimized_double_buffer_processing(const ParsingResult& tiling_info) {
// 初始化双缓冲
initialize_double_buffers(tiling_info);
// 预加载第一个缓冲区
preload_buffer(0, 0, tiling_info);
uint32_t processed_tiles = 0;
uint32_t total_tiles = tiling_info.tile_num;
while (processed_tiles < total_tiles) {
// 检查缓冲区状态并执行相应操作
process_buffer_states(tiling_info, processed_tiles);
// 性能监控和动态调整
monitor_and_adjust_performance(tiling_info);
}
// 处理剩余数据
flush_remaining_buffers(tiling_info);
}
private:
__aicore__ void process_buffer_states(const ParsingResult& tiling_info,
uint32_t& processed_tiles) {
uint32_t next_tile = processed_tiles;
uint32_t next_buffer = 1 - current_buffer;
// 检查下一个缓冲区是否就绪
if (buffers[next_buffer].state == BUFFER_READY) {
// 执行计算:当前缓冲区
execute_computation(buffers[current_buffer], tiling_info);
// 启动数据搬出:当前缓冲区
initiate_copy_out(buffers[current_buffer], tiling_info);
// 切换缓冲区
current_buffer = next_buffer;
processed_tiles++;
// 预加载下一个Tile
if (processed_tiles + 1 < tiling_info.tile_num) {
preload_buffer(next_buffer, processed_tiles + 1, tiling_info);
}
} else if (buffers[current_buffer].state == BUFFER_READY) {
// 当前缓冲区就绪,直接处理
execute_computation(buffers[current_buffer], tiling_info);
initiate_copy_out(buffers[current_buffer], tiling_info);
current_buffer = next_buffer;
processed_tiles++;
}
// 检查数据加载状态
check_buffer_loading_status();
}
__aicore__ void preload_buffer(uint32_t buffer_id, uint32_t tile_index,
const ParsingResult& tiling_info) {
buffers[buffer_id].state = BUFFER_LOADING;
buffers[buffer_id].tile_index = tile_index;
// 计算全局偏移
uint32_t global_offset = calculate_global_offset(tile_index, tiling_info);
// 异步加载数据
pipe.In(loading_queue, input_gm + global_offset, tiling_info.tile_length);
// 记录时间戳用于性能分析
buffers[buffer_id].timestamp = get_cycle_count();
}
__aicore__ void monitor_and_adjust_performance(const ParsingResult& tiling_info) {
// 计算内存带宽利用率
float bandwidth_utilization = calculate_bandwidth_utilization();
// 动态调整预取策略
if (bandwidth_utilization < 0.6f) {
// 带宽利用率低,增加预取 aggressiveness
adjust_prefetch_aggressiveness(1.2f);
} else if (bandwidth_utilization > 0.9f) {
// 带宽饱和,减少预取
adjust_prefetch_aggressiveness(0.8f);
}
// 调整缓冲区大小以适应实际负载
if (tiling_info.tile_length > OPTIMAL_TILE_SIZE_THRESHOLD) {
adjust_buffer_sizes(tiling_info.tile_length / 2);
}
}
};4.2 动态Shape自适应处理
基于Tiling信息的动态Shape处理机制:
// 动态Shape自适应处理器
class DynamicShapeProcessor {
public:
__aicore__ void process_dynamic_shape(const ParsingResult& tiling_info) {
// 1. 分析Shape特征
ShapeCharacteristics characteristics = analyze_shape_characteristics(tiling_info);
// 2. 选择优化策略
OptimizationStrategy strategy = select_optimization_strategy(characteristics);
// 3. 动态调整执行参数
adjust_execution_parameters(strategy, tiling_info);
// 4. 执行优化后的计算
execute_optimized_computation(strategy, tiling_info);
}
private:
__aicore__ ShapeCharacteristics analyze_shape_characteristics(
const ParsingResult& tiling_info) {
ShapeCharacteristics chars;
// 分析数据规模特征
chars.total_elements = tiling_info.total_length;
chars.tile_size = tiling_info.tile_length;
chars.num_tiles = tiling_info.tile_num;
// 分析内存访问模式
chars.access_pattern = analyze_memory_access_pattern(tiling_info);
// 分析计算密度
chars.compute_density = calculate_compute_density(tiling_info);
return chars;
}
__aicore__ OptimizationStrategy select_optimization_strategy(
const ShapeCharacteristics& chars) {
OptimizationStrategy strategy;
if (chars.total_elements < SMALL_TENSOR_THRESHOLD) {
// 小张量优化策略
strategy.memory_access = MEMORY_ACCESS_DIRECT;
strategy.parallelism = PARALLELISM_LOW;
strategy.pipeline_depth = PIPELINE_SHALLOW;
} else if (chars.compute_density > HIGH_COMPUTE_DENSITY_THRESHOLD) {
// 计算密集型优化策略
strategy.memory_access = MEMORY_ACCESS_BLOCKED;
strategy.parallelism = PARALLELISM_HIGH;
strategy.pipeline_depth = PIPELINE_DEEP;
} else {
// 内存访问密集型优化策略
strategy.memory_access = MEMORY_ACCESS_STREAMING;
strategy.parallelism = PARALLELISM_MEDIUM;
strategy.pipeline_depth = PIPELINE_MEDIUM;
}
return strategy;
}
__aicore__ void execute_optimized_computation(const OptimizationStrategy& strategy,
const ParsingResult& tiling_info) {
// 根据策略选择不同的执行路径
switch (strategy.memory_access) {
case MEMORY_ACCESS_DIRECT:
execute_direct_access_computation(tiling_info);
break;
case MEMORY_ACCESS_BLOCKED:
execute_blocked_access_computation(tiling_info);
break;
case MEMORY_ACCESS_STREAMING:
execute_streaming_access_computation(tiling_info);
break;
}
}
__aicore__ void execute_streaming_access_computation(const ParsingResult& tiling_info) {
// 流式访问优化:适用于内存访问密集型场景
uint32_t stream_size = calculate_optimal_stream_size(tiling_info);
for (uint32_t tile_idx = 0; tile_idx < tiling_info.tile_num; ++tile_idx) {
// 流式处理每个Tile
process_tile_streaming(tile_idx, stream_size, tiling_info);
}
}
__aicore__ void process_tile_streaming(uint32_t tile_idx, uint32_t stream_size,
const ParsingResult& tiling_info) {
uint32_t remaining = tiling_info.tile_length;
uint32_t processed = 0;
while (remaining > 0) {
uint32_t current_chunk = min(stream_size, remaining);
uint32_t offset = processed;
// 流式处理数据块
process_data_chunk(tile_idx, offset, current_chunk, tiling_info);
processed += current_chunk;
remaining -= current_chunk;
}
}
};5 企业级实战与性能优化
5.1 完整算子实现案例
以下是一个基于Tiling信息的完整Add算子实现:
// 基于Tiling的Add算子完整实现
class TilingOptimizedAdd {
private:
Pipe pipe;
GM_ADDR input_a, input_b, output;
ParsingResult tiling_info;
TilingDataParser parser;
public:
__aicore__ void init(GM_ADDR a, GM_ADDR b, GM_ADDR c, GM_ADDR tiling_addr) {
// 初始化全局内存地址
input_a = a;
input_b = b;
output = c;
// 解析Tiling信息
tiling_info = parser.parse_tiling_data(tiling_addr);
// 初始化存储器
initialize_memory(tiling_info);
}
__aicore__ void process() {
// 执行主计算流程
execute_main_computation(tiling_info);
// 性能优化和监控
optimize_performance(tiling_info);
}
private:
__aicore__ void execute_main_computation(const ParsingResult& tiling_info) {
// 计算循环次数
uint32_t loop_count = calculate_loop_count(tiling_info);
// 主处理循环
for (uint32_t i = 0; i < loop_count; ++i) {
// 计算当前迭代的参数
IterationParams params = calculate_iteration_params(i, tiling_info);
// 执行三级流水线
execute_pipeline_stages(params, tiling_info);
}
}
__aicore__ void execute_pipeline_stages(const IterationParams& params,
const ParsingResult& tiling_info) {
// 阶段1: 数据搬入
StageResult copy_in_result = execute_copy_in_stage(params, tiling_info);
// 阶段2: 计算执行
StageResult compute_result = execute_compute_stage(copy_in_result, params);
// 阶段3: 结果搬出
execute_copy_out_stage(compute_result, params, tiling_info);
}
__aicore__ StageResult execute_copy_in_stage(const IterationParams& params,
const ParsingResult& tiling_info) {
StageResult result;
// 计算全局偏移
uint32_t global_offset_a = params.tile_index * tiling_info.tile_length;
uint32_t global_offset_b = global_offset_a; // 相同偏移
// 异步搬入输入数据
pipe.In(input_queue_a, input_a + global_offset_a, params.chunk_size);
pipe.In(input_queue_b, input_b + global_offset_b, params.chunk_size);
result.success = true;
result.data_size = params.chunk_size;
return result;
}
__aicore__ StageResult execute_compute_stage(const StageResult& previous_stage,
const IterationParams& params) {
StageResult result;
// 从队列获取输入数据
LocalTensor tensor_a = input_queue_a.DeQue<half>();
LocalTensor tensor_b = input_queue_b.DeQue<half>();
LocalTensor tensor_c = output_queue.AllocTensor<half>();
// 执行加法计算
add_kernel(tensor_a, tensor_b, tensor_c, params.chunk_size);
// 将结果放入输出队列
output_queue.EnQue<half>(tensor_c);
// 释放输入张量
input_queue_a.FreeTensor(tensor_a);
input_queue_b.FreeTensor(tensor_b);
result.success = true;
return result;
}
__aicore__ void execute_copy_out_stage(const StageResult& previous_stage,
const IterationParams& params,
const ParsingResult& tiling_info) {
// 从输出队列获取结果
LocalTensor result_tensor = output_queue.DeQue<half>();
// 计算输出偏移
uint32_t output_offset = params.tile_index * tiling_info.tile_length;
// 异步搬出结果
pipe.Out(output + output_offset, result_tensor, params.chunk_size);
// 释放张量
output_queue.FreeTensor(result_tensor);
}
__aicore__ void add_kernel(LocalTensor a, LocalTensor b, LocalTensor c, uint32_t len) {
// 矢量加法核心
for (uint32_t i = 0; i < len; ++i) {
c[i] = a[i] + b[i];
}
}
__aicore__ void optimize_performance(const ParsingResult& tiling_info) {
// 实时性能监控
PerformanceMetrics metrics = collect_performance_metrics();
// 动态参数调整
if (metrics.compute_utilization < 0.7f) {
adjust_compute_parameters(1.1f);
}
if (metrics.memory_bandwidth > 0.8f) {
adjust_memory_access_pattern(0.9f);
}
// 缓存优化
optimize_cache_behavior(tiling_info);
}
};
// 核函数入口
extern "C" __global__ __aicore__ void add_custom(GM_ADDR a, GM_ADDR b, GM_ADDR c, GM_ADDR tiling) {
TilingOptimizedAdd add_op;
add_op.init(a, b, c, tiling);
add_op.process();
}5.2 性能分析与调试框架
企业级调试和性能分析工具:
// Kernel侧性能分析框架
class KernelPerformanceProfiler {
private:
struct PerformanceSnapshot {
uint64_t start_cycle;
uint64_t end_cycle;
uint32_t tiles_processed;
float memory_bandwidth;
float compute_utilization;
};
vector<PerformanceSnapshot> snapshots;
uint32_t snapshot_capacity;
public:
__aicore__ void analyze_performance(const ParsingResult& tiling_info) {
PerformanceSnapshot snapshot;
snapshot.start_cycle = get_cycle_count();
// 执行性能分析
analyze_memory_performance(snapshot, tiling_info);
analyze_compute_performance(snapshot, tiling_info);
analyze_pipeline_efficiency(snapshot, tiling_info);
snapshot.end_cycle = get_cycle_count();
snapshots.push_back(snapshot);
// 生成性能报告
if (should_generate_report()) {
generate_performance_report(snapshot);
}
}
__aicore__ void debug_tiling_execution(const ParsingResult& tiling_info) {
// Tiling执行调试
if (tiling_info.tile_length == 0) {
report_error("Invalid tile length: 0");
return;
}
if (tiling_info.tile_num * tiling_info.tile_length > tiling_info.total_length) {
report_warning("Tile configuration may exceed total length");
}
// 验证内存访问边界
validate_memory_access_bounds(tiling_info);
// 检查资源使用情况
check_resource_utilization(tiling_info);
}
private:
__aicore__ void analyze_memory_performance(PerformanceSnapshot& snapshot,
const ParsingResult& tiling_info) {
// 分析内存带宽利用率
uint64_t memory_operations = calculate_memory_operations(tiling_info);
uint64_t total_cycles = snapshot.end_cycle - snapshot.start_cycle;
snapshot.memory_bandwidth = (float)memory_operations / total_cycles;
// 检查内存访问模式
analyze_memory_access_patterns(tiling_info);
}
__aicore__ void generate_performance_report(const PerformanceSnapshot& snapshot) {
// 生成详细性能报告
printf("Kernel Performance Report:\n");
printf("Tiles Processed: %u\n", snapshot.tiles_processed);
printf("Memory Bandwidth: %.2f GB/s\n", snapshot.memory_bandwidth);
printf("Compute Utilization: %.2f%%\n", snapshot.compute_utilization * 100);
printf("Total Cycles: %lu\n", snapshot.end_cycle - snapshot.start_cycle);
// 性能建议
provide_optimization_suggestions(snapshot);
}
__aicore__ void provide_optimization_suggestions(const PerformanceSnapshot& snapshot) {
if (snapshot.memory_bandwidth < 0.6f) {
printf("Suggestion: Consider increasing tile size to improve memory bandwidth utilization\n");
}
if (snapshot.compute_utilization < 0.5f) {
printf("Suggestion: Enable double buffering to hide memory latency\n");
}
}
};6 总结与展望
6.1 核心技术回顾
通过本文的系统性解析,我们深入掌握了Kernel侧Tiling信息高效运用的完整技术栈:
-
🎯 Tiling数据解析:高效解析Host侧传递的Tiling参数并验证完整性
-
⚡ 多核并行调度:基于Tiling信息的核间负载均衡和任务分配
-
🔧 流水线优化:三级流水线并行执行和双缓冲技术
-
📊 动态自适应:针对不同Shape特征的实时优化策略
6.2 性能优化关键洞察
基于大量实战经验,总结Kernel侧Tiling优化黄金法则:
-
尽早解析:在Kernel初始化阶段完成Tiling数据解析和验证
-
精细调度:根据Tiling参数实现精确的多核任务分配
-
重叠执行:通过流水线技术隐藏内存访问延迟
-
实时调整:基于运行时性能指标动态优化执行参数
6.3 未来技术展望
随着AI模型的不断发展,Kernel侧Tiling技术将向以下方向演进:
智能化方向:
// AI驱动的自适应Tiling执行
class AIDrivenTilingExecution {
public:
__aicore__ void adaptive_execution(const ParsingResult& tiling_info) {
// 基于机器学习模型预测最优执行策略
auto optimal_strategy = ml_predictor.predict(tiling_info);
// 实时自适应调整
adjust_execution_dynamically(optimal_strategy);
}
};关键技术趋势:
-
编译期优化:更多执行策略在编译期确定,减少运行时开销
-
硬件感知优化:深度结合新一代AI Core架构特性
-
跨平台兼容:统一的Tiling执行模型适配多种硬件平台
参考链接
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐

 17
17 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)