《Ascend C 算子开发精要:内存管理、并行优化与性能工程实践》
Ascend C 算子开发入门:从基础到实战一、Ascend C 核心概念CANNPATHbinCANNPATHlib64// 核函数:执行张量加法(运行于NPU)extern “C”// 获取当前线程在NPU网格中的全局ID(用于定位数据索引)// 避免线程索引超出数据范围// 算子执行函数:封装核函数调用逻辑// 1. 获取张量数据指针(NPU设备端地址)2. 算子接口封装(add_op.
Ascend C 算子开发入门:从基础到实战
一、Ascend C 核心概念
- 什么是 Ascend C?
Ascend C 是华为昇腾 AI 芯片的算子开发编程语言,基于 C/C++ 扩展,专为昇腾 NPU(神经网络处理单元)的异构计算场景设计,支持算子的高效编程、编译优化与部署,是实现自定义 AI 算子的核心工具。 - 核心优势
硬件亲和性:深度适配昇腾 NPU 的张量计算单元(TCU)、向量计算单元(VCU)等硬件资源,发挥硬件极致性能。
开发高效性:兼容 C/C++ 语法,提供丰富的算子开发库(如aclop接口、数学计算库),降低自定义算子开发门槛。
全流程支持:从算子代码编写、编译、调试到部署,提供完整的工具链(昇腾 CANN toolkit)支持。 - 关键术语
算子(Operator):AI 计算的基本单元(如卷积、矩阵乘法、激活函数),是模型推理 / 训练的核心执行模块。
核函数(Kernel):算子在 NPU 上的具体执行代码,由 Ascend C 编写,运行于 NPU 硬件核心。
张量(Tensor):数据的存储载体,Ascend C 支持__half(FP16)、float(FP32)、int32等常用数据类型。
CANN Toolkit:昇腾 AI 异构计算架构的开发工具包,包含编译器、调试器、性能分析工具等,是 Ascend C 开发的基础环境。
二、开发环境搭建 - 环境要求
操作系统:Ubuntu 18.04/20.04(推荐)、CentOS 7.6+
硬件:昇腾 310/910 系列 NPU(或使用昇腾云服务器)
软件依赖:CANN Toolkit 6.0+、GCC 7.3+、CMake 3.10+ - 核心步骤
安装昇腾 NPU 驱动(参考华为昇腾官方文档)。
安装 CANN Toolkit,配置环境变量:
、输入输出张量形状 / 数据类型、性能指标。
核函数编写:用 Ascend C 语法编写算子的 NPU 执行代码(核心步骤)。
2.算子接口封装:通过aclop接口封装核函数,定义算子的输入输出描述、属性等。
3.编译构建:使用 CMake+GCC 编译算子代码,生成动态链接库(.so文件)。
4.调试与测试:通过acl_debug工具调试算子,验证功能正确性(如与 CPU 结果对比)。
性能优化:利用 CANN 性能分析工具(如npu_prof)定位瓶颈,优化代码(如循环展开、数据分块)。
四、入门例题讲解
例题 1:简单张量加法算子(基础入门)
需求描述
实现两个 1 维张量的元素 - wise 加法,输入张量a和b为 FP32 类型,输出张量c = a + b。
6. 核函数编写(add_kernel.cpp)

7. 算子接口封装(add_op.cpp)

3. CMake 构建脚本(CMakeLists.txt)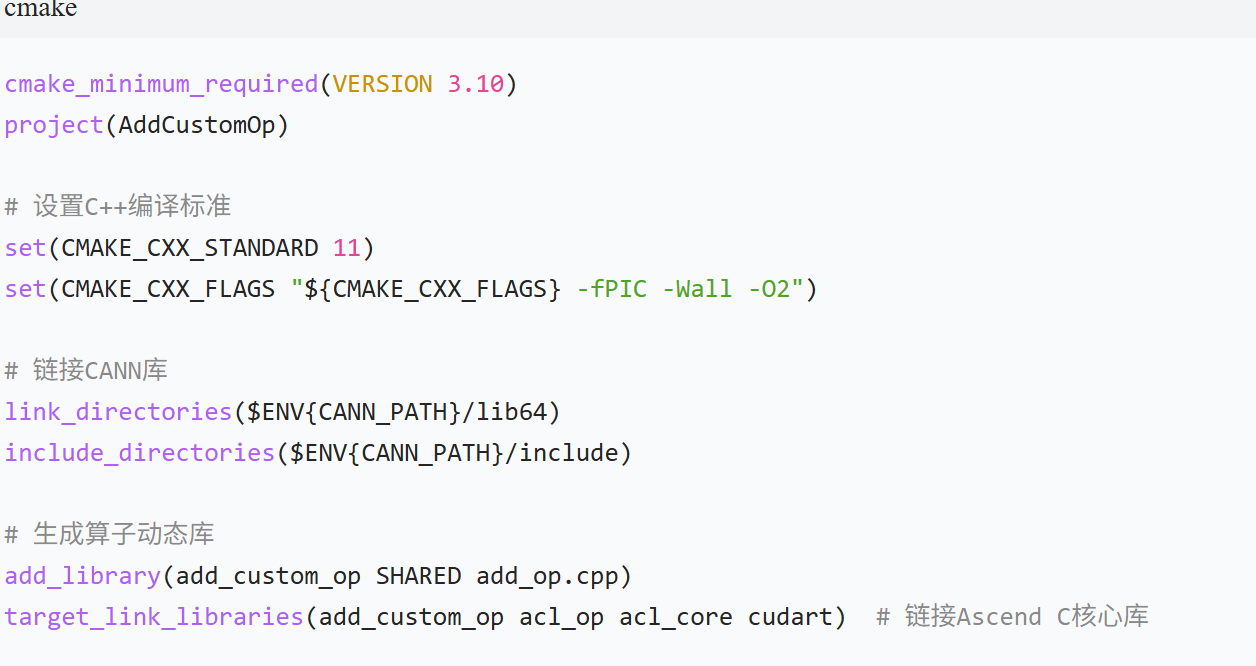
. 编译与运行
编译命令:
bash
mkdir build && cd build
cmake …
make -j4
生成libadd_custom_op.so动态库。
测试代码(test_add_op.cpp):
cpp
#include “acl/acl.h”
#include
#include
int main() {
// 1. 初始化ACL环境
aclError ret = aclInit(nullptr);
if (ret != ACL_SUCCESS) {
std::cerr << “ACL init failed” << std::endl;
return -1;
}
// 2. 注册自定义算子
ret = RegisterAddOp();
if (ret != ACL_SUCCESS) {
std::cerr << "Register op failed" << std::endl;
return -1;
}
// 3. 构造输入输出数据(CPU端)
int size = 1024;
std::vector<float> a(size, 1.0f); // 输入a:全1
std::vector<float> b(size, 2.0f); // 输入b:全2
std::vector<float> c(size, 0.0f); // 输出c:初始化0
// 4. 创建ACL张量(绑定CPU数据,自动拷贝到NPU)
aclTensor* aTensor = aclCreateTensor(ACL_FLOAT, 1, &size, ACL_FORMAT_ND, a.data());
aclTensor* bTensor = aclCreateTensor(ACL_FLOAT, 1, &size, ACL_FORMAT_ND, b.data());
aclTensor* cTensor = aclCreateTensor(ACL_FLOAT, 1, &size, ACL_FORMAT_ND, c.data());
// 5. 执行自定义算子
ret = aclopExecute("AddCustom", 2, &aTensor, 1, &cTensor, nullptr, 0, nullptr, nullptr);
if (ret != ACL_SUCCESS) {
std::cerr << "Op execute failed" << std::endl;
return -1;
}
// 6. 拷贝NPU结果到CPU并验证
aclSyncTensorMem(cTensor, ACL_MEMCPY_DEVICE_TO_HOST);
bool success = true;
for (int i = 0; i < size; i++) {
if (std::abs(c[i] - 3.0f) > 1e-6) {
success = false;
break;
}
}
std::cout << (success ? "Test pass!" : "Test failed!") << std::endl;
// 7. 释放资源
aclDestroyTensor(aTensor);
aclDestroyTensor(bTensor);
aclDestroyTensor(cTensor);
UnregisterAddOp();
aclFinalize();
return 0;
}
编译测试代码:
bash
g++ test_add_op.cpp -o test_add -L./build -ladd_custom_op -IENVCANNPATH/include−LENV{CANN_PATH}/include -LENVCANNPATH/include−LENV{CANN_PATH}/lib64 -lacl_op -lacl_core
运行测试:
bash
./test_add
输出Test pass!表示算子功能正常。
例题 2:矩阵乘法算子(进阶)
需求描述
实现 2 维矩阵乘法:C = A * B,其中A为M×K矩阵,B为K×N矩阵,C为M×N矩阵,数据类型为 FP16(昇腾 NPU 高效支持的张量类型)。
核函数核心代码(matmul_kernel.cpp)
cpp
#include “acl/acl.h”
#include <half/half.hpp> // FP16数据类型支持
using half_float::half;
// 矩阵乘法核函数(优化:使用线程块级数据共享)
extern “C” global void matmul_kernel(const half* A, const half* B, half* C, int M, int K, int N) {
// 线程块内共享内存(存储A的子块和B的子块,减少全局内存访问)
shared half A_shared[16][16]; // 16×16子块(适配NPU硬件缓存)
shared half B_shared[16][16];
// 获取当前线程负责的C矩阵元素坐标 (row, col)
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
half sum = 0.0_h; // 累加结果(FP16类型)
// 分块计算:将K维分成多个16的块(块大小=线程块大小)
for (int k = 0; k < K; k += 16) {
// 加载A的子块到共享内存
if (row < M && (k + threadIdx.x) < K) {
A_shared[threadIdx.y][threadIdx.x] = A[row * K + k + threadIdx.x];
} else {
A_shared[threadIdx.y][threadIdx.x] = 0.0_h;
}
// 加载B的子块到共享内存
if (col < N && (k + threadIdx.y) < K) {
B_shared[threadIdx.y][threadIdx.x] = B[(k + threadIdx.y) * N + col];
} else {
B_shared[threadIdx.y][threadIdx.x] = 0.0_h;
}
// 等待所有线程加载完成(共享内存同步)
__syncthreads();
// 计算当前子块的内积
for (int t = 0; t < 16; t++) {
sum += A_shared[threadIdx.y][t] * B_shared[t][threadIdx.x];
}
// 等待当前子块计算完成
__syncthreads();
}
// 写入结果到C矩阵
if (row < M && col < N) {
C[row * N + col] = sum;
}
}

关键优化点
共享内存:使用__shared__关键字分配线程块级共享内存,减少全局内存访问(NPU 全局内存访问 latency 远高于共享内存)。
分块计算:将大矩阵分成 16×16 的子块(适配昇腾 NPU 的缓存大小),提升数据复用率。
FP16 类型:相比 FP32,FP16 可减少内存带宽占用,提升计算吞吐量(昇腾 NPU 的 TCU 对 FP16 有硬件加速)。
五、常见问题与注意事项
数据类型匹配:确保输入输出张量的数据类型与核函数中的变量类型一致(如 FP16/FP32/int32),否则会导致计算错误。
线程索引越界:核函数中必须判断idx < size或row < M && col < N,避免线程访问超出张量范围的内存。
内存同步:核函数执行后需调用cudaDeviceSynchronize()或aclrtSynchronizeStream(),确保结果写入完成后再读取。
性能优化:
线程块大小建议设置为 32、64、128、256 等 2 的幂(适配 NPU 硬件调度)。
减少全局内存访问,优先使用共享内存和寄存器。
避免核函数中的分支语句(如if-else),若必须使用,尽量让同一线程块内的线程执行相同分支。
性能优化入门建议
在入门阶段,可以开始培养以下性能优化意识:
- 选择合适的数据块大小:BLOCK_SIZE 建议设置为 32、64、128、256 等 2 的幂。这有助于硬件高效调度。
- 减少全局内存访问:尽可能利用UB进行数据复用。例如,在矩阵乘法中,先将数据块加载到UB,再进行计算,可以大幅减少对GM的访问次数。
- 避免分支发散:核函数中应尽量避免复杂的 if-else 分支。如果无法避免,尽量让同一个线程块(Block)内的所有线程执行相同的分支路径,否则会显著降低执行效率。
总结
通过这个简单的 vector_add 算子,我们走完了 Ascend C 算子开发的基本流程:
- 定义核函数原型。
- 使用 Pipe 进行片上内存管理。
- 使用 pipe.copy 进行数据搬运。
- 在UB上进行核心计算。
- 务必进行边界检查。
- 理解主机与设备的同步。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 24
24 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)