面向MoE的Dispatch&Combine算子优化
背景介绍
MoE(Mixture of Experts,专家混合)模型是当前大规模模型提升参数规模与计算效率的重要技术路径,而 Combine 与 Dispatch 则是实现 MoE 路由机制的关键算子。客户在 CANN 开源 Combine 和 Dispatch 算子的基础上进行了进一步优化,显著提升了 MoE 模块的整体性能表现,为业务带来了更高的吞吐能力。
Dispatch&Combine介绍
MoE 模块的核心价值在于通过“稀疏激活”同时提升模型容量与计算效率。与传统前馈网络对所有 token 共享同一组参数不同,MoE 会先通过路由机制为每个 token 选择少量最合适的 expert,使单次计算仅激活部分参数。这样既能显著扩展模型规模、增强表达能力,又能避免全部参数同时参与计算所带来的高额开销。而MoE模块通常分为以下四个阶段:
-
Gating & Routing 阶段:负责完成 expert 选择。Gating 根据输入 token 的隐藏状态,计算其对各个 expert 的适配程度,通常以概率或分数形式表示;Routing 再基于这些结果决定实际激活哪些 expert,例如 Top-K 策略会选择得分最高的 K 个 expert。
-
Dispatch 阶段:负责根据路由结果将 token 分发到对应的 expert,由于专家并行机制expert可能运行在不同Rank上,Dispatch需要在不同Rank间通信传输token。
-
Expert 计算阶段:各个 expert 分别接收属于自己的 token 子集,并执行对应的前向计算,生成中间输出。由于每个 token 只会进入少量 expert,因此这一阶段能够在保持大模型容量的同时有效控制实际计算量。
-
Combine 阶段:负责将各个 expert 的输出结果重新聚合,并恢复为与原始输入一致的 token 顺序;若单个Token选择多个expert,还需要先对多个expert的结果加权合并。
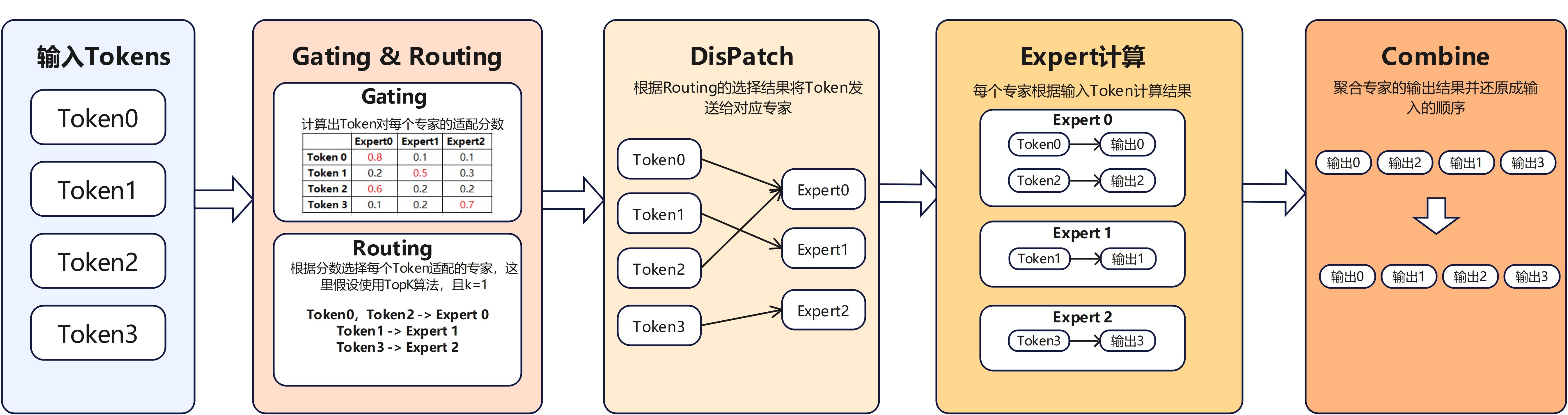
由此,MoE 模块完成了从路由分发到结果恢复的一次完整计算。由于 Dispatch 和 Combine 两个阶段都涉及大量跨 rank 的数据交换与聚合通信,它们往往是影响整个 MoE 模块执行效率和吞吐表现的关键环节。
Dispatch&Combine优化
1 减少冗余传输
在 Routing 阶段,MoE 通常采用 Top-K 策略,即每个 token 会被分配给 K 个 expert。但在实际部署中,这 K 个 expert 可能并不分布在不同的 rank 上,而是有多个 expert 落在同一个 rank。在此场景下,Dispatch和Combine都存在冗余传输以及对应的优化方案:
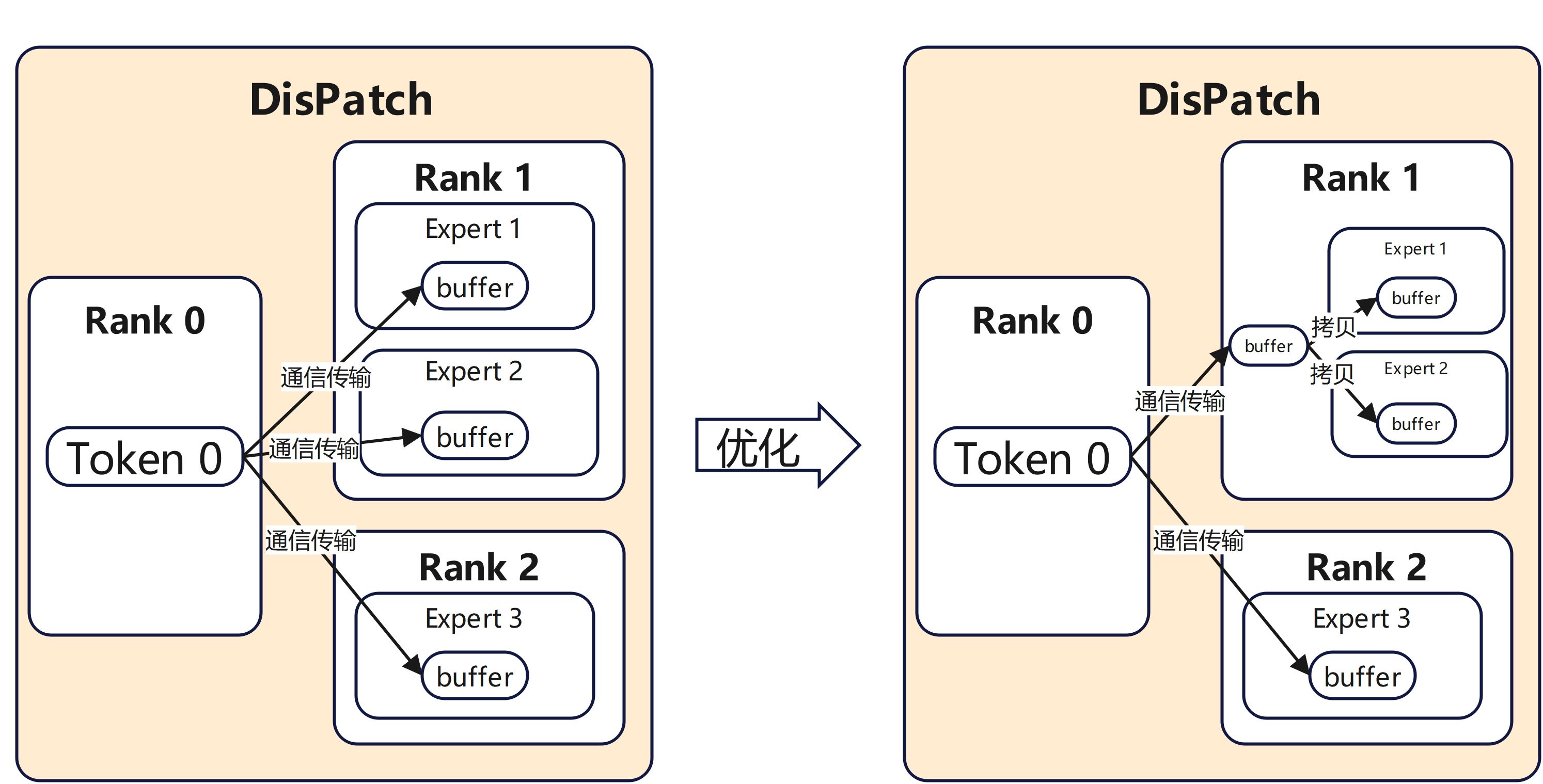
(1) Dispatch
优化前 Dispatch 算子的处理方式是将同一个 token 分别发送到该 rank 上多个 expert 对应的不同 buffer 中。实际上,对于 Dispatch 而言,同一个 token 只需向目标 rank 传输一次,后续可以在 rank 内完成数据分发。由此可得到Dispatch的优化方案:根据 Routing 结果判断一个 token 选择的多个 expert 是否存在落在同一 rank 的情况;如果存在,则只向该 rank 发送一次 token 数据,随后在 rank 内部将其拷贝到各个 expert 对应的输入地址。
(2) Combine
在expert计算完成后,同一rank内会存在属于同一输入的多个expert计算结果,优化前 Combine 算子的处理方式是先将这些 expert 的结果分别传输到目标 rank,再进行加权合并。实际上可以优先在本地完成部分聚合,再进行跨 rank 传输,从而减少不必要的通信量。由此可得到Combine的优化方案:先在本 rank 内对属于同一 token 的多个 expert 输出按权重进行局部合并,再将局部合并后的结果传输到目标 rank,与其他 rank 上传来的结果继续完成后续聚合。通过这种方式,可以有效减少跨 rank 的冗余传输,进而提升 MoE 模块的整体执行效率与吞吐表现。
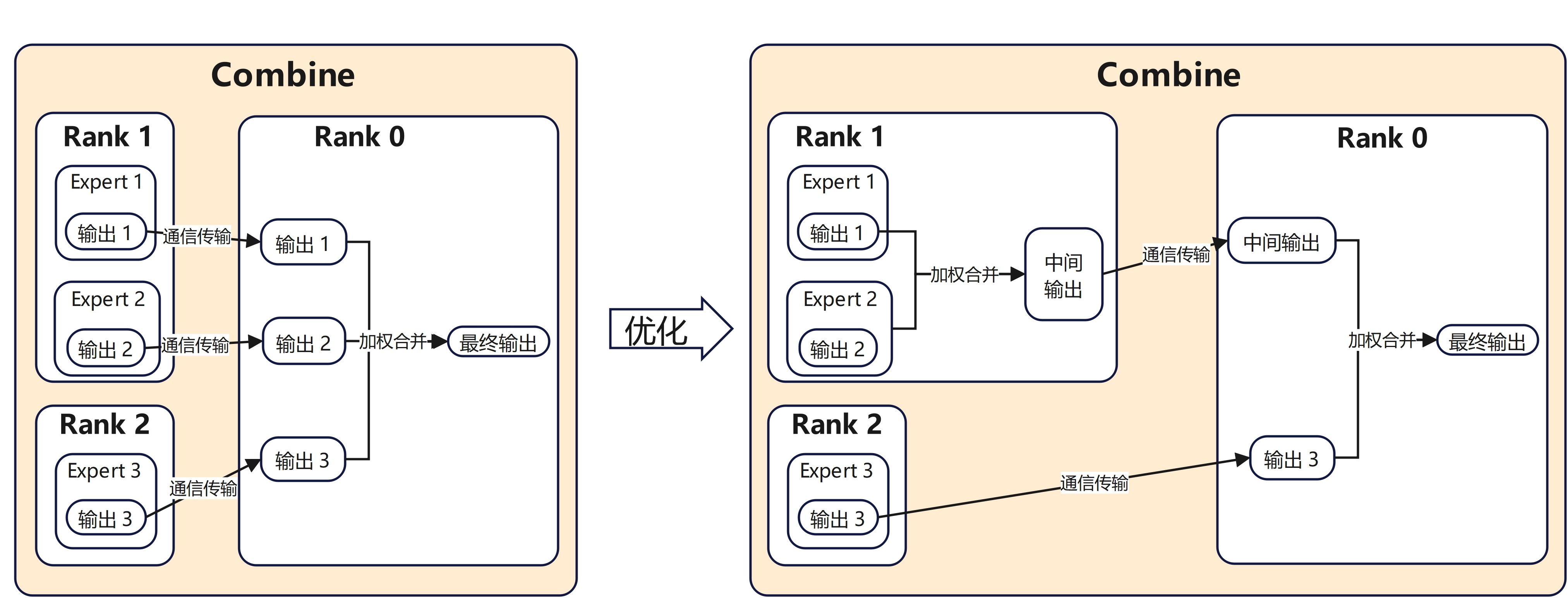
优化后虽然引入了额外的操作,但是关键的性能瓶颈通信传输次数降低,算子整体性能提升.
2 调度优化
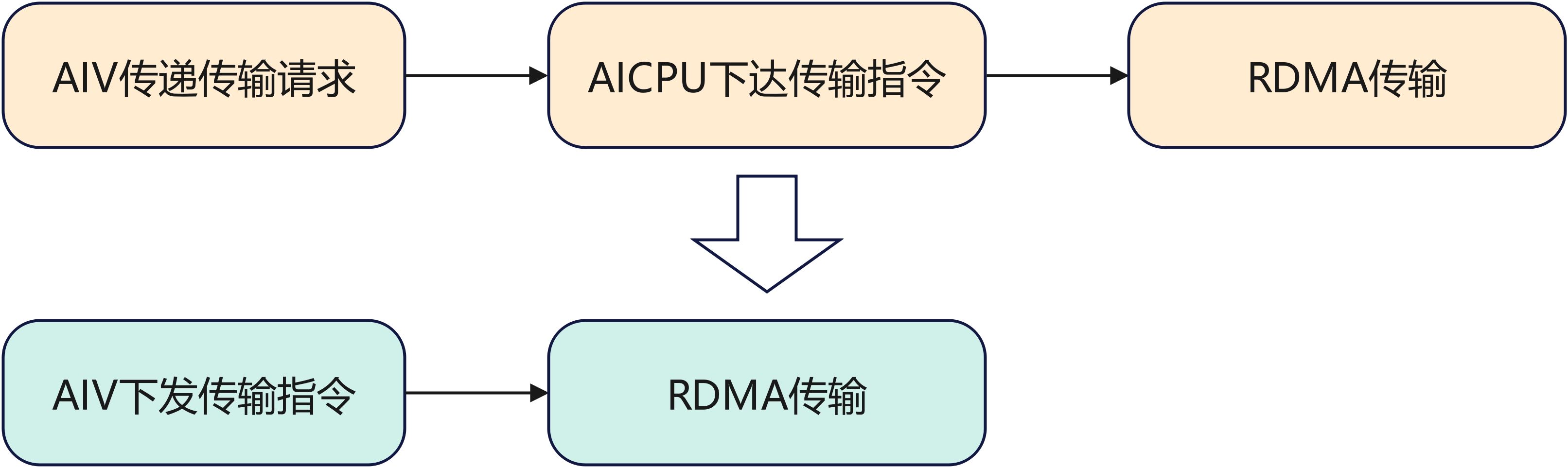
在 Dispatch 与 Combine 算子中,均涉及跨 Rank 的通信传输,而该传输能力主要依赖 RDMA(Remote Direct Memory Access,远程直接内存访问)实现。原始实现中,RDMA 传输指令的下发流程为:先由 AIV 将待传输数据在共享内存中的地址、长度等信息写入昇腾硬件外部存储(Global Memory)消息区,再由同一 Device 侧的 AICPU 读取消息,并通过其 2 个核驱动 RDMA 完成实际传输。该方案存在两点瓶颈:
(1) 指令下发链路较长,导致单次任务启动时延较高;
(2) AICPU 仅有双核参与下发,任务并行度受限。
优化后,系统改为由 AIV 直接下发 RDMA 传输指令,消除了经由 AICPU 的中间环节,从而显著缩短下发路径并降低单任务启动开销。同时,依托 AIV 的 24 核并行能力,相比 AICPU 双核方案,下发并发度得到大幅提升,进而有效改善 Dispatch 与 Combine 阶段的整体吞吐表现。
3 并行优化
在调度优化中,RDMA 传输指令已改为由 AIV 直接下发,但 RDMA 数据真正传输时并不需要 AIV 持续参与。问题在于,AIV 的最小资源分配单位是“算子”,一旦算子申请到 AIV 资源,通常会一直占用到算子结束;而 RDMA 又内嵌在 Dispatch / Combine 算子内部,导致即使传输阶段本身不使用 AIV,资源仍被占住,进而阻塞其他算子并行执行。
为此,可将 Dispatch 和 Combine 统一拆分为三个逻辑阶段:预处理 -> RDMA 传输 -> 后处理。其中,预处理阶段的结束标志是完成 RDMA 传输指令下发,后处理阶段的开始标志是 RDMA 传输完成。基于该边界,可将原算子拆分为两个独立算子:预处理算子 与 后处理算子。预处理算子仅负责组织数据并下发 RDMA 指令,后处理算子在传输完成后再读取结果并执行后续逻辑;中间的 RDMA 传输阶段由于任务已下发,不再需要以算子形态封装并占用 AIV。这样可以释放传输期间的 AIV 资源,使其他算子并行执行,从而提升整体计算效率与系统吞吐。
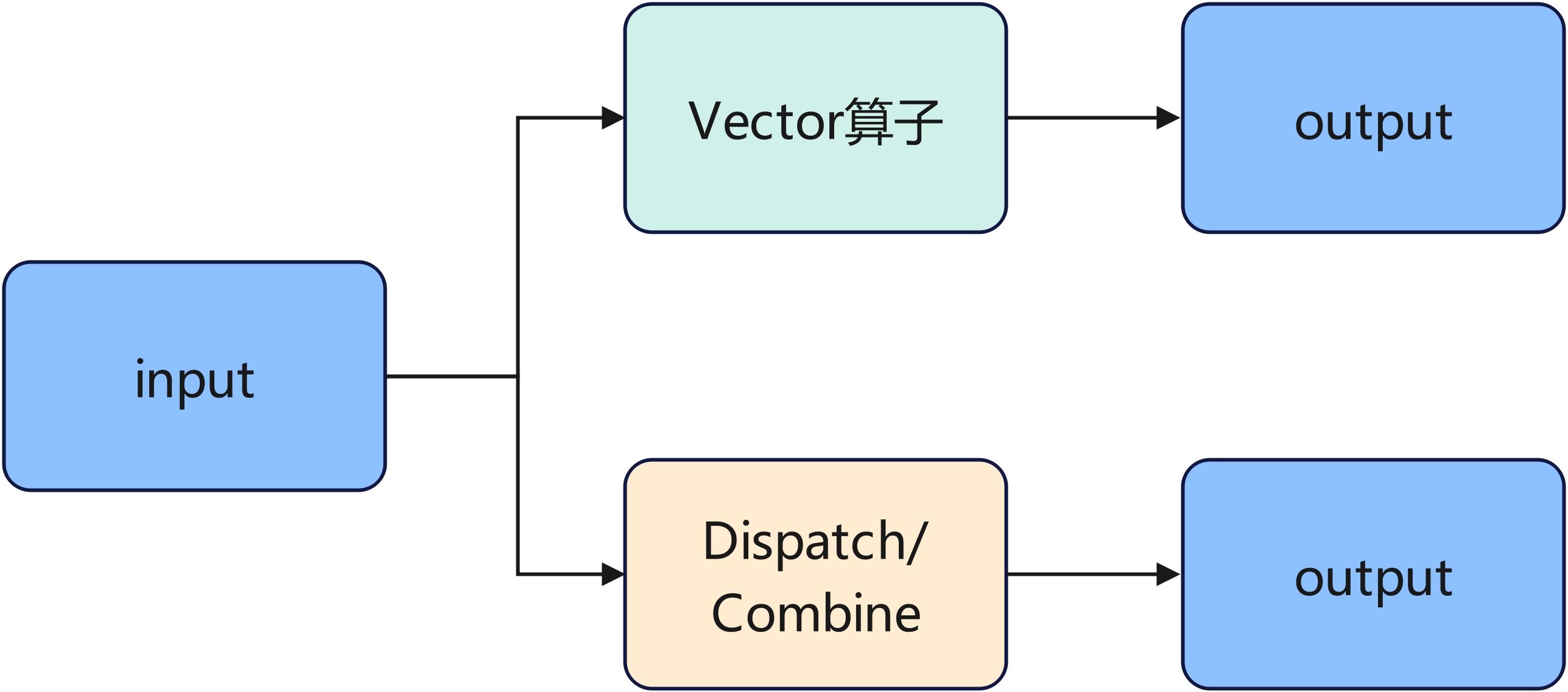
假设模型中存在以上结构片段,同一个输入分别提供给Dispatch/Combine算子和另一个Vector算子。由于这两个算子没有数据依赖,此时CANN会创建两条任务流期望两个算子并行执行。未优化前Dispatch/Combine会持续占据Vector核,另一个Vector算子无法并行计算。现在RDMA传输阶段Vector核会空闲释放出来,另一个Vector算子得以并行计算。

总结
客户基于CANN开源的Dispatch/Combine算子进行了持续优化,显著提升了业务的吞吐稳定性。特别是在跨Rank通信占比较高的场景中,MoE模块的性能得到了显著改善。随着CANN的开源,客户可以通过优化开源算子代码来进一步提升业务性能,而无需从零重构算子代码。这不仅降低了开发难度和成本,还为特定场景的优化提供了便利。CANN开源仓库也将持续关注算子性能、代码可读性和易用性的改进,为开发者提供更高水平的基线支持。
CANN开源社区:https://gitcode.com/cann/

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 0
0 0
0- 0



 已为社区贡献277条内容
已为社区贡献277条内容

所有评论(0)