登录社区云,与社区用户共同成长
邀请您加入社区
随着大模型训练与推理、推荐系统及多模态应用等AI场景的爆发式发展,新一代AI芯片的算力突破已成为行业刚需。Ascend 950作为面向AI计算的新一代芯片,通过第三代DaVinci Core架构、灵衢互联技术以及MXFP4/MXFP8等低精度计算等特性支持,为AI应用提供了强大的算力底座。然而,硬件算力的充分释放离不开高效的软件栈支持。CANN作为昇腾AI处理器的异构计算架构,通过持续演进,已经形
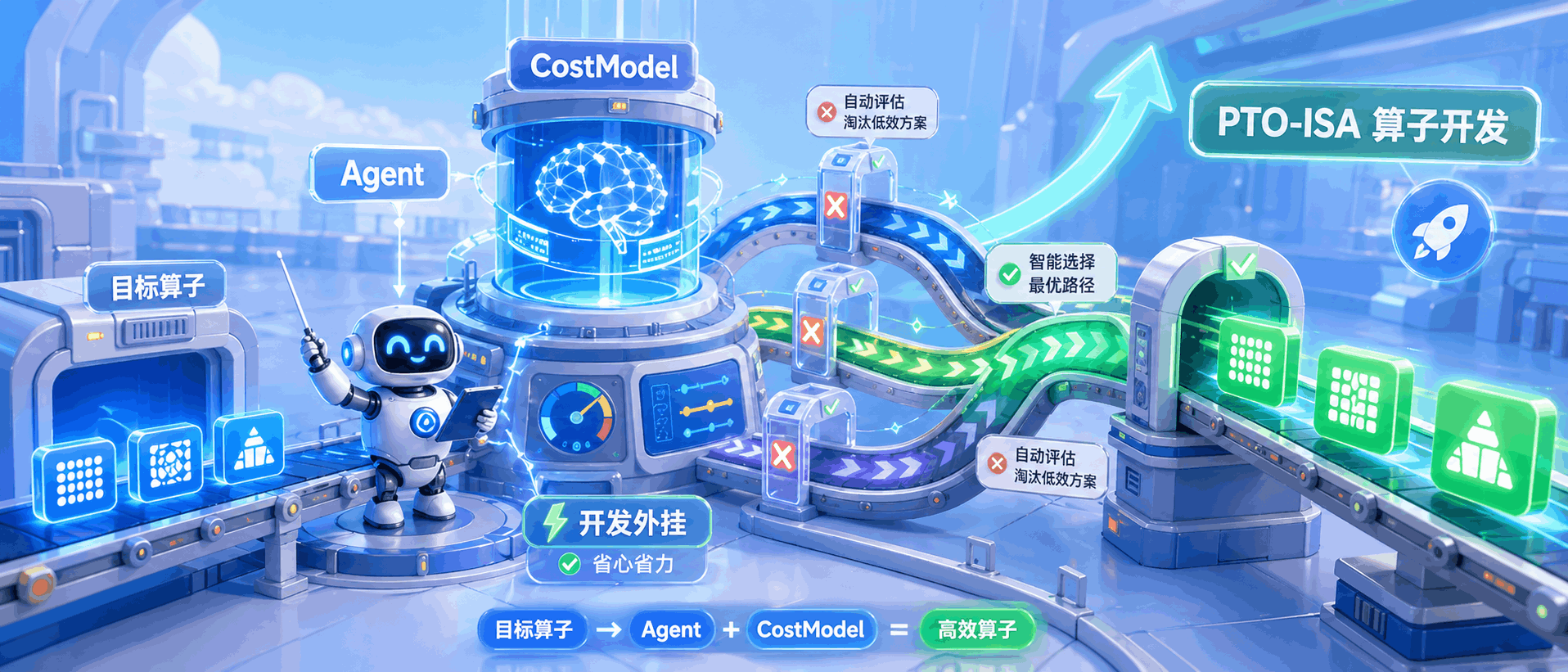
当搜索空间足够大时,优化效率本身就是性能工程的一部分。 背景与问题 FlashAttention 是大模型推理和训练中不可或缺的核心算子。在昇腾平台上,torch_npu 提供了高度优化的融合实现,作为性能基线。但当我们需要通过 PTO(Parallel Tile Operation)来定制 FlashAttention 的行为——比如适配不同的 attention 变体、调整精度策略
文链接(链接跳转异常请到原文中查看):NPU DeepSeek-V4推理优化实践 直播回放链接:DeepSeek-V4昇腾首发:基于CANN的训推优化实践 DeepSeek团队发布了最新的模型DeepSeek-V4系列模型,包含DeepSeek-V4 Flash和DeepSeek-V4 Pro两种规格。通过Compressed Sparse Attention (CSA)和 Heavily Com
背景介绍 MoE(Mixture of Experts,专家混合)模型是当前大规模模型提升参数规模与计算效率的重要技术路径,而 Combine 与 Dispatch 则是实现 MoE 路由机制的关键算子。客户在 CANN 开源 Combine 和 Dispatch 算子的基础上进行了进一步优化,显著提升了 MoE 模块的整体性能表现,为业务带来了更高的吞吐能力。 Dispatch&Comb
背景介绍 随着 AI 模型结构不断演进,尤其是在 MoE 和多模态场景中,越来越多的网络开始采用动态、细粒度的小算子组合来表达计算。小算子虽然提升了模型设计灵活性,但单独执行时往往存在访存和调度开销大等问题,导致整体执行效率偏低,因此需要通过算子融合来提升性能。然而手动融合算子需要从算子代码层面进行重构,人力和时间成本开销大,为此CANN的AutoFuse组件与具有成熟生态的TorchInduct
当芯片越来越强,程序员为什么反而更难掌控它? 2026年3月,新一代昇腾950系列芯片逐渐浮出水面。 如果把它摊开来看,像不像一张密密麻麻的工业园区图? 32个矩阵运算单元、64个向量处理核心、1.6TB/s的DDR带宽、1728 TFlops的FP4算力。数字很耀眼,硬件很凶猛。可问题也正出在这里:芯片越强,驾驭它的人却未必越轻松。 为什么?因为它不再是一座小作坊,而是
近日,CANN开源社区首个面向垂直行业的Material Chemical Engineering SIG(材料化学工程特别兴趣小组,简称MCE SIG)正式发布两款科学计算算子——LJForceFused分子动力学算子与耗散粒子动力学(DPD)算子。两款算子分别面向微观原子尺度与介观流体尺度,标志着该SIG初步完成多尺度计算布局,为流程工业领域提供了专业开源算子基础设施。 目前两款算子已覆盖催化
面向Ascend 950,CANN技术架构的变与不变 当前,人工智能正以前所未有的速度渗透千行百业,推动 AI 算力需求呈指数级增长,算力已成为人工智能产业发展的核心竞争力。 在此背景下,昇腾推出新一代AI芯片Ascend 950PR与Ascend 950DT。两款芯片在继承上一代优秀能力的基础上,围绕计算、通信等关键维度实现多项技术突破,涵盖NDDMA、CV融合、SIMT、UB、CCU等创新特性
摘要 在大规模分布式训练和推理业务中,集合通信的性能是影响整体系统性能的关键瓶颈之一。传统集合通信方式依赖AI CPU、AI Vector等计算单元通过软件协议栈构造通信任务描述符,驱动硬件执行通信任务。然而,这种执行方式不仅需要占用计算核资源,而且软件接口的开销较大,叠加计算算子后,计算和通信会抢占多种硬件资源,导致效率下降。为了解决这一问题,Ascend 950中引入了 集合通信处理器(Col