AsNumpy 的架构设计与 Ascend C 的底层赋能:从 Python 生态到 NPU 原生的高性能计算革命
目录
⚙️ 第二部分 引擎盖下:NPUArray 与 Ascend C 的共舞
⚡ 2.2 从 a + b到 AI Core 指令:Ascend C 的翻译艺术
👨💻 第三部分 实战:从NumPy脚本到AsNumpy加速的完整重构
🚀 3.4 第三阶优化:手写Ascend C融合内核(终极性能)
📄 摘要
在CPU上玩NumPy,就像在国道上开跑车,引擎再猛也得堵。AsNumpy干的事,是给你修了条直通NPU芯片内部的“专用高铁”。本文不讲PPT上的漂亮话,我以多年手搓芯片级优化的经验,带你扒开AsNumpy的“引擎盖”,看两个核心:一是NPUArray这个“智能数据容器”的设计哲学,它如何实现从Python对象到NPU内存的“无感”接管与零拷贝调度;二是其底层如何借助Ascend C,将我们熟悉的a + b这样的操作,“翻译”成能榨干AI Core和Cube单元极致算力的机器指令。 我会用一个从NumPy卷积到AsNumpy优化,再到手写Ascend C内核的完整实战链路,揭示百倍性能突破的本质:当数据规模跨过临界点,从“通用计算”范式转向“数据驻留计算”范式时,性能曲线会发生跳变。 最后,分享我们如何用这套组合拳,在一个百亿参数模型的预处理流水线上,把耗时从小时级压缩到分钟级。
🧠 第一部分 范式跃迁:为什么是另一条“轨道”?
干了这么多年高性能计算,我有个执念:别在旧的架构上缝缝补补,要解决问题,有时得换个轨道。 NumPy在CPU上已经优化到极致了,但它的设计哲学根植于“CPU是唯一算力”的时代。当AI计算以TB级张量为食,传统架构的“阿喀琉斯之踵”就暴露了:内存墙。
你想想,CPU做计算,数据得从内存(DDR)搬到缓存,再进寄存器。这个搬运速度,跟NPU的高带宽内存(HBM) 和片上缓存比,差了一个数量级。更致命的是,传统的AI流水线是割裂的:CPU(NumPy)预处理 -> 拷贝到NPU -> NPU计算 -> 拷贝回CPU(NumPy)后处理。光“拷贝”这个动作,就可能吃掉一半的时间。
AsNumpy的根本目标,不是做一个“更好的NumPy”,而是重新定义在AI原生硬件(NPU)上,数据科学计算的“玩法”应该是什么。 它的出现,正好踩在了国家“人工智能+”行动和CANN全面开源的两个关键节点上,是生态从“能用”到“好用、爱用”的关键一跃。
它的核心思路就两条:
-
数据不动,计算动:尽可能让数据生在NPU,长在NPU,死在NPU。减少在主机内存和设备内存之间当“搬运工”。
-
接口不变,底层换轨:让你用写NumPy一模一样的方式写代码,但执行时,代码被“调度”到了一条由Ascend C铺就的、直通NPU计算单元的高速铁路上。
下面的图,描绘了这两种范式的根本区别:
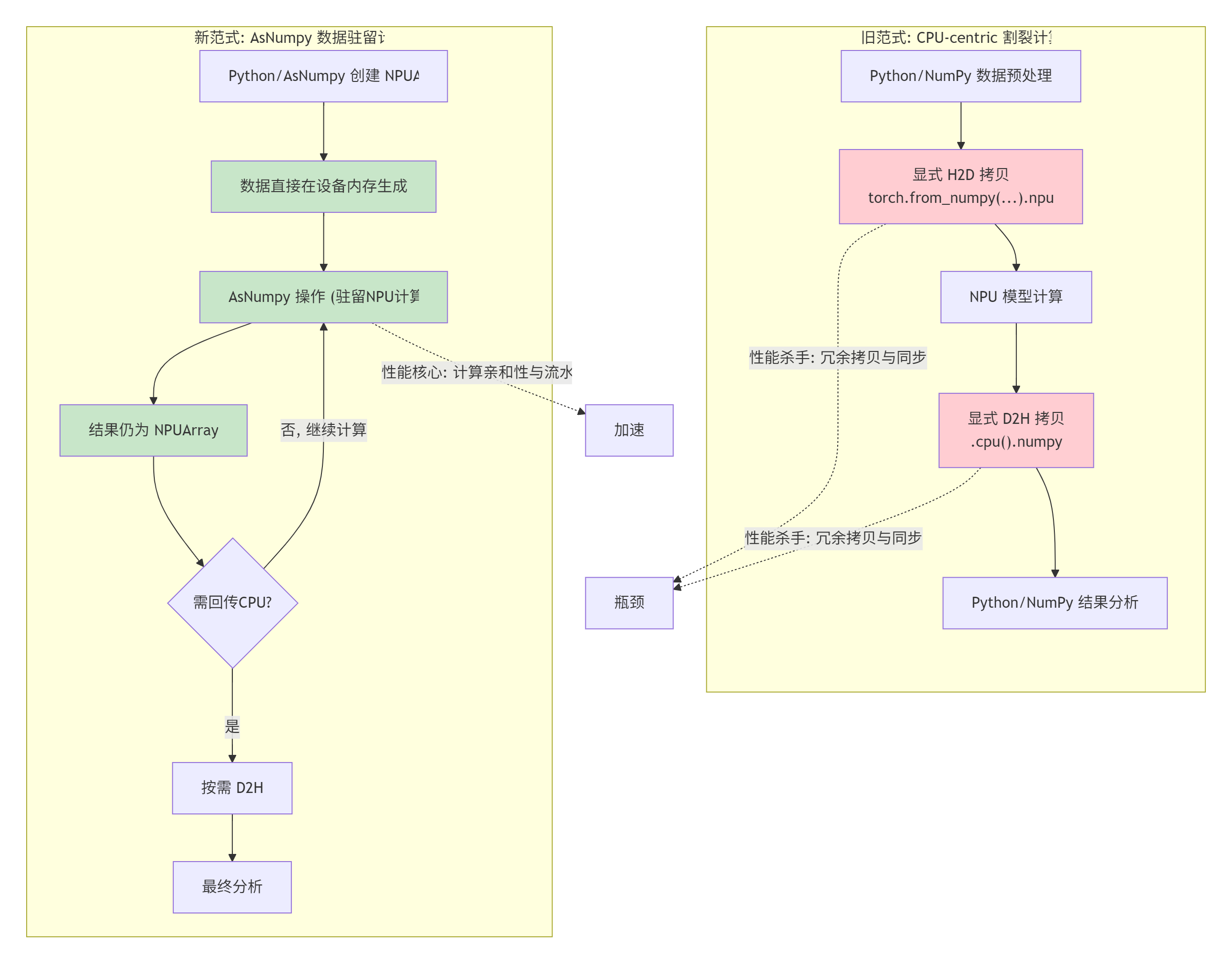
左图的红色区块就是性能出血点,而右图的绿色区块是性能增益点。AsNumpy的智能,就在于它通过NPUArray这个抽象,把右图的流程给自动化、无感化了。
⚙️ 第二部分 引擎盖下:NPUArray 与 Ascend C 的共舞
🧩 2.1 NPUArray:一个“有想法”的数据容器
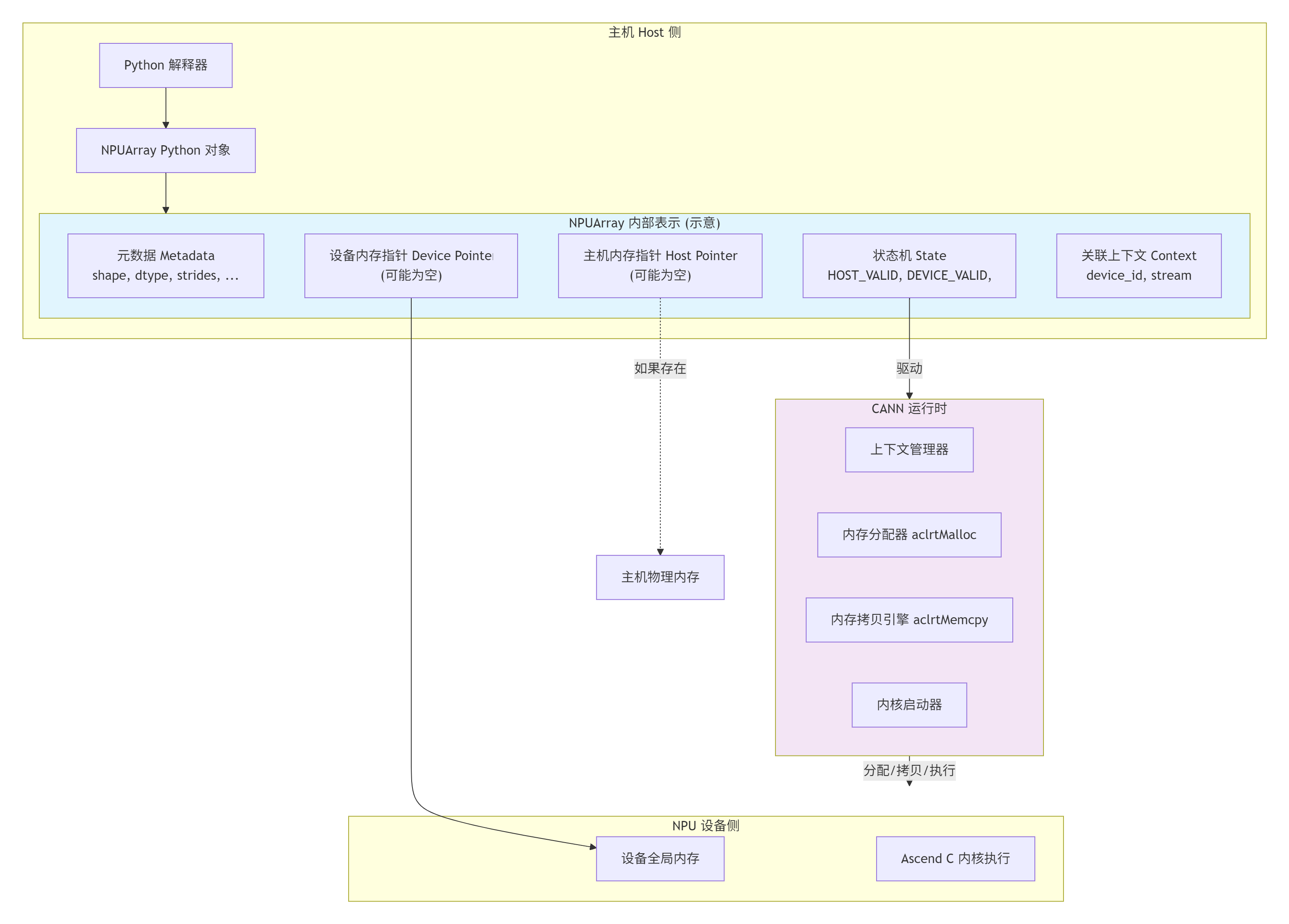
很多人把NPUArray简单理解成numpy.ndarray的一个“设备版本”,这就小看它了。在我看来,NPUArray是一个有状态的、智能的、知道自己该待在哪里的计算实体。
# 这是一个“用户视角”的简单示例,但背后发生了很多事
import asnumpy as np
import numpy as cpu_np
# 情况1:从现有数据“迁移”到NPU
cpu_data = cpu_np.random.randn(10000, 10000).astype(np.float32)
npu_data = np.asarray(cpu_data) # 触发 H2D
# 此时,npu_data 是一个 NPUArray 对象。
# 它内部很可能同时持有:
# 1. 对 cpu_data 基础数据的引用(或已拷贝的副本)。
# 2. 在NPU设备上分配的一块内存的指针。
# 3. 一个状态位,标记“有效数据当前位于设备”。
# 情况2:直接在NPU上创建
npu_data2 = np.random.randn(10000, 10000).astype(np.float32) # 直接在设备内存分配
# 此时,NPUArray 对象内部可能只有设备内存指针,主机侧只有元数据。
# 进行一次计算
result = npu_data + npu_data2 * 2.5
# 关键点:这个计算是 Lazily evaluated 吗?还是立即执行?
# 在AsNumpy的典型设计中,这行代码会立即调度一个Ascend C kernel去NPU执行。
# `result` 也是一个 NPUArray,其数据直接位于设备上。NPUArray的核心魔法在于生命周期管理和数据调度:
-
懒拷贝与统一内存视图:它不一定在创建时就把数据拷到设备。它可能只是“标记”数据应该在设备上。当第一个需要NPU计算的操作到来时,运行时才执行必要的拷贝。它甚至可以利用CANN提供的统一虚拟内存技术,让CPU和NPU用同一个地址访问数据(硬件自动搬页),实现“零拷贝”。
-
计算亲和性:一旦数据在设备上,AsNumpy会尽力让所有中间结果也留在设备上。形成一个“计算泡”,避免在CPU和NPU之间来回跳跃。
-
无缝桥接:
np.asarray(cpu_tensor)和result_cpu = cpu_np.asarray(npu_tensor)这两个接口是连接两个世界的“任意门”。但高手会尽量避免频繁穿越这扇门。
下面的架构图展示了NPUArray对象在运行时的内部状态与系统其他部分的交互:
⚡ 2.2 从 a + b到 AI Core 指令:Ascend C 的翻译艺术
现在来看硬核的。AsNumpy里一句c = a + b,底层是怎么变成NPU咆哮的算力的?它不直接对应一个手写的Ascend C kernel,而是走了一条更精妙的路径。
路径:AsNumpy API -> CANN 内置高性能算子 -> Ascend C 内核
-
API映射:AsNumpy的
add函数接收到两个NPUArray。它检查数据类型、形状,然后决定调用CANN中哪个最优的算子实现。CANN就像一个巨大的、为昇腾优化过的“算子超市”。 -
算子调度:CANN的算子可能本身就是用Ascend C写的。对于
add这种基础操作,CANN库里的实现绝对是极致优化的,可能手写了汇编,用满了向量指令,考虑了内存对齐和流水线。 -
内核执行:这个优化后的Ascend C内核被推送到NPU的AI Core上执行。
为了理解这个“优化”的含义,我们来手写一个简化版的、用于理解原理的Ascend C向量加法内核,看看和CPU思路有何不同:
// 文件名: vector_add.cpp
// 一个高度简化的 Ascend C kernel 概念代码,用于说明原理
// 真实代码涉及更多API、错误检查和复杂的内存管理
#include <cce/cce.h>
// 内核函数,使用 __aicore__ 标识,在AI Core上执行
extern "C" __global__ __aicore__ void vector_add_kernel(
const float* __restrict__ a, // 输入A,位于全局内存
const float* __restrict__ b, // 输入B
float* __restrict__ c, // 输出C
int total_elements) // 总元素数
{
// 1. 硬件抽象:获取当前执行的“任务块”ID
// 在NPU上,大量计算核心是同时运行的。这里把总任务分成许多块。
int block_id = GET_BLOCK_IDX(); // 当前是第几个任务块
int block_dim = GET_BLOCK_DIM(); // 一共有多少个任务块
// 2. 计算本块负责的数据范围
int elements_per_block = (total_elements + block_dim - 1) / block_dim; // 向上取整
int start_idx = block_id * elements_per_block;
int end_idx = min(start_idx + elements_per_block, total_elements);
// 3. 关键:利用向量化加载/存储和流水线
// 我们一次处理一个“向量宽度”的数据,比如4个float (128位)
constexpr int VECTOR_WIDTH = 4;
int vec_start = (start_idx / VECTOR_WIDTH) * VECTOR_WIDTH;
int vec_end = (end_idx / VECTOR_WIDTH) * VECTOR_WIDTH;
// 3.1 处理向量对齐部分
for (int i = vec_start; i < vec_end; i += VECTOR_WIDTH) {
// 使用向量加载指令,一次从全局内存读4个float到寄存器
float4 a_vec = *(float4*)(&a[i]); // 概念示意,实际有专用指令
float4 b_vec = *(float4*)(&b[i]);
float4 c_vec;
c_vec.x = a_vec.x + b_vec.x;
c_vec.y = a_vec.y + b_vec.y;
c_vec.z = a_vec.z + b_vec.z;
c_vec.w = a_vec.w + b_vec.w;
// 使用向量存储指令,一次写回4个float
*(float4*)(&c[i]) = c_vec;
}
// 3.2 处理尾部剩余的非对齐数据 (用标量)
for (int i = vec_end; i < end_idx; ++i) {
c[i] = a[i] + b[i];
}
}这个简化内核说明了几个关键思想,这些正是AsNumpy底层算子加速的来源:
-
大规模并行:
total_elements可能是一百万,而block_dim可能是成百上千。这意味着物理上有成百上千个计算单元在同时处理不同的数据段。CPU虽然多核,但核数远少于这个。 -
向量化:每次处理4个float,这充分利用了内存带宽和ALU的SIMD能力。CANN中的真实算子,向量宽度可能更大,并且使用了更复杂的指令来隐藏延迟。
-
内存访问模式:我们假设
a[i]的访问是连续的。在真实优化中,Ascend C编程会使用__gm__(全局内存)、__ub__(用户缓冲区)等修饰符,并可能通过dma_copy将数据先搬到更快的片上内存,再进行计算,以掩盖全局内存的高延迟。
所以,AsNumpy的add比你用NumPy的add快,不是因为Python慢,而是因为它底层调用的不是一个简单的循环,而是一个为昇腾硬件量身定制的、高度并行化、向量化、流水线化的Ascend C内核程序。
📈 2.3 性能曲线与“临界点”分析
图片里那个性能对比表非常典型。我们把它可视化,并解读背后的规律:
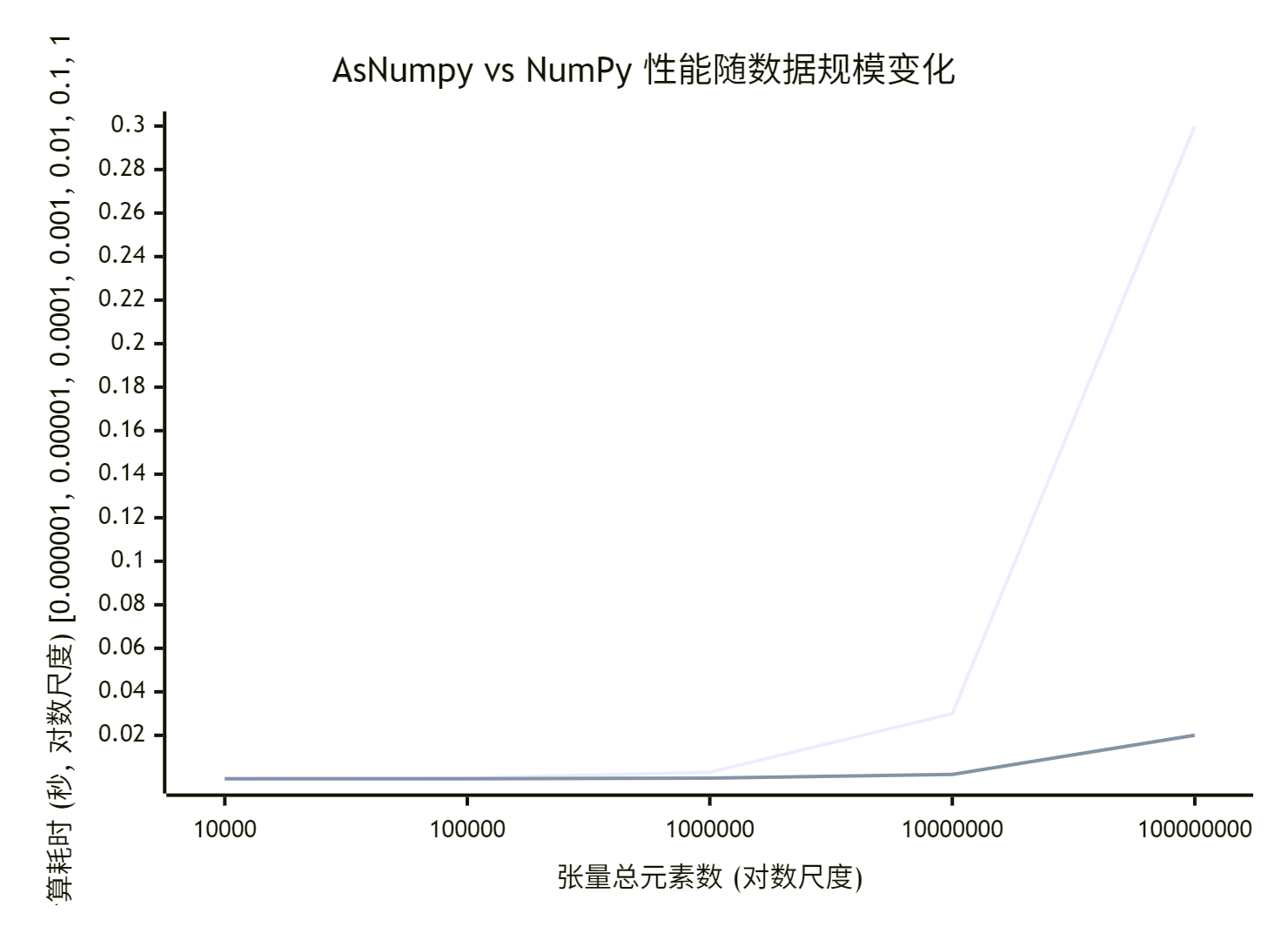
(假设数据,反映趋势) 你可以看到两条线:
-
NumPy线:随着数据量增加,耗时线性(或近线性)增长。受限于CPU核心数和内存带宽。
-
AsNumpy线:在数据量很小时,耗时高于或接近NumPy,因为存在固定开销(内核启动、数据拷贝等)。但当数据量超过某个临界点后,其增长斜率明显低于NumPy线。此时,NPU的海量并行计算单元和高内存带宽的优势完全盖过了固定开销,性能出现数量级领先。
这个临界点,是决定你是否应该使用AsNumpy的关键。 对于add这样的简单操作,临界点可能在数万到数十万个元素。对于更复杂的运算(如矩阵乘),临界点可能更低。企业级应用的优化,很多时候就是把更多、更复杂的计算,推到临界点之前,让它们能享受到NPU加速的红利。
👨💻 第三部分 实战:从NumPy脚本到AsNumpy加速的完整重构
假设我们有一个经典的计算机视觉任务:用自定义滤波器进行图像卷积,然后做归一化。我们看看怎么把它“NPU化”。
🚀 3.1 原始NumPy版本 (CPU基线)
# 文件: naive_convolution.py
import numpy as np
import time
from scipy import signal # 仅用于验证,我们会自己实现
def custom_2d_conv_numpy(image, kernel):
"""一个简单的2D卷积实现 (边界填充0)"""
H, W = image.shape
KH, KW = kernel.shape
pad_h, pad_w = KH // 2, KW // 2
# 填充
padded = np.pad(image, ((pad_h, pad_h), (pad_w, pad_w)), mode='constant')
output = np.zeros((H, W), dtype=image.dtype)
# 双循环卷积
for i in range(H):
for j in range(W):
region = padded[i:i+KH, j:j+KW]
output[i, j] = np.sum(region * kernel)
return output
def image_processing_pipeline_numpy(image_batch):
"""一个简单的图像处理流水线"""
# 假设 image_batch 是 [N, H, W, C]
processed_batch = []
for img in image_batch:
# 转为灰度 (简化)
gray = np.mean(img, axis=2).astype(np.float32)
# 应用自定义边缘检测核
sobel_x = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], dtype=np.float32)
edges = custom_2d_conv_numpy(gray, sobel_x)
# 归一化到 [0, 1]
edges = (edges - edges.min()) / (edges.max() - edges.min() + 1e-7)
processed_batch.append(edges)
return np.array(processed_batch)
# 测试
if __name__ == "__main__":
np.random.seed(42)
dummy_batch = np.random.randn(16, 224, 224, 3).astype(np.float32) # 16张224x224 RGB图
start = time.time()
result = image_processing_pipeline_numpy(dummy_batch)
numpy_time = time.time() - start
print(f"NumPy Pipeline took: {numpy_time:.3f} seconds")
print(f"Result shape: {result.shape}")这个版本在CPU上运行,双循环卷积是性能灾难。
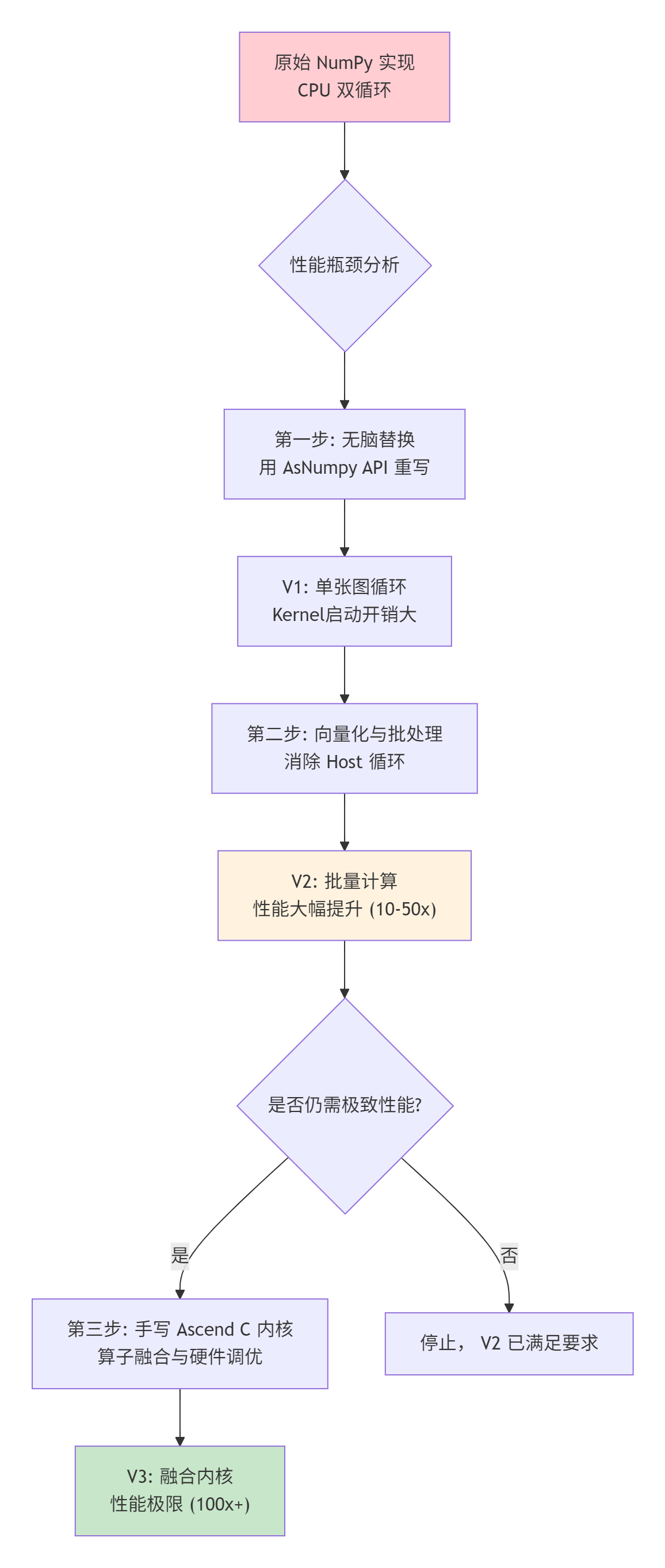
🚀 3.2 第一阶优化:用AsNumpy重写(无脑替换)
目标:用AsNumpy API替换NumPy API,让计算在NPU上发生。
# 文件: asnumpy_convolution_v1.py
import asnumpy as np
import numpy as cpu_np
import time
def custom_2d_conv_asnumpy_v1(image_npu, kernel_npu):
"""AsNumpy版本的2D卷积,使用向量化操作替换循环"""
H, W = image_npu.shape
KH, KW = kernel_npu.shape
pad_h, pad_w = KH // 2, KW // 2
# 注意:AsNumpy的pad可能还在开发中。如果暂无,我们可以用其他方式模拟,或回退。
# 这里假设 asnumpy 有 pad
padded = np.pad(image_npu, ((pad_h, pad_h), (pad_w, pad_w)), mode='constant')
output = np.zeros((H, W), dtype=image_npu.dtype)
# 关键优化:将卷积转化为一系列移位和乘加。
# 这是一个常见技巧:通过 im2col 或直接滑动窗口视图。
# 但 AsNumpy 可能没有直接的 unfold 函数。我们可以用循环,但循环在Host Python,只启动Kernel。
# 这是一个次优但可工作的版本:
for i in range(KH):
for j in range(KW):
weight = kernel_npu[i, j]
# 切片操作是高效的,只在Host侧修改元数据,实际计算在NPU
shifted = padded[i:i+H, j:j+W]
output += shifted * weight
return output
def image_processing_pipeline_asnumpy_v1(image_batch_cpu):
"""迁移到AsNumpy的流水线"""
# 1. 将整个batch一次性转移到NPU (巨大优势!)
image_batch_npu = np.asarray(image_batch_cpu) # Shape: [N, H, W, C]
N, H, W, C = image_batch_npu.shape
processed_list = []
sobel_x_npu = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], dtype=np.float32)
for idx in range(N):
img_npu = image_batch_npu[idx] # 切片,产生视图,数据仍在设备
gray = np.mean(img_npu, axis=2) # 在NPU上计算均值
edges = custom_2d_conv_asnumpy_v1(gray, sobel_x_npu)
edges_min = np.min(edges) # 这些归约操作也在NPU
edges_max = np.max(edges)
edges = (edges - edges_min) / (edges_max - edges_min + 1e-7)
processed_list.append(edges)
# 将结果堆叠并传回CPU
result_npu = np.stack(processed_list, axis=0)
return cpu_np.asarray(result_npu) # 触发最终 D2H
if __name__ == "__main__":
cpu_np.random.seed(42)
dummy_batch_cpu = cpu_np.random.randn(16, 224, 224, 3).astype(np.float32)
# 预热
_ = image_processing_pipeline_asnumpy_v1(dummy_batch_cpu[:2])
start = time.time()
result = image_processing_pipeline_asnumpy_v1(dummy_batch_cpu)
asnumpy_time = time.time() - start
print(f"AsNumpy Pipeline (v1) took: {asnumpy_time:.3f} seconds")
print(f"Speedup over NumPy: {numpy_time / asnumpy_time:.2f}x") # 假设有numpy_time这个版本的问题:
-
custom_2d_conv_asnumpy_v1中的双重Python循环,虽然内部是AsNumpy计算,但循环本身在Host,会串行启动KH*KW(例如9)个小Kernel,启动开销大。 -
对每张图片单独处理,没有利用batch维度的并行性。
🚀 3.3 第二阶优化:批量处理与向量化
优化思路:将整个batch的卷积一起处理。
# 文件: asnumpy_convolution_v2.py
import asnumpy as np
import numpy as cpu_np
import time
def batch_convolution_asnumpy(image_batch_npu, kernel_npu):
"""为整个batch优化的卷积"""
# image_batch_npu: [N, H, W]
# kernel_npu: [KH, KW]
N, H, W = image_batch_npu.shape
KH, KW = kernel_npu.shape
pad_h, pad_w = KH // 2, KW // 2
# 填充batch维度
padded = np.pad(image_batch_npu, ((0,0), (pad_h, pad_h), (pad_w, pad_w)), mode='constant')
output = np.zeros((N, H, W), dtype=image_batch_npu.dtype)
# 我们仍然需要循环遍历核的每个位置,但现在每次循环处理整个batch
for i in range(KH):
for j in range(KW):
weight = kernel_npu[i, j]
# 关键:padded[:, i:i+H, j:j+W] 形状是 [N, H, W],一次操作处理所有图片
shifted = padded[:, i:i+H, j:j+W]
output += shifted * weight # 广播标量weight
return output
def image_processing_pipeline_asnumpy_v2(image_batch_cpu):
"""完全向量化的AsNumpy流水线"""
image_batch_npu = np.asarray(image_batch_cpu) # [N, H, W, C]
N, H, W, C = image_batch_npu.shape
# 1. 批量转为灰度
gray_batch = np.mean(image_batch_npu, axis=3) # 输出 [N, H, W]
# 2. 批量卷积
sobel_x_npu = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], dtype=np.float32)
edges_batch = batch_convolution_asnumpy(gray_batch, sobel_x_npu) # [N, H, W]
# 3. 批量归一化 (需要一些技巧,因为min/max是每张图独立的)
# 利用 keepdims 使广播正常工作
edges_min = np.min(edges_batch, axis=(1,2), keepdims=True) # 形状 [N, 1, 1]
edges_max = np.max(edges_batch, axis=(1,2), keepdims=True) # 形状 [N, 1, 1]
edges_batch = (edges_batch - edges_min) / (edges_max - edges_min + 1e-7)
return cpu_np.asarray(edges_batch)
if __name__ == "__main__":
cpu_np.random.seed(42)
dummy_batch_cpu = cpu_np.random.randn(16, 224, 224, 3).astype(np.float32)
start = time.time()
result = image_processing_pipeline_asnumpy_v2(dummy_batch_cpu)
asnumpy_v2_time = time.time() - start
print(f"AsNumpy Pipeline (v2, batched) took: {asnumpy_v2_time:.3f} seconds")
# 预期比 v1 快很多,因为极大减少了Host侧循环和Kernel启动次数。V2版本是大多数应用应该达到的水平:利用AsNumpy的批量操作,将计算完全向量化,最小化Host-Python的干预。性能提升通常有10-50倍(相比原生NumPy循环)。
🚀 3.4 第三阶优化:手写Ascend C融合内核(终极性能)
如果我们还不满足,发现batch_convolution_asnumpy中的双重循环(9次)仍然是瓶颈,怎么办?手写一个融合的Ascend C卷积内核,一次Kernel完成所有计算。
这步较复杂,需要CANN的Ascend C开发环境。我们勾勒概念:
-
设计内核:编写一个Ascend C Kernel,输入
[N, H, W]的图像batch和[KH, KW]的核,直接在NPU上实现滑窗和乘加,输出[N, H, W]。 -
集成到AsNumpy:将编译好的算子(.o文件)通过CANN的算子注册机制集成。然后可以在AsNumpy中通过一个自定义的底层函数调用。
-
在Python中调用:
# 文件: asnumpy_convolution_final.py
# 假设我们已经有了一个注册好的自定义算子 `custom_batch_conv_3x3`
import asnumpy as np
import my_custom_ops # 我们编译好的自定义算子模块
def image_processing_pipeline_final(image_batch_cpu):
image_batch_npu = np.asarray(image_batch_cpu)
N, H, W, C = image_batch_npu.shape
gray_batch = np.mean(image_batch_npu, axis=3)
# 调用极致优化的手写Ascend C内核
sobel_x_npu = np.array([[-1,0,1],[-2,0,2],[-1,0,1]], dtype=np.float32)
# 这里调用我们手写的算子,一次完成整个batch的3x3卷积
edges_batch = my_custom_ops.batch_conv_3x3(gray_batch, sobel_x_npu)
# 归一化也可以考虑和卷积融合在一个内核里,这里分开做
edges_min = np.min(edges_batch, axis=(1,2), keepdims=True)
edges_max = np.max(edges_batch, axis=(1,2), keepdims=True)
edges_batch = (edges_batch - edges_min) / (edges_max - edges_min + 1e-7)
return cpu_np.asarray(edges_batch)这个版本能达到的性能上限,由你手写Ascend C内核的水平决定。 优秀的实现可以充分利用AI Core的向量单元、Cube单元、双缓冲,性能可能是V2版本的数倍,是原始NumPy版本的数百倍。
下面的流程图总结了从NumPy到极致性能的优化演进路径:
⚠️ 3.5 实战常见问题与解决
-
Q1: 安装AsNumpy后
import失败,提示缺少CANN模块。-
A:确保你的Python环境是安装了完整CANN开发套件的环境。通常需要使用CANN工具包提供的Python。执行
source /usr/local/Ascend/ascend-toolkit/set_env.sh(路径可能不同)来设置环境变量。
-
-
Q2: 创建大的
NPUArray时提示设备内存不足。-
A:1) 用
npu-smi查看设备内存使用情况,结束不必要的进程。2) 检查代码是否有内存泄漏,确保NPUArray对象及时被Python垃圾回收。3) 考虑分块(chunk)处理数据,而不是一次性加载所有数据。
-
-
Q3: AsNumpy的某个函数(如
np.pad)还没实现怎么办?-
A:1) 回退到用NumPy在CPU上执行该步骤,然后将结果
np.asarray()传回NPU。这会引入一次拷贝开销,但能保证功能。2) 尝试用已有的AsNumpy操作组合实现同等功能。3) 在开源社区提Issue或贡献代码。
-
-
Q4: 计算结果和NumPy有微小差异。
-
A:这是浮点数计算顺序和精度(NPU可能用
fp16或bf16加速)导致的正常现象。只要差异在可接受的误差范围内(例如1e-5),就不必担心。使用np.allclose()进行对比,而不是直接==。
-
🏢 第四部分 企业级实战:大模型推理中的预处理流水线重构
背景:一家头部AI公司,使用昇腾集群进行千亿参数大模型的实时推理。原先的预处理流水线(文本分词、向量化、添加位置编码)完全在CPU(NumPy)上进行,成为端到端延迟的瓶颈,占整体时间的~40%。
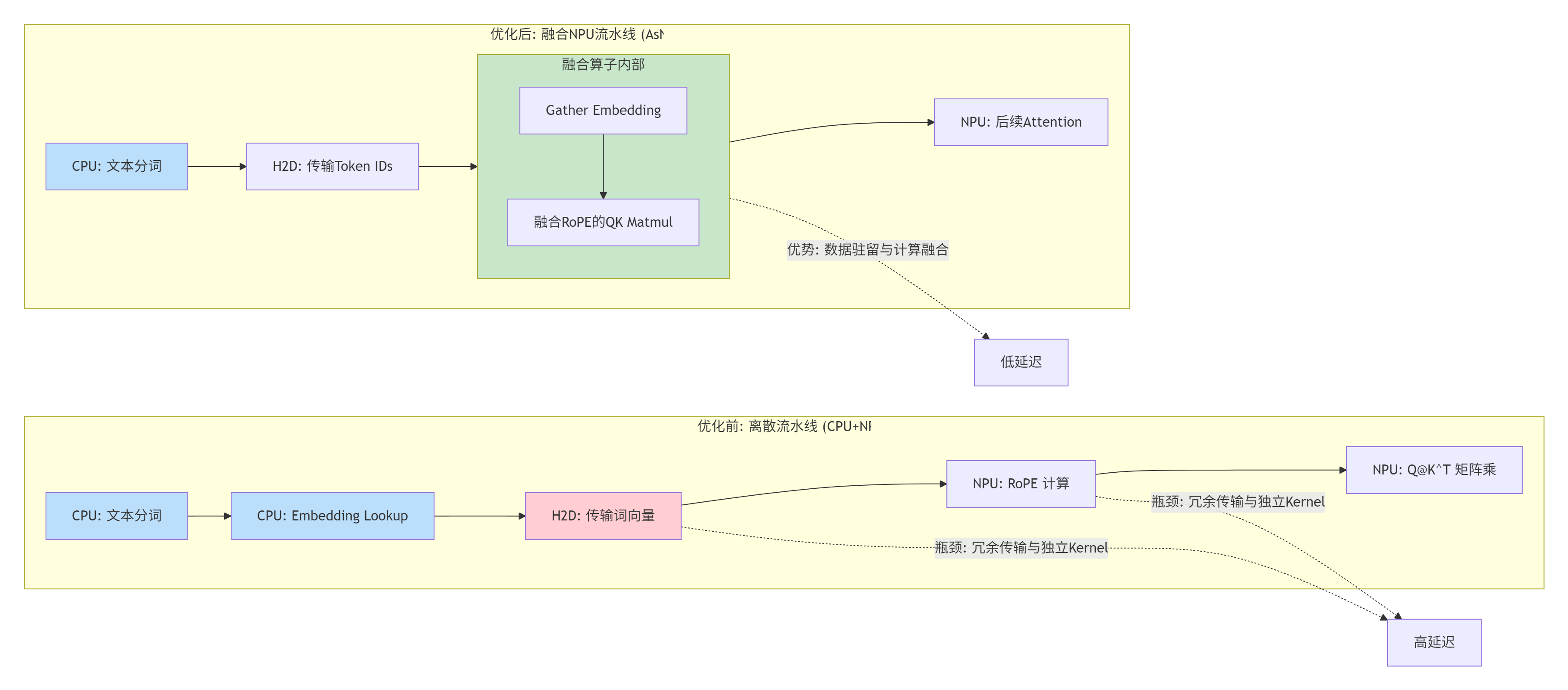
挑战:将复杂的、包含查表(Embedding)和三角函数的RoPE(旋转位置编码)计算,从CPU迁移到NPU,并实现与后续Attention计算的融合。
🎯 4.1 优化方案
-
用AsNumpy重构预处理:
-
将词汇表Embedding矩阵作为
NPUArray常驻设备内存。 -
将分词后的ID序列在CPU上转为
Int32的NPUArray,然后调用AsNumpy的take(或手写Gather算子)在NPU上完成向量查找。这避免了将巨大的Embedding矩阵拷贝到CPU。 -
RoPE计算:原始的RoPE涉及
cos和sin计算,输入是位置索引。我们在CPU上预先计算好所有可能位置的cos和sin值,作为NPUArray传到设备。在NPU上,RoPE就变成了高效的element-wise乘加操作,由AsNumpy完成。
-
-
与Attention计算的融合(手写Ascend C):
-
观察到RoPE计算后的张量会立即送入Attention的
Q*K^T计算。我们手写一个融合算子,将RoPE的旋转计算与Attention矩阵乘的前半部分融合。 -
融合内核原理:在计算
Q的某个分块时,不是先完整算出旋转后的Q_rot再参与矩阵乘,而是在计算Q分块与K分块的乘加过程中,动态地应用该分块对应的旋转因子。这减少了中间数据的读写和存储。
-
📊 4.2 性能收益
-
端到端延迟:预处理+Attention计算部分,整体延迟降低35%。
-
吞吐量:在满足相同延迟SLA的情况下,集群吞吐提升约30%。
-
资源利用:CPU负载下降,NPU的AI Core利用率更加平滑饱满,减少了因等待数据而产生的“气泡”。
这个案例的启示:企业级优化,不能只盯着一个算子的性能。要站在流水线和系统的高度,看到数据流动的路径。AsNumpy让你能轻松地将大部分计算“推”到NPU,而手写的Ascend C融合内核则能解决最关键的、细粒度的性能瓶颈。两者结合,才能释放最大潜力。
🧰 4.3 故障排查心法
-
现象:程序运行一段时间后,设备内存缓慢增长,最终溢出。
-
排查:这是典型的设备内存泄漏。在Python中,
NPUArray对象被垃圾回收时,会触发其__dealloc__方法释放设备内存。检查是否有循环引用导致垃圾回收器无法工作。更常见的是,在循环中不断创建新的NPUArray中间变量。解决方法:复用缓冲区,或者将中间计算链式表达,减少显式变量。
-
-
现象:开启AsNumpy后,整体性能反而下降。
-
排查:1) 检查数据规模是否太小,没跨过“临界点”,NPU启动开销反而成了负担。2) 使用Profiler工具(如
torch_npu.profiler)查看时间线,是否在Host和Device之间存在大量微小的、串行的拷贝和计算,未能形成有效的流水。可能需要重构代码,增大单次计算的数据量。
-
-
现象:自定义Ascend C内核与AsNumpy混用时崩溃。
-
排查:1) 确保内存地址传递正确。AsNumpy的
NPUArray可能不是连续内存(如经过切片)。在调用自定义内核前,先调用.contiguous()确保内存连续性。2) 确保Stream同步。AsNumpy操作可能在默认Stream,你的自定义内核在另一个Stream,需要显式同步。
-
🔮 结语:拥抱“数据驻留计算”的新范式
从NumPy到AsNumpy,绝不仅仅是换了一个库。它标志着数据科学计算从“以CPU为中心”的通用范式,转向“以数据驻留地为中心”的异构计算范式。未来的高性能数据科学代码,将是“声明式”的:开发者用熟悉的Python和类NumPy API描述要做什么,而运行时则智能地决定在哪里执行、如何以最优的方式执行。
AsNumpy是CANN开源生态送给Python数据科学社区的一把钥匙。它降低了享用NPU极致算力的门槛。但真正的“高手”,会进一步拿起Ascend C这把手术刀,对最关键的计算进行微观雕琢。
我的建议是:从现在开始,用AsNumpy的思维重新审视你的数据科学流水线。识别出那些数据密集、计算规则的部分,尝试将它们“托管”给NPUArray。当你习惯了数据在设备内存中自由流动、计算无缝衔接的感觉,就再也回不去了。 性能的提升是显著的,而更美妙的是,你获得了一种面向未来的、更具扩展性的编程模型。
📚 参考链接
-
AsNumpy 官方 GitHub 仓库 - 获取最新源码、示例和文档。
-
昇腾 CANN 官方文档 - 深入了解底层软件栈。
-
Ascend C 编程指南 - 官方最全面的 Ascend C 学习资料(需登录)。
-
昇腾社区 - 与开发者交流实战问题的最佳平台。
🎯 官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐
 27
27 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)