CANNBot + DeepSeek-V4 实操:30 分钟生成可达理论性能极限的 MXFP8 Matmul + Add 融合算子
二是为算子开发者与算法研究者提供可灵活组合与扩展的高性能实现单元,使其能够在已有工程沉淀的基础上快速搭建满足业务需求的定制化算子,将新算子从算法构想到可用版本的开发周期由周级压缩至小时级。1、泛化融合场景生成能力:当前的算子生成方式是基于cann-samples仓中已有的高性能实现做有限的扩展及开发,仅局限于固定的Matmul + ElementWise 组合场景,不具备泛化融合场景的算子生成能力
摘要
DeepSeek-V4 在通用编程领域表现惊艳,但当场景转向 NPU Ascend C 融合算子开发——这类高度依赖硬件架构知识和性能调优经验的垂直领域时,它的表现又会如何?本文基于 CANNBot + DeepSeek-V4,以大模型场景中广泛采用的 MXFP8 MatMul + Add 场景为例,端到端自动生成了融合算子工程生成并完成了精度、性能测试。核心成果如下:
30 分钟实现算子生成:基于 Ascend 950 平台并采用 DeepSeek-V4,30分钟完成 MXFP8 MatMul + Add 场景的融合算子代码生成。
精度全部达标:20个用例覆盖各类场景,100% 精度通过。
性能收益显著:相较 MXFP8 MatMul + Add 分离实现的基线,平均加速 24.79%、最高加速 56.60%;在典型 shape 场景 Cube 利用率最高达 98.99%,逼近理论性能极限。
1. 引言
MXFP8(Microscaling FP8) 是 OCP Microscaling 规范定义的一种微缩放浮点格式:元素采用 float8_e4m3fn(E4M3),每 32 个连续元素共享一个 float8_e8m0(E8M0)格式的 power-of-two scale。借助 8 bit 共享指数,每个 block 在动态范围上可达到与 BF16 同量级的水平;相比 FP16 / BF16,可将 GEMM 输入的存储开销压缩约 50% 。
MXFP8 已被以 DeepSeek-V4为代表的前沿大模型在训练与推理中大规模采用(并配套了 DeepGEMM 等开源 GEMM 库);在这些场景中,MXFP8 MatMul 加 Add 融合场景——涵盖 Bias-Add、残差连接、LoRA 路径合并等典型组合,是大模型低精度部署中价值最显著的算子优化方向之一。
本文以 MXFP8 MatMul + Add 融合算子为研究对象,在 Ascend 950 平台,基于 CANNBot + DeepSeek-V4 端到端自动生成完整的算子实现,并通过 20 组覆盖小 / 中 / 大三档的典型用例完成验证:精度 20 / 20 全部通过,性能相对基线平均提升 24.79%、最高提升 56.60%。
2. 实测报告
本节以 20 组覆盖小 / 中 / 大三档的真实 shape 为样本,展示 CANNBot + DeepSeek-V4 自动生成的 MXFP8 MatMul-Add 融合算子在昇腾 Ascend 950 平台上的性能与精度实测结果。
2.1 性能
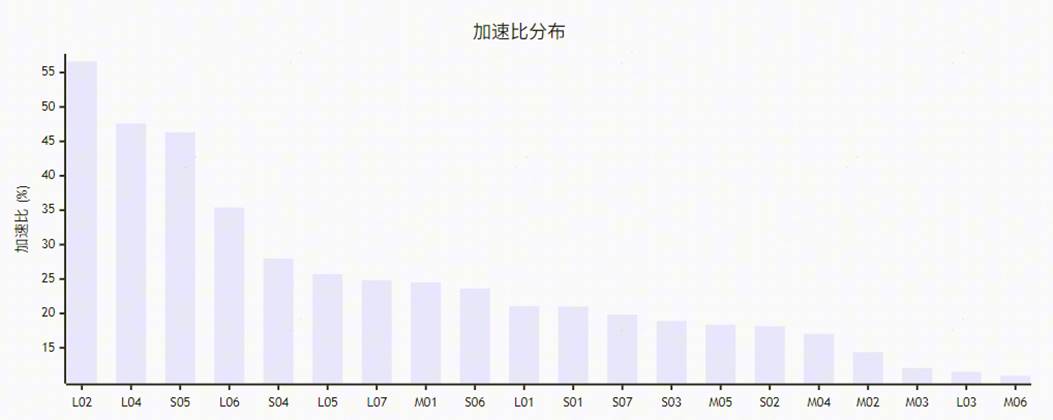
20 组测试用例覆盖如下规模区间,完整性能测试结果见附录 A:
小档(7 组):M、K、N 均在 128 – 256 区间
中档(6 组):M、K、N 均在 512 – 1024 区间
大档(7 组):M、K、N 取值至 4096,覆盖代表性 LLM 推理 / 训练规模
总体统计:
|
指标 |
数值 |
|
测试用例总数 |
20 |
|
平均加速比 |
24.79% |
|
最高加速比 |
56.60%(L02:M = 4096, K = 1024, N = 4096) |
|
融合算子平均Cube利用率(小档位) |
73.26% |
|
融合算子平均Cube利用率(中档位) |
84.66% |
|
融合算子平均Cube利用率(大档位) |
95.24% |
2.2 精度:
|
指标 |
数值 |
|
测试用例总数 |
20 |
|
通过用例数 |
20 |
|
通过率 |
100% |
|
绝对误差容忍阈值 (atol) |
1e-3 |
|
相对误差容忍阈值 (rtol) |
1e-3 |
3. 性能收益分析
3.1 冗余搬运消除
分离实现下,Cube 单元的计算结果需要先写入GM,再由 Vector 单元读取到UB再进行后续计算:

在 Ascend 950 平台,融合算子可采用 L0C → UB 通路,消除了冗余数据搬运:

3.2 CV 流水并行
分离实现下,MatMul 必须完整执行完毕,Add 才能进入计算——Cube 与 Vector 两类计算单元严格串行。
融合算子将 MatMul 与 Add 按照统一的 tile 粒度切分,使 Cube 与 Vector 两侧异步衔接:Cube 完成第 N 个 tile 的 MatMul 后将计算结果搬运至 Vector,并随即开始第 N+1 个 tile 的 MatMul 计算;与此同时,Vector 可同步执行第 N 个 tile的Add运算。Cube 计算与 Vector 计算可以充分并行。
另一方面,基于Ascend 950 的 1 Cube : 2 Vector 硬件配比——可以将一个 Cube 核的计算结果平均分发至两个 Vector 核,充分利用vector核算力并进一步提高CV流水并行程度。
4. CANNBot + DeepSeek-V4 实操开发
4.1 开发过程
CANNBot 是面向 CANN 开发、用于提升工程效率的智能体体系。它以可复用 Skills 为基础,覆盖 Ascend C 算子开发全流程及 NPU 模型推理端到端优化。详情见:https://gitcode.com/cann/cannbot-skills。
本次实操基于 CANNBot 的 ops-direct-invoke 工作流。该工作流支持 OpenCode 与 Claude Code 两种交互前端,初始化命令如下:
git clone https://gitcode.com/cann/cannbot-skills.git
cd cannbot-skills/plugins-official/ops-direct-invoke
bash init.sh project opencode # 或 bash init.sh project claude 进入交互前端后,输入算子规格即可。本次实操使用的需求描述为:
基于 Ascend C 算子直调工作流,开发 mxfp8_matmul_add_fusion_kernel 融合算子:
- 数学公式:C = MatMul((A * scaleA), (B * scaleB)) + D
- 数据类型:A/B 为 MXFP8(fp8_e4m3fn),scaleA/scaleB 为 E8M0,D/C 为 FP32
- 目标平台:Ascend 950
需求由 Architect Subagent 接收并转化为结构化的设计文档,随后 Developer、Reviewer、Tester 等 Subagent 依次承接,直至生成可运行的 Kernel 工程与全套测试报告。整个融合算子的端到端约 30 分钟,开发者仅需在关键节点(设计串讲、代码审查通过)进行确认即可。工作流程如下所示:

生成的融合算子工程目录结构如下:
ops/mxfp8_matmul_add_fusion_kernel/
├── CMakeLists.txt # 构建配置
├── run.sh # 一键执行脚本
├── src/
│ └── matmul_fused_swat.cpp # Host 侧入口
├── include/
│ ├── kernel/
│ │ └── matmul_kernel_fused.h # AIC/AIV 融合 Kernel
│ ├── epilogue/
│ │ └── add_epilogue.h # Add Epilogue 实现
│ ├── tiling/ # Tiling 策略
│ ├── block/ # Block 级调度
│ ├── tile/ # Tile 级数据搬运
│ └── utils/ # 常量与工具函数
├── scripts/
│ ├── gen_data.py # 测试数据生成
│ └── verify_result.py # 精度验证
└── common/ # 公共组件 4.2 站在 cann-samples 的肩膀上
值得注意的是,本次自动生成的融合算子工程并非从零开始,而是充分吸取了现有的高性能算子编码经验:无论是基础的Tensor API使用,还是 tiling / block / tile 的分层抽象组织,其设计思路均参考了 cann-samples 中 MX 量化矩阵乘的优化最佳实践。
cann-samples 是 CANN(Compute Architecture for Neural Networks)官方维护的实操样例仓库,面向昇腾平台开发者提供从基础到进阶的高性能算子实现样例与体系化调优知识库。其中 Samples/2_Performance/matmul_story 由浅入深地呈现了从基础 Matmul 到 MX 量化 Matmul 的完整优化链路,并配套提供《MX 量化矩阵乘算子性能优化指南》等深度调优文档,是希望系统掌握昇腾算子高性能编程的开发者值得深入研读的核心参考资料。仓库地址:https://gitcode.com/cann/cann-samples。
CANNBot 的工程价值体现在两个层面:一是将原本散落于样例与文档中的高性能编程经验系统化、可复用化,使Agent能够稳定生成高质量的算子工程基线;二是为算子开发者与算法研究者提供可灵活组合与扩展的高性能实现单元,使其能够在已有工程沉淀的基础上快速搭建满足业务需求的定制化算子,将新算子从算法构想到可用版本的开发周期由周级压缩至小时级。
5. 结论与展望
本次实操交付的融合算子在自动化、精度、性能三个维度均达到生产可用标准:
1. 工程自动化:从自然语言需求到可编译可运行的 Ascend C 工程,CANNBot 全流程覆盖 Host 侧内存管理、Tiling 策略、Cube / Vector 协同 Kernel 与 Epilogue 实现,无需人工介入底层模板代码。
2. 数值正确性:20 组测试用例全部精度达标。
3. 性能收益:相较 MatMul + Add 分离实现的基线,平均加速 24.79%、最高 56.60%(L02:4096×1024×4096);融合 Kernel 在大档主力 shape 上 Cube 利用率稳定 ≥ 91%(最高 98.99%,L06),逼近硬件理论极限。
展望:
1、泛化融合场景生成能力:当前的算子生成方式是基于cann-samples仓中已有的高性能实现做有限的扩展及开发,仅局限于固定的Matmul + ElementWise 组合场景,不具备泛化融合场景的算子生成能力。下一步将继续扩展融合算子的开发场景,为开发者提供自定义融合算子的代码生成能力。
2、性能调优能力闭环:进一步提升性能调优能力,自动识别 CV 流水匹配度、Tiling 选择空间等瓶颈点,使生成的融合算子在泛化场景更加接近理论性能极限。
附录 A:完整测试结果表格
下表给出 20 组 shape 的完整测试结果。
|
用例 |
档位 |
M |
K |
N |
单 MatMul (μs) |
单 Add (μs) |
基线 (μs) |
融合 (μs) |
Cube 利用率 |
精度 |
加速比 |
|
S01 |
小 |
128 |
128 |
128 |
6.32 |
2.72 |
9.05 |
7.15 |
73.38% |
PASS |
20.99% |
|
S02 |
小 |
128 |
256 |
128 |
6.94 |
2.73 |
9.67 |
7.92 |
71.33% |
PASS |
18.13% |
|
S03 |
小 |
256 |
128 |
256 |
5.89 |
2.76 |
8.65 |
7.01 |
75.61% |
PASS |
18.90% |
|
S04 |
小 |
256 |
256 |
256 |
6.71 |
2.95 |
9.66 |
6.96 |
75.56% |
PASS |
27.98% |
|
S05 |
小 |
128 |
256 |
256 |
11.11 |
2.67 |
13.78 |
7.39 |
72.00% |
PASS |
46.33% |
|
S06 |
小 |
256 |
128 |
128 |
6.65 |
2.90 |
9.55 |
7.29 |
71.73% |
PASS |
23.62% |
|
S07 |
小 |
256 |
256 |
128 |
6.45 |
2.98 |
9.43 |
7.56 |
73.19% |
PASS |
19.84% |
|
M01 |
中 |
512 |
512 |
512 |
7.98 |
3.49 |
11.46 |
8.65 |
80.51% |
PASS |
24.52% |
|
M02 |
中 |
512 |
1024 |
512 |
8.68 |
3.49 |
12.17 |
10.42 |
83.19% |
PASS |
14.38% |
|
M03 |
中 |
1024 |
512 |
1024 |
9.23 |
6.68 |
15.91 |
13.99 |
87.55% |
PASS |
12.07% |
|
M04 |
中 |
1024 |
1024 |
512 |
9.52 |
4.44 |
13.96 |
11.58 |
82.71% |
PASS |
17.04% |
|
M05 |
中 |
512 |
512 |
1024 |
8.04 |
5.04 |
13.08 |
10.68 |
84.28% |
PASS |
18.37% |
|
M06 |
中 |
1024 |
1024 |
1024 |
10.44 |
6.62 |
17.06 |
15.19 |
89.70% |
PASS |
10.95% |
|
L01 |
大 |
2048 |
2048 |
2048 |
29.95 |
25.27 |
55.22 |
43.59 |
96.55% |
PASS |
21.06% |
|
L02 |
大 |
4096 |
1024 |
4096 |
55.46 |
157.73 |
213.19 |
92.52 |
96.52% |
PASS |
56.60% |
|
L03 |
大 |
1024 |
4096 |
1024 |
20.47 |
6.76 |
27.23 |
24.09 |
91.42% |
PASS |
11.52% |
|
L04 |
大 |
4096 |
2048 |
4096 |
95.47 |
157.05 |
252.52 |
132.35 |
98.29% |
PASS |
47.59% |
|
L05 |
大 |
2048 |
512 |
2048 |
14.17 |
21.39 |
35.56 |
26.42 |
92.60% |
PASS |
25.71% |
|
L06 |
大 |
4096 |
4096 |
4096 |
176.56 |
156.11 |
332.67 |
214.98 |
98.99% |
PASS |
35.38% |
|
L07 |
大 |
2048 |
1024 |
2048 |
19.76 |
21.71 |
41.46 |
31.16 |
92.34% |
PASS |
24.84% |
参考文献
[1] B. Rouhani et al., "Microscaling Data Formats for Deep Learning," arXiv:2310.10537, 2023. [arXiv]; OCP, "Microscaling Formats (MX) Specification v1.0," Open Compute Project, 2023. [规范]
[2] DeepSeek-AI, "DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence," Technical Report, 2025.
[3] DeepSeek-AI, "DeepGEMM: Clean and Efficient FP8 GEMM Kernels with Fine-Grained Scaling," 2025. [GitHub]

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 0
0 0
0- 0



 已为社区贡献208条内容
已为社区贡献208条内容

所有评论(0)