Ascend C 调试技巧大全 - 从Printf到Profiler的完整问题定位流程
本文系统介绍了AscendC算子开发的调试技术体系。首先阐述了AscendC调试面临的三大挑战:环境隔离、数据不可见和时序敏感性,提出孪生调试体系作为解决方案。详细讲解了从基础调试技巧(Printf/GDB)到高级技术(DumpTensor/msprof)的全套方法,并针对内存问题和性能优化给出了具体实践。通过4个实战案例展示了复杂问题的调试流程,包括精度误差和多核死锁的定位解决。最后总结了调试效
目录
摘要
本文系统梳理Ascend C算子开发全链路调试技术,从孪生调试体系原理切入,深入解析Printf日志法、GDB调试器、DumpTensor数据导出等基础技术,进阶到msprof性能分析器和高级动态形状调试。通过4个实战案例和5+可视化流程图,展示如何精准定位内存泄漏、数据越界、流水线停顿等复杂问题,提供一套企业级调试方法论,显著提升算子开发效率。
1 引言:为什么Ascend C调试需要专属方法论?
在我多年的异构计算开发生涯中,见证过太多开发者"功能调试靠猜,性能优化靠试"的困境。与通用CPU编程不同,Ascend C面临异构架构(Host+Device)、多层次存储(Global Memory/Unified Buffer/Register)和并行执行模型带来的独特调试挑战。传统调试手段在此场景下往往力不从心。
根据官方统计,Ascend C开发者平均花费60%-70%的时间在调试上,其中超过一半的问题与内存管理和并行同步相关。更严峻的是,近40%的性能问题在仿真环境中难以复现,必须通过上板调试才能定位。
针对这一现状,我总结出Ascend C调试的三大核心挑战:
-
环境隔离:Host与Device代码执行环境完全隔离,无法直接断点调试核函数
-
数据不可见:Device侧内存和寄存器状态对开发者透明,异常定位困难
-
时序敏感性:并行流水线问题具有高度时序敏感性,简单日志可能破坏问题现场
下面流程图展示了Ascend C调试的完整决策体系,本文将依此展开:
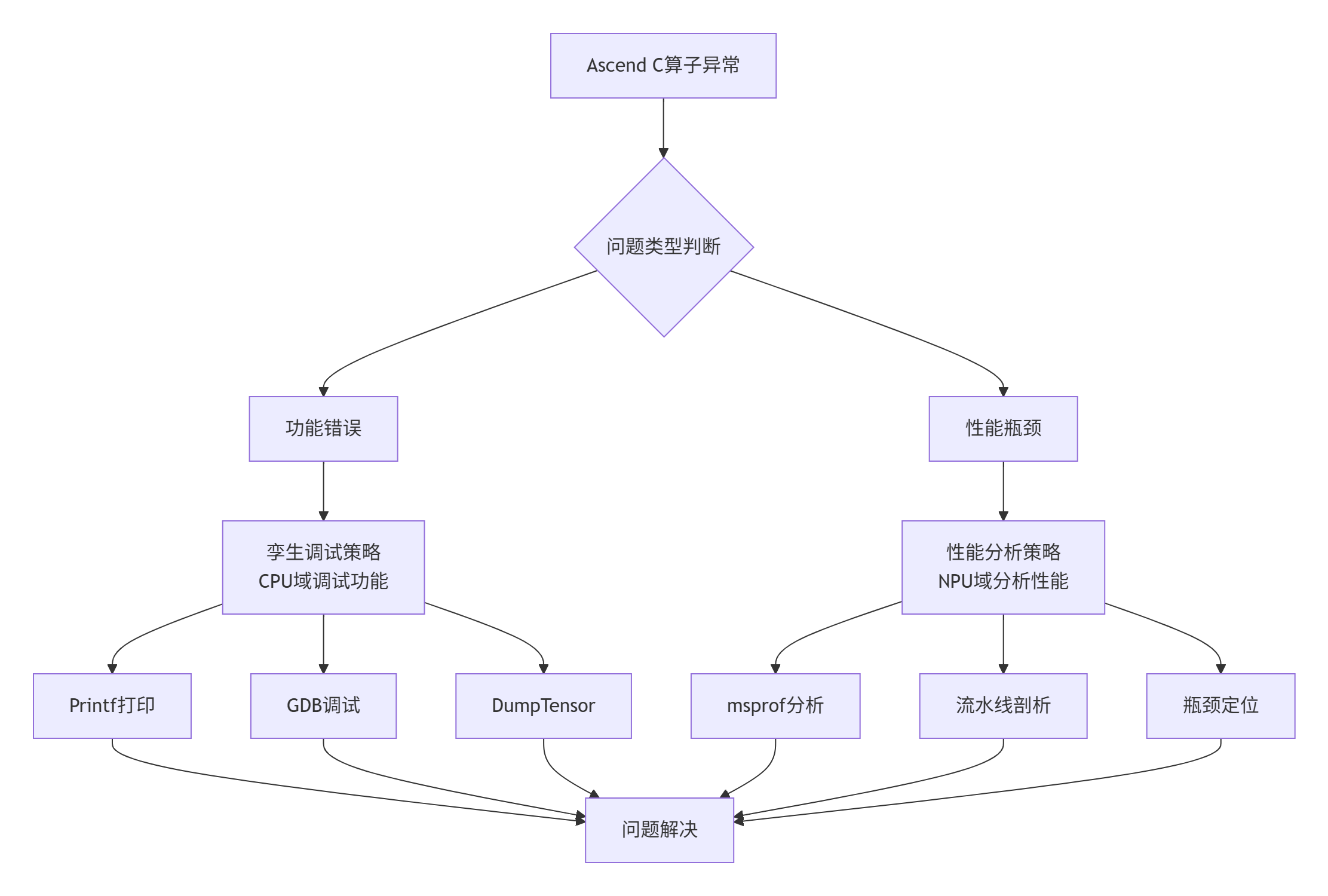
图1-1:Ascend C调试决策流程图
2 Ascend C孪生调试体系深度解析
2.1 孪生调试原理与架构优势
Ascend C的孪生调试(Twin Debugging)是其最具特色的调试能力,允许同一份算子代码在CPU域和NPU域无缝切换调试环境。其核心架构如下:
// 孪生调试的编译条件示例
#ifdef __CCE_KT_TEST__
// CPU域调试:使用GCC编译,运行在x86 CPU上
#define DEBUG_PRINT(format, ...) printf("[CPU_DBG] " format, ##__VA_ARGS__)
#define DEVICE_ONLY_DEBUG(code) // 在CPU域跳过设备专用代码
#else
// NPU域执行:使用毕昇编译器,运行在AI Core上
#define DEBUG_PRINT(format, ...) PRINTF("[NPU_DBG] " format, ##__VA_ARGS__)
#define DEVICE_ONLY_DEBUG(code) code
#endif
// 同一份代码,两种执行环境
__aicore__ void vector_add_kernel(...) {
DEBUG_PRINT("BlockIdx=%d, TotalLength=%d", GetBlockIdx(), totalLength);
// 设备专用调试代码(仅NPU域执行)
DEVICE_ONLY_DEBUG(
__gm__ half* gm_ptr = reinterpret_cast<__gm__ half*>(global_buffer);
DumpTensor(gm_ptr, 0, 256); // 导出前256个元素
)
}代码清单2-1:孪生调试的条件编译示例
孪生调试的三大优势:
-
调试效率:在CPU域使用标准GDB调试,避免漫长的设备代码上传下载
-
成本控制:CPU调试无需NPU硬件,降低开发门槛
-
问题隔离:通过环境对比,快速定位硬件相关性问题
2.2 多层次调试工具链
Ascend C提供从基础到高级的完整调试工具链,各工具定位如下:
|
调试工具 |
适用场景 |
精度影响 |
性能影响 |
调试粒度 |
|---|---|---|---|---|
|
Printf/PRINTF |
逻辑验证、变量跟踪 |
无影响 |
轻微 |
代码级 |
|
GDB |
复杂逻辑调试、死锁定位 |
无影响 |
中等的 |
指令级 |
|
DumpTensor |
数据精度验证、内存分析 |
可能影响内存布局 |
中等 |
数据级 |
|
msprof |
性能瓶颈分析、流水线优化 |
无影响 |
轻微 |
系统级 |
表2-1:Ascend C调试工具链对比
实际调试中,我推荐采用渐进式调试策略:先用Printf快速定位问题范围,再使用GDB深入分析复杂逻辑,最后用msprof进行性能优化。
3 基础调试技巧:从Printf到GDB
3.1 Printf打印调试实战
Printf是最直接有效的调试手段,但在Ascend C中需要区分执行环境:
// 增强型调试打印宏
#ifdef __CCE_KT_TEST__
#define DEBUG_PRINT(level, format, ...) do { \
if (g_debug_level >= level) { \
printf("[L%d][B%d] " format, level, GetBlockIdx(), ##__VA_ARGS__); \
} \
} while(0)
#else
#define DEBUG_PRINT(level, format, ...) do { \
if (g_debug_level >= level) { \
PRINTF("[L%d][B%d] " format, level, GetBlockIdx(), ##__VA_ARGS__); \
} \
} while(0)
#endif
// 在核函数中的实际应用
__aicore__ void debug_kernel(GM_ADDR input, GM_ADDR output, uint32_t total_length) {
// 级别1:关键参数记录
DEBUG_PRINT(1, "Kernel started. Total length=%u", total_length);
uint32_t block_length = total_length / GetBlockNum();
uint32_t tile_num = 8;
uint32_t tile_length = block_length / tile_num;
// 级别2:详细计算参数
DEBUG_PRINT(2, "BlockLen=%u, TileNum=%u, TileLen=%u",
block_length, tile_num, tile_length);
for (uint32_t i = 0; i < tile_num; ++i) {
// 级别3:循环内部详细跟踪
DEBUG_PRINT(3, "Processing tile %u, offset=%u", i, i * tile_length);
// 实际计算逻辑
process_tile(input + i * tile_length, output + i * tile_length, tile_length);
// 检查计算错误
if (has_calculation_error()) {
DEBUG_PRINT(0, "ERROR: Calculation failed at tile %u", i); // 级别0总是打印
return;
}
}
DEBUG_PRINT(1, "Kernel completed successfully");
}代码清单3-1:分级调试打印实现
打印调试最佳实践:
-
分级控制:通过调试级别控制输出量,避免日志泛滥
-
块标识:包含BlockIdx区分不同AI Core的输出
-
错误优先:错误信息使用最高级别确保可见
-
性能意识:NPU域PRINTF有性能成本,调试后需移除
3.2 GDB调试完整流程
对于复杂逻辑问题,GDB是更强大的调试工具。Ascend C的多核架构需要特殊调试配置:
# 1. 编译带调试信息的可执行文件
ccec -g -O0 kernel.cpp -o kernel_debug
# 2. 启动GDB调试
gdb --args kernel_debug_cpu
# 3. 配置多进程调试环境
(gdb) set detach-on-fork off
(gdb) catch fork
# 4. 设置条件断点(只在特定Block停止)
(gdb) break kernel.cpp:45 if GetBlockIdx() == 2
# 5. 运行并调试
(gdb) run代码清单3-2:GDB调试命令序列
多核调试技巧:
// 在核函数中插入调试检查点
__aicore__ void checked_kernel(...) {
// 只在指定Block停止,避免全暂停
if (GetBlockIdx() == DEBUG_BLOCK_ID) {
// 人工注入的调试点
asm volatile("breakpoint");
}
// 或者使用条件变量控制
volatile int debug_flag = 1;
while (debug_flag && GetBlockIdx() == DEBUG_BLOCK_ID) {
// 在GDB中修改debug_flag=0继续执行
asm volatile("nop");
}
}代码清单3-3:针对性断点设置技巧
常见GDB调试场景:
-
死锁定位:检查各核的调用栈,找到等待资源
-
数据污染:观察特定内存地址的异常修改
-
条件断点:只在异常条件下触发断点
4 数据导出与内存调试技术
4.1 DumpTensor数据导出实战
当算子结果异常但原因不明时,DumpTensor提供了数据级洞察能力:
// 完整的数据导出实现
class TensorDumper {
private:
uint32_t dump_count_;
public:
__aicore__ void DumpTensorFull(const char* name, LocalTensor<half> tensor,
uint32_t length, uint32_t line_num) {
// 添加调试信息头
PRINTF("=== DUMP %s (line %d, count %d) ===", name, line_num, dump_count_);
PRINTF("Address: %p, Length: %u, Block: %d",
tensor.GetPointer(), length, GetBlockIdx());
// 分块导出避免打印过多
const uint32_t chunk_size = 16;
for (uint32_t i = 0; i < length; i += chunk_size) {
uint32_t print_len = min(chunk_size, length - i);
PRINTF("Values[%u:%u]: ", i, i + print_len - 1);
// 分批打印实际数值
for (uint32_t j = 0; j < print_len; ++j) {
PRINTF("%.6f ", static_cast<float>(tensor[i + j]));
}
}
++dump_count_;
}
};
// 在算子中的使用示例
__aicore__ void kernel_with_dump(...) {
TensorDumper dumper;
LocalTensor<half> input_tensor = inQueue.DeQue<half>();
// 导出输入数据
dumper.DumpTensorFull("Input", input_tensor, 256, __LINE__);
// 计算过程
LocalTensor<half> output_tensor = outQueue.AllocTensor<half>();
Compute(output_tensor, input_tensor, 256);
// 导出结果数据
dumper.DumpTensorFull("Output", output_tensor, 256, __LINE__);
outQueue.EnQue(output_tensor);
inQueue.FreeTensor(input_tensor);
}代码清单4-1:增强型Tensor导出实现
DumpTensor优化技巧:
-
条件导出:基于BlockIdx或数据值条件触发,避免全量导出
-
抽样导出:每隔N次迭代导出一次,平衡信息量与性能
-
差异对比:只导出发生变化的数据区域
4.2 内存问题定位技巧
内存问题是Ascend C开发中最常见的问题类型,以下是系统化的定位方法:
// 内存安全检查器
class MemoryChecker {
public:
__aicore__ bool CheckBufferAlignment(LocalTensor<half> tensor, uint32_t alignment) {
uint64_t addr = reinterpret_cast<uint64_t>(tensor.GetPointer());
bool aligned = (addr % alignment == 0);
if (!aligned) {
PRINTF("MEM_ERR: Tensor at %p not %u-byte aligned",
tensor.GetPointer(), alignment);
}
return aligned;
}
__aicore__ bool CheckBufferOverflow(LocalTensor<half> tensor, uint32_t declared_size,
uint32_t actual_usage) {
if (actual_usage > declared_size) {
PRINTF("MEM_ERR: Buffer overflow detected. Declared: %u, Used: %u",
declared_size, actual_usage);
return false;
}
return true;
}
__aicore__ void CheckMemoryPattern(LocalTensor<half> tensor, uint32_t length) {
// 检查内存模式,识别未初始化内存
bool has_nan = false;
for (uint32_t i = 0; i < length; ++i) {
if (isnan(static_cast<float>(tensor[i]))) {
has_nan = true;
PRINTF("MEM_ERR: NaN detected at index %u", i);
break;
}
}
if (has_nan) {
PRINTF("MEM_WARN: Tensor may contain uninitialized memory");
}
}
};
// 在核函数中集成内存检查
__aicore__ void safe_kernel(...) {
MemoryChecker mem_check;
LocalTensor<half> buffer = inQueue.AllocTensor<half>();
// 执行内存安全检查
if (!mem_check.CheckBufferAlignment(buffer, 32)) {
return; // 对齐错误,直接返回
}
uint32_t data_length = 256;
if (!mem_check.CheckBufferOverflow(buffer, buffer.GetSize(), data_length)) {
return; // 溢出风险,直接返回
}
mem_check.CheckMemoryPattern(buffer, data_length);
// 安全的内存操作
process_data(buffer, data_length);
}代码清单4-2:内存安全检查工具类
5 性能分析与优化调试
5.1 msprof性能分析实战
msprof是Ascend C性能分析的核心工具,提供从指令级到系统级的全方位性能洞察:
# 基础性能数据收集
msprof --application="./custom_operator" --output=./profile_data
# 详细AI Core指标分析
msprof --application="./custom_operator" --ai-core=on --aic-metrics=all
# 特定指标聚焦分析
msprof --application="./custom_operator" --ai-core=on --aic-metrics="PipeUtilization,VectorUsage"
# 生成可视化报告
msprof --export=profile_data --output=report.html代码清单5-1:msprof常用分析命令
关键性能指标解读:
-
PipeUtilization:流水线利用率,理想值>85%,过低表明计算搬运不均衡
-
VectorUsage:向量单元利用率,衡量计算密度
-
MemoryBandwidth:内存带宽使用率,识别内存瓶颈
-
CacheHitRate:缓存命中率,指导数据布局优化
5.2 流水线性能分析
通过msprof可以可视化分析流水线执行情况,识别性能瓶颈:
图5-1:流水线性能对比分析图
流水线优化策略:
-
计算密集型:Compute时间显著长于CopyIn/Out,优化重点在算法向量化
-
搬运密集型:Copy时间占主导,需要优化数据布局或使用Double Buffer
-
均衡型:各阶段时间接近,需微调分块策略实现更好重叠
6 高级调试技巧与企业级实践
6.1 动态形状算子调试
动态形状算子调试复杂度显著高于固定形状,需要特殊调试策略:
// 动态形状调试增强实现
class DynamicShapeDebugger {
private:
#ifdef __CCE_KT_TEST__
std::map<std::string, std::vector<float>> cpu_debug_data_;
#else
uint32_t npu_debug_buffer_[DEBUG_BUFFER_SIZE];
#endif
public:
__aicore__ void ValidateDynamicTiling(DynamicTilingData tiling) {
// 验证动态分块参数合理性
bool valid = true;
if (tiling.total_length == 0) {
PRINTF("DYNAMIC_ERR: Total length is zero");
valid = false;
}
if (tiling.tile_size % 32 != 0) {
PRINTF("DYNAMIC_WARN: Tile size %u not 32-byte aligned", tiling.tile_size);
// 继续执行但标记警告
}
uint32_t expected_tiles = (tiling.total_length + tiling.tile_size - 1) / tiling.tile_size;
if (expected_tiles > MAX_TILES) {
PRINTF("DYNAMIC_ERR: Too many tiles %u, max supported %u",
expected_tiles, MAX_TILES);
valid = false;
}
if (!valid) {
PRINTF("DYNAMIC_ERR: Invalid tiling data. Aborting kernel.");
return; // 参数错误直接返回
}
}
__aicore__ void AdaptToDynamicShape(LocalTensor<half> tensor, uint32_t actual_size) {
// 动态形状适配调试
uint32_t allocated_size = tensor.GetSize();
if (actual_size > allocated_size) {
PRINTF("DYNAMIC_ERR: Actual size %u exceeds allocation %u",
actual_size, allocated_size);
// 动态调整或安全处理
handle_overflow_safely(tensor, actual_size);
} else if (actual_size < allocated_size) {
PRINTF("DYNAMIC_INFO: Underutilized allocation: %u of %u",
actual_size, allocated_size);
}
}
};代码清单6-1:动态形状调试工具
6.2 企业级调试工作流
在大规模项目中,需要建立系统化的调试流程:
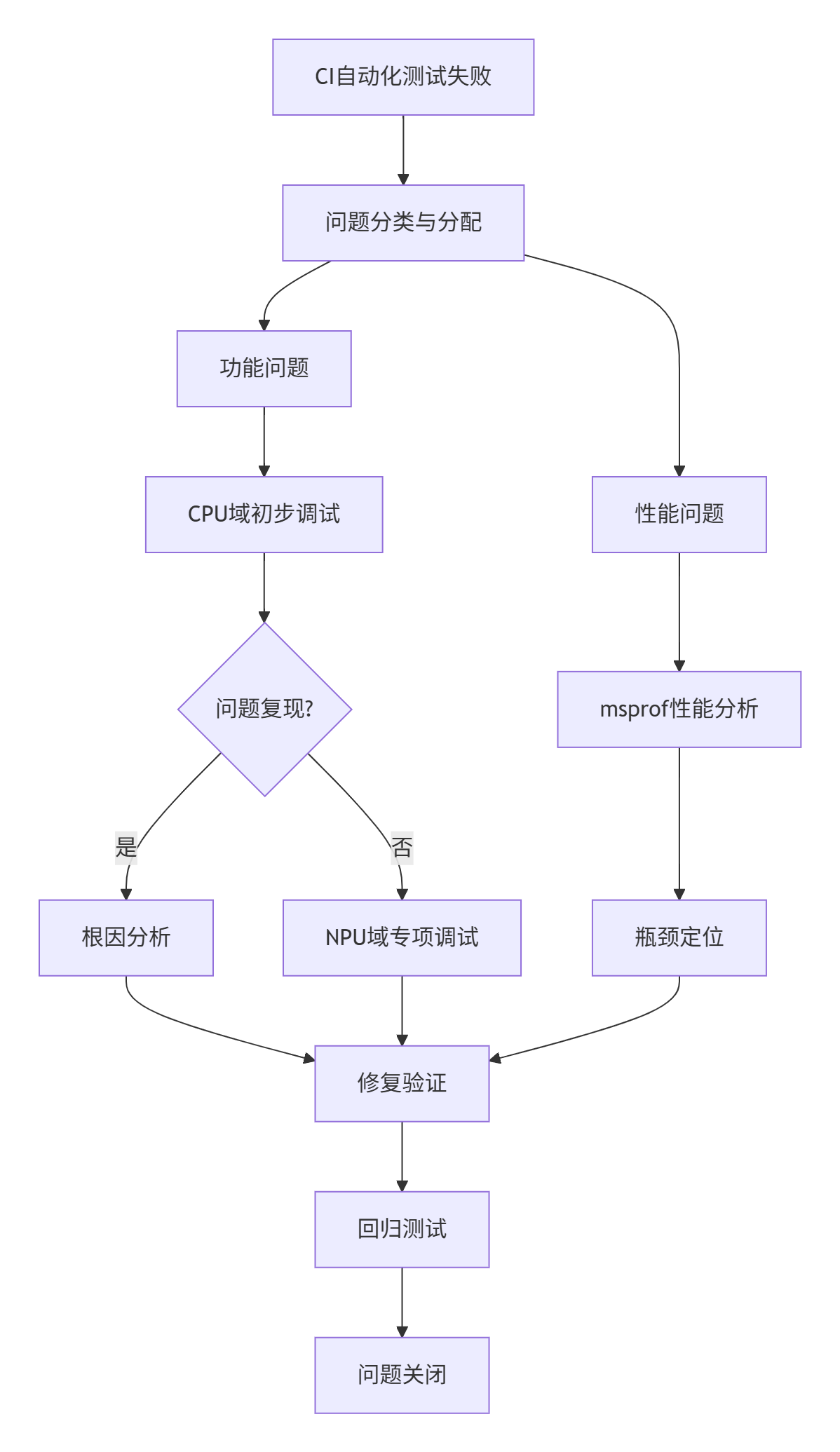
图6-1:企业级调试工作流
调试流程关键节点:
-
自动化检测:CI系统中集成基础检查(内存泄漏、精度误差)
-
问题分类:根据错误特征快速路由到相应专家
-
环境隔离:建立专用调试环境,避免资源竞争
-
知识沉淀:将解决方案归档形成组织知识库
7 实战案例:复杂问题调试全流程
7.1 案例一:间歇性精度误差调试
问题现象:大型矩阵乘法在特定形状下出现间歇性精度误差,误差率约0.1%。
调试过程:
// 精度调试专项检查
class PrecisionDebugger {
public:
__aicore__ void ComparePrecision(LocalTensor<half> actual, LocalTensor<half> expected,
uint32_t length, float threshold) {
uint32_t error_count = 0;
float max_error = 0.0f;
uint32_t max_error_index = 0;
for (uint32_t i = 0; i < length; ++i) {
float actual_fp32 = static_cast<float>(actual[i]);
float expected_fp32 = static_cast<float>(expected[i]);
float error = fabs(actual_fp32 - expected_fp32);
if (error > threshold) {
++error_count;
if (error > max_error) {
max_error = error;
max_error_index = i;
}
}
}
if (error_count > 0) {
PRINTF("PRECISION_ERR: %u errors, max error %.6f at index %u",
error_count, max_error, max_error_index);
// 记录错误上下文用于分析
LogErrorContext(actual, expected, max_error_index);
}
}
private:
__aicore__ void LogErrorContext(LocalTensor<half> actual, LocalTensor<half> expected,
uint32_t error_index) {
// 记录错误点周围数据
uint32_t start = (error_index >= 5) ? error_index - 5 : 0;
uint32_t end = min(error_index + 5, actual.GetSize() - 1);
PRINTF("Error context at index %u:", error_index);
for (uint32_t i = start; i <= end; ++i) {
PRINTF("[%u] Actual: %.6f, Expected: %.6f, Diff: %.6f", i,
static_cast<float>(actual[i]),
static_cast<float>(expected[i]),
fabs(static_cast<float>(actual[i] - expected[i])));
}
}
};代码清单7-1:精度误差调试工具
根本原因:发现是累加顺序导致的FP16精度损失,通过Kahan求和算法解决。
7.2 案例二:多核同步死锁调试
问题现象:16核并行算子随机性卡死,无错误信息输出。
调试方案:
# 多核死锁调试命令序列
gdb --args deadlock_demo_cpu
set detach-on-fork off
catch fork
break sync_point.cpp:45 if GetBlockIdx() == 0
break sync_point.cpp:45 if GetBlockIdx() == 1
# ... 为所有Block设置断点
run
info inferiors
# 切换不同进程检查状态代码清单7-2:死锁调试GDB配置
解决方案:发现是核间屏障同步条件竞争,通过调整同步策略解决。
8 调试技巧总结与最佳实践
8.1 调试效率提升秘籍
根据多年经验,我总结出以下调试效率提升策略:
-
预防优于调试
// 防御性编程示例 #ifdef DEBUG #define ASSERT_VALID_TENSOR(tensor, length) do { \ if (tensor.GetPointer() == nullptr) { \ PRINTF("ASSERT_FAIL: Null tensor at %s:%d", __FILE__, __LINE__); \ return; \ } \ if (length == 0 || length > MAX_ALLOWED_LENGTH) { \ PRINTF("ASSERT_FAIL: Invalid length %u at %s:%d", length, __FILE__, __LINE__); \ return; \ } \ } while(0) #else #define ASSERT_VALID_TENSOR(tensor, length) // Release模式为空 #endif代码清单8-1:防御性编程检查宏
-
工具链熟练度
-
掌握msprof高级过滤技巧,聚焦关键路径
-
学习GDB条件断点和观察点快速定位变量异常
-
使用自定义DumpTensor减少调试迭代次数
-
-
团队知识共享
-
建立常见问题模式库
-
制定调试检查清单(Checklist)
-
定期组织调试经验分享会
-
8.2 调试检查清单
在交付算子前,请逐一验证以下项目:
-
[ ] 功能正确性
-
[ ] CPU/NPU双域结果一致
-
[ ] 边界条件处理正确(零元素、对齐不足等)
-
[ ] 异常路径资源释放完整
-
-
[ ] 性能达标
-
[ ] 计算利用率 > 80%
-
[ ] 内存带宽利用率合理
-
[ ] 无明显的流水线气泡
-
-
[ ] 稳定性
-
[ ] 长稳测试(24h+)无内存泄漏
-
[ ] 压力测试下无死锁/数据竞争
-
[ ] 反复启停无资源累积
-
9 未来展望:智能化调试技术
随着AI技术发展,调试技术也在向智能化方向发展:
-
AI辅助根因分析:通过机器学习自动分析日志模式,推荐可能原因
-
预测性调试:基于代码特征预测潜在问题点
-
可视化调试:3D可视化数据流和执行状态
Ascend C调试技术正从"艺术"走向"科学",通过系统化方法论和先进工具链,显著提升算子开发效率和质量。
参考链接
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 8
8 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)