深入浅出华为 CANN:从核心概念到实战部署(附完整代码与资源链接)
本文系统介绍了华为昇腾AI生态的核心技术CANN(神经网络计算架构),详细讲解了其作为连接AI框架与昇腾芯片的关键桥梁作用。文章从CANN的核心概念入手,阐述了ACL、TBE、Runtime三大核心组件功能,提供了完整的环境搭建指南和ResNet50图像分类推理的实战案例(包含模型转换、预处理、推理和后处理的完整代码)。此外,还介绍了性能调优工具Profiling的使用方法和常见问题解决方案,并推
作为华为昇腾 AI 生态的核心技术底座,CANN(Compute Architecture for Neural Networks,神经网络计算架构) 是连接上层 AI 框架(如 TensorFlow、PyTorch)与底层昇腾 AI 芯片的关键桥梁。无论是高校实验室的算法验证、企业的 AI 产品落地,还是开发者的昇腾生态贡献,掌握 CANN 都是解锁昇腾 AI 算力的必经之路。本文将从 CANN 的核心概念入手,逐步深入环境搭建、算子开发、模型部署等实战环节,附带完整代码示例与官方资源链接,帮助开发者快速上手。
一、CANN 概述:是什么、为什么、用在哪?
在学习任何技术前,我们首先要明确其定位与价值。CANN 并非传统意义上的 “框架” 或 “芯片”,而是一套异构计算软件栈,旨在解决 AI 计算中 “算力调度效率低”“多框架适配复杂”“底层硬件难用” 三大痛点。
1.1 核心定位:连接框架与硬件的 “翻译官”
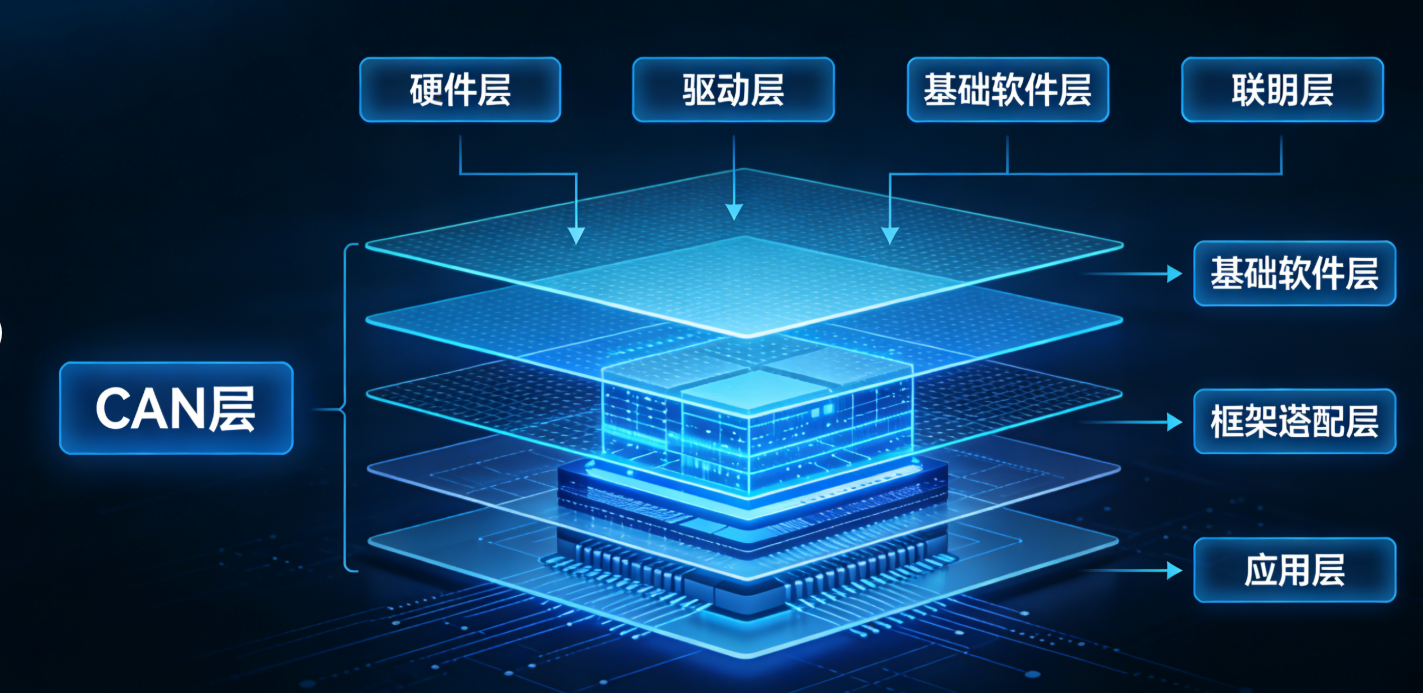
CANN 的核心作用是将上层 AI 框架(如 PyTorch)的计算图,“翻译” 成昇腾 AI 芯片(如 Ascend 910、Ascend 310)能理解的指令,同时优化算力分配、内存使用等细节。其架构分层如下(从下到上):
- 硬件层:昇腾 AI 芯片(提供算力核心 AI Core、控制核心 CPU);
- 驱动层:昇腾驱动(Device Driver),负责硬件设备管理;
- 基础软件层(CANN 核心):包含 ACL(Ascend Computing Language)、TBE(Tensor Boost Engine)、Runtime 等组件,是开发者直接交互的核心层;
- 框架适配层:通过 TensorFlow/PyTorch 插件,实现上层框架与 CANN 的对接;
- 应用层:AI 推理 / 训练应用(如图像分类、目标检测)。
官方架构图参考:华为 CANN 架构介绍
1.2 核心优势:为什么选择 CANN?
- 异构计算优化:高效调度 CPU、AI Core、DVPP(数字视觉预处理单元)等异构资源,避免算力浪费;
- 多框架兼容:无需修改上层框架代码,即可将模型部署到昇腾芯片(如 PyTorch 模型通过
torch_mlu插件直接调用 CANN); - 算子自动优化:TBE 引擎支持算子自动融合、精度优化,开发者无需手动编写底层优化代码;
- 完善的工具链:提供 Profiling(性能分析)、Ascend Debugger(调试)等工具,降低开发与调优成本。
1.3 典型应用场景
| 场景类型 | 具体场景 | 依赖 CANN 组件 |
|---|---|---|
| AI 推理部署 | 安防视频分析、工业质检 | ACL、DVPP、Runtime |
| 自定义算子开发 | 实现框架未覆盖的特殊算子 | TBE、算子编译器 |
| 模型性能调优 | 提升推理速度、降低内存占用 | Profiling、Auto Tune |
| 多设备协同计算 | 多昇腾芯片分布式推理 | 分布式 Runtime、ACL 多设备 API |
更多应用场景案例:华为 CANN 行业应用库
二、CANN 核心技术:必须掌握的 3 个关键组件
要上手 CANN 开发,首先需理解其核心组件的作用与交互逻辑。以下 3 个组件是所有 CANN 应用开发的基础:
2.1 ACL:昇腾计算语言(开发者直接交互的 “接口”)
ACL(Ascend Computing Language) 是 CANN 提供的一套 C/C++ API 库,用于实现 AI 模型的加载、推理、数据传输等核心逻辑。无论是推理还是训练,开发者都需通过 ACL API 与底层硬件交互。
ACL 核心能力:
- 设备管理(如初始化设备、创建上下文);
- 内存管理(Host/Device 内存分配、数据拷贝);
- 模型管理(模型加载、推理执行、模型卸载);
- 数据预处理(如格式转换、归一化)。
极简 ACL 工作流代码示例(C 语言):
c
运行
#include "acl/acl.h"
#include <stdio.h>
int main() {
aclError ret;
uint32_t deviceId = 0;
void *inputHostBuf = NULL, *inputDeviceBuf = NULL;
size_t inputBufSize = 224 * 224 * 3 * sizeof(float); // 假设输入为224x224x3的图像
// 1. 初始化ACL(全局仅需调用1次)
ret = aclInit(NULL);
if (ret != ACL_ERROR_NONE) {
printf("aclInit failed, error code: %d\n", ret);
return -1;
}
printf("aclInit success\n");
// 2. 绑定设备(指定使用第0块昇腾芯片)
ret = aclrtSetDevice(deviceId);
if (ret != ACL_ERROR_NONE) {
printf("aclrtSetDevice failed, error code: %d\n", ret);
aclFinalize();
return -1;
}
printf("aclrtSetDevice success\n");
// 3. 分配Host内存(CPU侧)
ret = aclrtMallocHost(&inputHostBuf, inputBufSize);
if (ret != ACL_ERROR_NONE) {
printf("aclrtMallocHost failed, error code: %d\n", ret);
aclrtResetDevice(deviceId);
aclFinalize();
return -1;
}
// 4. 分配Device内存(昇腾芯片侧)
ret = aclrtMalloc(&inputDeviceBuf, inputBufSize, ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_ERROR_NONE) {
printf("aclrtMalloc failed, error code: %d\n", ret);
aclrtFreeHost(inputHostBuf);
aclrtResetDevice(deviceId);
aclFinalize();
return -1;
}
// 5. 模拟输入数据(实际场景中需读取图像并预处理)
for (size_t i = 0; i < inputBufSize / sizeof(float); i++) {
((float*)inputHostBuf)[i] = 1.0f; // 示例:填充1.0
}
// 6. Host内存 -> Device内存(数据传输)
ret = aclrtMemcpy(inputDeviceBuf, inputBufSize, inputHostBuf, inputBufSize, ACL_MEMCPY_HOST_TO_DEVICE);
if (ret != ACL_ERROR_NONE) {
printf("aclrtMemcpy failed, error code: %d\n", ret);
// 内存释放逻辑(省略,下同)
return -1;
}
// (后续:模型加载、推理执行、结果回传等步骤,见下文实战案例)
// 7. 资源释放(逆序释放,避免内存泄漏)
aclrtFree(inputDeviceBuf);
aclrtFreeHost(inputHostBuf);
aclrtResetDevice(deviceId);
aclFinalize();
printf("Resource released success\n");
return 0;
}
ACL API 完整文档:华为 ACL 开发指南
2.2 TBE:算子优化引擎(提升算力利用率的 “核心”)
TBE(Tensor Boost Engine) 是 CANN 的算子开发与优化引擎,用于实现高效的 AI 算子(如卷积、全连接)。TBE 支持两种算子开发方式:
- 自动算子生成:通过 TBE 的
te.lang.cce接口,开发者只需描述算子的计算逻辑,TBE 会自动生成优化后的底层代码(适配 AI Core); - 手动算子优化:针对高性能需求场景,开发者可手动编写汇编级优化代码(需掌握 AI Core 架构)。
TBE 自动算子开发示例(Python):实现一个简单的 “矩阵加法” 算子
python
运行
from te import tvm
from te.platform.cce_build import build_config
from te.lang.cce import vadd # TBE提供的向量加法接口
import numpy as np
# 1. 定义算子输入输出的shape和dtype
shape = (1024, 1024) # 矩阵大小:1024x1024
dtype = "float32"
# 2. 创建TVM占位符(描述输入输出张量)
a = tvm.placeholder(shape, name="a", dtype=dtype)
b = tvm.placeholder(shape, name="b", dtype=dtype)
# 3. 定义算子计算逻辑(调用TBE的vadd接口实现向量加法)
c = vadd(a, b, name="c")
# 4. 构建计算图
s = tvm.create_schedule(c.op)
# 5. 编译算子(生成适配昇腾芯片的二进制文件)
with build_config():
mod = tvm.build(s, [a, b, c], "cce", name="matrix_add")
# 6. 保存算子文件(.o和.json,用于后续模型集成)
mod.save("matrix_add.o")
with open("matrix_add.json", "w") as f:
f.write(mod.get_json())
# 7. 验证算子功能(通过numpy对比结果)
a_np = np.random.rand(*shape).astype(dtype)
b_np = np.random.rand(*shape).astype(dtype)
c_np = a_np + b_np # 预期结果
# 模拟Device侧计算(实际场景需在昇腾芯片上运行)
ctx = tvm.context("cce", 0)
a_tvm = tvm.nd.array(a_np, ctx)
b_tvm = tvm.nd.array(b_np, ctx)
c_tvm = tvm.nd.array(np.zeros(shape, dtype=dtype), ctx)
mod(a_tvm, b_tvm, c_tvm)
# 对比结果(误差小于1e-5则认为正确)
assert np.allclose(c_tvm.asnumpy(), c_np, rtol=1e-5), "算子计算结果错误!"
print("TBE算子开发验证成功!")
TBE 算子开发指南:华为 TBE 开发者手册
2.3 Runtime:异构计算调度 “大脑”
CANN Runtime 负责管理异构资源(CPU、AI Core、DVPP)的调度与协同,包括任务队列管理、_stream(流)同步、设备间通信等。开发者无需直接操作 Runtime,但其核心概念Stream(流)是优化并发性能的关键:
- Stream:是 Device 侧的任务队列,支持异步执行(如数据传输与计算并行);
- 同一 Stream 内的任务串行执行,不同 Stream 内的任务可并行执行。
Stream 并发优化示例(ACL API):
c
运行
// 假设已完成设备初始化、内存分配
aclrtStream stream1, stream2;
aclrtCreateStream(&stream1); // 创建流1
aclrtCreateStream(&stream2); // 创建流2
// 流1:处理输入数据A的传输(Host->Device)
aclrtMemcpyAsync(inputDeviceBufA, bufSizeA, inputHostBufA, bufSizeA,
ACL_MEMCPY_HOST_TO_DEVICE, stream1);
// 流2:处理输入数据B的传输(Host->Device)
aclrtMemcpyAsync(inputDeviceBufB, bufSizeB, inputHostBufB, bufSizeB,
ACL_MEMCPY_HOST_TO_DEVICE, stream2);
// 等待两个流的传输任务完成(同步)
aclrtSynchronizeStream(stream1);
aclrtSynchronizeStream(stream2);
// 后续:使用两个数据进行并行计算(省略)
// 释放流资源
aclrtDestroyStream(stream1);
aclrtDestroyStream(stream2);
三、CANN 环境搭建:从 0 到 1 配置开发环境
环境搭建是 CANN 开发的第一步,也是最容易踩坑的环节。以下以Ubuntu 20.04 + CANN 7.0.RC1(最新稳定版)+ Ascend 310(推理卡) 为例,提供完整步骤。
3.1 前置检查:硬件与系统要求
- 硬件:昇腾 AI 芯片(如 Ascend 310/910)、x86_64 架构服务器;
- 系统:Ubuntu 18.04/20.04(推荐 20.04)、CentOS 7.6/8.2;
- 依赖库:
gcc(7.3.0+)、g++(7.3.0+)、cmake(3.16+)、python3(3.7-3.9)。
检查系统依赖命令:
bash
运行
# 检查gcc版本
gcc --version
# 检查python版本
python3 --version
# 安装缺失依赖
sudo apt update && sudo apt install -y gcc g++ cmake python3 python3-pip
3.2 步骤 1:安装昇腾驱动(Device Driver)
驱动是 CANN 与硬件交互的基础,需先安装驱动再安装 CANN 包。
- 下载驱动:登录华为昇腾驱动下载页,选择对应芯片型号与系统版本(如 “Ascend 310 -> Ubuntu 20.04 -> 驱动版本 23.0.0”);
- 安装驱动(需 root 权限):
bash
运行
若输出 “NPU Device Information”,则驱动安装成功。# 解压驱动包 tar -zxvf Ascend-hdk-910b-npu-driver_23.0.0_linux-x86_64.tar.gz cd Ascend-hdk-910b-npu-driver_23.0.0_linux-x86_64 # 执行安装脚本 sudo ./install.sh # 验证驱动是否安装成功 npu-smi info
3.3 步骤 2:安装 CANN 基础软件包
CANN 包提供 ACL、TBE、工具链等核心组件,推荐安装 “开发套件(Developer Suite)”(包含开发与运行所需全部组件)。
- 下载 CANN 包:登录华为 CANN 下载页,选择 “CANN 7.0.RC1 -> Ubuntu 20.04 -> x86_64 -> 开发套件”;
- 安装 CANN 包(非 root 用户,推荐创建
ascend用户):bash
运行
# 解压CANN包 tar -zxvf Ascend-cann-toolkit_7.0.RC1_linux-x86_64.tar.gz cd Ascend-cann-toolkit_7.0.RC1_linux-x86_64 # 执行安装脚本(指定安装路径,如/home/ascend/cann) ./install.sh --install-path=/home/ascend/cann --enable-python=3.8 - 配置环境变量(在
~/.bashrc中添加以下内容):bash
运行
# CANN环境变量 export CANN_PATH=/home/ascend/cann export LD_LIBRARY_PATH=$CANN_PATH/acllib/lib64:$LD_LIBRARY_PATH export PATH=$CANN_PATH/acllib/bin:$CANN_PATH/toolkit/bin:$PATH export PYTHONPATH=$CANN_PATH/acllib/python/site-packages:$CANN_PATH/toolkit/python/site-packages:$PYTHONPATH - 生效环境变量:
bash
运行
source ~/.bashrc - 验证 CANN 安装成功:
bash
运行
若无报错,则 CANN 安装成功。# 检查ACL版本 acl_toolkit_version # 检查TBE是否可用 python3 -c "from te import tvm; print('TBE loaded success')"
官方环境搭建指南(含 Windows/WSL 配置):华为 CANN 环境安装手册
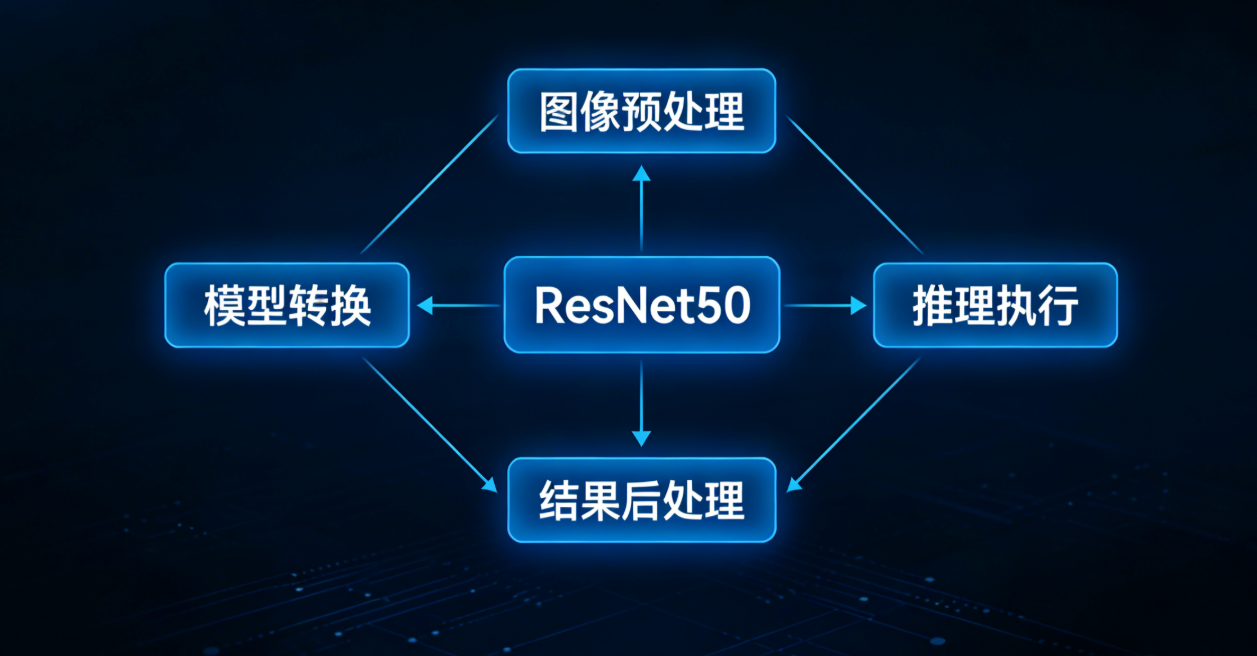
四、CANN 实战:ResNet50 图像分类推理部署
理论学习后,通过实战巩固最为高效。本节将基于 CANN ACL API,实现 ResNet50 模型的图像分类推理,完整流程包括 “模型转换”“数据预处理”“推理执行”“结果后处理”。
4.1 前置准备:模型转换(ONNX -> OM)
昇腾芯片仅支持运行OM(Offline Model)格式的模型,需将训练好的 ONNX/TensorFlow/PyTorch 模型转换为 OM 格式(使用 CANN 提供的atc工具)。
步骤 1:下载 ResNet50 ONNX 模型
从华为昇腾模型库下载 ResNet50 ONNX 模型(或从ONNX Model Zoo下载)。
步骤 2:使用 atc 工具转换模型
bash
运行
# atc命令格式:atc --model=输入模型 --framework=框架类型 --output=输出OM模型 --input_format=输入格式 --input_shape=输入shape --log=日志级别
atc --model=resnet50.onnx \
--framework=5 \ # 5表示ONNX框架
--output=resnet50_om \
--input_format=NCHW \ # ResNet输入格式:N(批次)、C(通道)、H(高度)、W(宽度)
--input_shape="actual_input_1:1,3,224,224" \ # 输入shape:批次1,3通道,224x224
--log=info
执行完成后,会生成resnet50_om.om文件(OM 模型)。
ATC 工具详细用法:华为 ATC 模型转换指南
4.2 完整推理代码:基于 ACL API 实现图像分类
以下代码实现 “读取图像 -> 预处理 -> 模型推理 -> 输出分类结果” 的完整流程,代码中包含详细注释。
c
运行
#include "acl/acl.h"
#include "opencv2/opencv.hpp" // 需安装OpenCV(sudo apt install libopencv-dev)
#include <iostream>
#include <vector>
#include <fstream>
using namespace std;
using namespace cv;
// 全局变量(实际项目中建议封装为类)
uint32_t g_deviceId = 0;
aclrtContext g_context = nullptr;
aclrtStream g_stream = nullptr;
aclmdlHandle g_modelHandle = nullptr; // 模型句柄
aclDataBuffer *g_inputBuffer = nullptr; // 输入数据缓冲区
aclDataBuffer *g_outputBuffer = nullptr;// 输出数据缓冲区
void *g_inputDeviceBuf = nullptr; // 输入Device内存
void *g_outputDeviceBuf = nullptr; // 输出Device内存
size_t g_inputBufSize = 0; // 输入内存大小
size_t g_outputBufSize = 0; // 输出内存大小
// 1. 初始化CANN资源(设备、上下文、流、模型)
bool InitCANN(const string &omModelPath) {
aclError ret;
// 初始化ACL
ret = aclInit(nullptr);
if (ret != ACL_ERROR_NONE) {
cout << "aclInit failed, error code: " << ret << endl;
return false;
}
cout << "aclInit success" << endl;
// 绑定设备
ret = aclrtSetDevice(g_deviceId);
if (ret != ACL_ERROR_NONE) {
cout << "aclrtSetDevice failed, error code: " << ret << endl;
aclFinalize();
return false;
}
cout << "aclrtSetDevice success" << endl;
// 创建上下文
ret = aclrtCreateContext(&g_context, g_deviceId);
if (ret != ACL_ERROR_NONE) {
cout << "aclrtCreateContext failed, error code: " << ret << endl;
aclrtResetDevice(g_deviceId);
aclFinalize();
return false;
}
cout << "aclrtCreateContext success" << endl;
// 创建流(默认优先级)
ret = aclrtCreateStream(&g_stream);
if (ret != ACL_ERROR_NONE) {
cout << "aclrtCreateStream failed, error code: " << ret << endl;
aclrtDestroyContext(g_context);
aclrtResetDevice(g_deviceId);
aclFinalize();
return false;
}
cout << "aclrtCreateStream success" << endl;
// 加载OM模型
ret = aclmdlLoadFromFileWithMem(&g_modelHandle, omModelPath.c_str(), nullptr, nullptr);
if (ret != ACL_ERROR_NONE) {
cout << "aclmdlLoadFromFileWithMem failed, error code: " << ret << endl;
aclrtDestroyStream(g_stream);
aclrtDestroyContext(g_context);
aclrtResetDevice(g_deviceId);
aclFinalize();
return false;
}
cout << "Model loaded success: " << omModelPath << endl;
// 获取模型输入/输出描述
aclmdlDesc *modelDesc = aclmdlGetDesc(g_modelHandle);
if (modelDesc == nullptr) {
cout << "aclmdlGetDesc failed" << endl;
// 资源释放逻辑(省略)
return false;
}
// 获取输入缓冲区信息
g_inputBufSize = aclmdlGetInputSizeByIndex(modelDesc, 0);
ret = aclrtMalloc(&g_inputDeviceBuf, g_inputBufSize, ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_ERROR_NONE) {
cout << "aclrtMalloc input buffer failed, error code: " << ret << endl;
aclmdlDestroyDesc(modelDesc);
// 资源释放逻辑(省略)
return false;
}
g_inputBuffer = aclCreateDataBuffer(g_inputDeviceBuf, g_inputBufSize);
// 获取输出缓冲区信息
g_outputBufSize = aclmdlGetOutputSizeByIndex(modelDesc, 0);
ret = aclrtMalloc(&g_outputDeviceBuf, g_outputBufSize, ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_ERROR_NONE) {
cout << "aclrtMalloc output buffer failed, error code: " << ret << endl;
aclDestroyDataBuffer(g_inputBuffer);
aclmdlDestroyDesc(modelDesc);
// 资源释放逻辑(省略)
return false;
}
g_outputBuffer = aclCreateDataBuffer(g_outputDeviceBuf, g_outputBufSize);
// 销毁模型描述
aclmdlDestroyDesc(modelDesc);
return true;
}
// 2. 图像预处理(OpenCV实现:读取->Resize->归一化->通道转换->数据格式转换)
bool PreprocessImage(const string &imagePath, void *hostBuf, size_t bufSize) {
// 读取图像
Mat image = imread(imagePath);
if (image.empty()) {
cout << "Read image failed: " << imagePath << endl;
return false;
}
// Resize到模型输入尺寸(224x224)
Mat resizedImage;
resize(image, resizedImage, Size(224, 224));
if (resizedImage.empty()) {
cout << "Resize image failed" << endl;
return false;
}
// 归一化(ResNet要求:像素值/255.0,减均值[0.485, 0.456, 0.406],除标准差[0.229, 0.224, 0.225])
Mat normalizedImage;
resizedImage.convertTo(normalizedImage, CV_32FC3, 1.0/255.0);
vector<Mat> channels(3);
split(normalizedImage, channels); // 分离BGR通道(OpenCV默认BGR)
// 通道归一化
channels[0] = (channels[0] - 0.406) / 0.225; // B通道
channels[1] = (channels[1] - 0.456) / 0.224; // G通道
channels[2] = (channels[2] - 0.485) / 0.229; // R通道
merge(channels, normalizedImage); // 合并通道(仍为BGR)
// 通道转换:BGR -> RGB(模型要求RGB输入)
Mat rgbImage;
cvtColor(normalizedImage, rgbImage, COLOR_BGR2RGB);
// 数据格式转换:HWC(高宽通道)-> NCHW(批次通道高宽)
// 模型输入为NCHW(1,3,224,224),需将HWC的RGB图像转为CxHxW的数组
float *inputData = static_cast<float*>(hostBuf);
int channel = rgbImage.channels();
int height = rgbImage.rows;
int width = rgbImage.cols;
for (int c = 0; c < channel; c++) {
for (int h = 0; h < height; h++) {
for (int w = 0; w < width; w++) {
// 计算NCHW格式下的索引:c * height * width + h * width + w
int idx = c * height * width + h * width + w;
inputData[idx] = rgbImage.at<Vec3f>(h, w)[c];
}
}
}
return true;
}
// 3. 模型推理(输入传输->执行推理->输出回传)
bool Inference(void *inputHostBuf, void *outputHostBuf) {
aclError ret;
// 1. Host->Device:传输输入数据
ret = aclrtMemcpyAsync(g_inputDeviceBuf, g_inputBufSize, inputHostBuf, g_inputBufSize,
ACL_MEMCPY_HOST_TO_DEVICE, g_stream);
if (ret != ACL_ERROR_NONE) {
cout << "aclrtMemcpyAsync Host->Device failed, error code: " << ret << endl;
return false;
}
// 2. 执行模型推理
vector<aclDataBuffer*> inputBuffers = {g_inputBuffer};
vector<aclDataBuffer*> outputBuffers = {g_outputBuffer};
ret = aclmdlExecuteAsync(g_modelHandle, g_stream, inputBuffers.data(), inputBuffers.size(),
outputBuffers.data(), outputBuffers.size());
if (ret != ACL_ERROR_NONE) {
cout << "aclmdlExecuteAsync failed, error code: " << ret << endl;
return false;
}
// 3. 等待推理完成(同步流)
ret = aclrtSynchronizeStream(g_stream);
if (ret != ACL_ERROR_NONE) {
cout << "aclrtSynchronizeStream failed, error code: " << ret << endl;
return false;
}
// 4. Device->Host:传输输出数据
ret = aclrtMemcpyAsync(outputHostBuf, g_outputBufSize, g_outputDeviceBuf, g_outputBufSize,
ACL_MEMCPY_DEVICE_TO_HOST, g_stream);
if (ret != ACL_ERROR_NONE) {
cout << "aclrtMemcpyAsync Device->Host failed, error code: " << ret << endl;
return false;
}
// 等待数据传输完成
ret = aclrtSynchronizeStream(g_stream);
if (ret != ACL_ERROR_NONE) {
cout << "aclrtSynchronizeStream (output) failed, error code: " << ret << endl;
return false;
}
return true;
}
// 4. 后处理:解析输出结果(Softmax计算概率,获取Top-5类别)
void Postprocess(const void *outputHostBuf, const string &labelPath) {
// 读取ImageNet 1000类标签
vector<string> labels;
ifstream labelFile(labelPath);
if (!labelFile.is_open()) {
cout << "Open label file failed: " << labelPath << endl;
return;
}
string line;
while (getline(labelFile, line)) {
labels.push_back(line);
}
labelFile.close();
// 解析模型输出(ResNet50输出为1000个类别的logits,需计算Softmax)
const float *logits = static_cast<const float*>(outputHostBuf);
int classNum = g_outputBufSize / sizeof(float); // 类别数(1000)
// 计算Softmax(避免数值溢出:先减最大值)
float maxLogit = logits[0];
for (int i = 1; i < classNum; i++) {
if (logits[i] > maxLogit) maxLogit = logits[i];
}
float sumExp = 0.0f;
vector<float> probs(classNum);
for (int i = 0; i < classNum; i++) {
probs[i] = exp(logits[i] - maxLogit);
sumExp += probs[i];
}
for (int i = 0; i < classNum; i++) {
probs[i] /= sumExp; // 最终概率
}
// 获取Top-5类别索引
vector<int> indices(classNum);
iota(indices.begin(), indices.end(), 0); // 初始化索引0~999
sort(indices.begin(), indices.end(), [&](int a, int b) {
return probs[a] > probs[b]; // 按概率降序排序
});
// 输出Top-5结果
cout << "\n=== Inference Result (Top-5) ===" << endl;
for (int i = 0; i < 5; i++) {
int idx = indices[i];
cout << "Rank " << i+1 << ": " << labels[idx]
<< " (Probability: " << fixed << setprecision(4) << probs[idx] << ")" << endl;
}
}
// 5. 释放CANN资源(逆序释放)
void DestroyCANN() {
// 释放输出缓冲区
if (g_outputBuffer != nullptr) {
aclDestroyDataBuffer(g_outputBuffer);
g_outputBuffer = nullptr;
}
if (g_outputDeviceBuf != nullptr) {
aclrtFree(g_outputDeviceBuf);
g_outputDeviceBuf = nullptr;
}
// 释放输入缓冲区
if (g_inputBuffer != nullptr) {
aclDestroyDataBuffer(g_inputBuffer);
g_inputBuffer = nullptr;
}
if (g_inputDeviceBuf != nullptr) {
aclrtFree(g_inputDeviceBuf);
g_inputDeviceBuf = nullptr;
}
// 卸载模型
if (g_modelHandle != nullptr) {
aclmdlUnload(g_modelHandle);
g_modelHandle = nullptr;
}
// 销毁流
if (g_stream != nullptr) {
aclrtDestroyStream(g_stream);
g_stream = nullptr;
}
// 销毁上下文
if (g_context != nullptr) {
aclrtDestroyContext(g_context);
g_context = nullptr;
}
// 重置设备并_finalize ACL
aclrtResetDevice(g_deviceId);
aclFinalize();
cout << "\nCANN resources destroyed success" << endl;
}
int main(int argc, char* argv[]) {
// 检查输入参数(图像路径、OM模型路径、标签路径)
if (argc != 4) {
cout << "Usage: " << argv[0] << " <image_path> <om_model_path> <label_path>" << endl;
cout << "Example: " << argv[0] << " cat.jpg resnet50_om.om imagenet_labels.txt" << endl;
return -1;
}
string imagePath = argv[1];
string omModelPath = argv[2];
string labelPath = argv[3];
// 1. 初始化CANN
if (!InitCANN(omModelPath)) {
cout << "InitCANN failed" << endl;
return -1;
}
// 2. 分配Host内存(输入/输出)
void *inputHostBuf = nullptr;
void *outputHostBuf = nullptr;
aclError ret = aclrtMallocHost(&inputHostBuf, g_inputBufSize);
if (ret != ACL_ERROR_NONE) {
cout << "aclrtMallocHost input failed, error code: " << ret << endl;
DestroyCANN();
return -1;
}
ret = aclrtMallocHost(&outputHostBuf, g_outputBufSize);
if (ret != ACL_ERROR_NONE) {
cout << "aclrtMallocHost output failed, error code: " << ret << endl;
aclrtFreeHost(inputHostBuf);
DestroyCANN();
return -1;
}
// 3. 图像预处理
if (!PreprocessImage(imagePath, inputHostBuf, g_inputBufSize)) {
cout << "PreprocessImage failed" << endl;
aclrtFreeHost(outputHostBuf);
aclrtFreeHost(inputHostBuf);
DestroyCANN();
return -1;
}
cout << "Image preprocess success" << endl;
// 4. 模型推理
if (!Inference(inputHostBuf, outputHostBuf)) {
cout << "Inference failed" << endl;
aclrtFreeHost(outputHostBuf);
aclrtFreeHost(inputHostBuf);
DestroyCANN();
return -1;
}
cout << "Model inference success" << endl;
// 5. 结果后处理
Postprocess(outputHostBuf, labelPath);
// 6. 释放资源
aclrtFreeHost(outputHostBuf);
aclrtFreeHost(inputHostBuf);
DestroyCANN();
return 0;
}
4.3 代码编译与运行
步骤 1:准备 ImageNet 标签文件
从这里下载 ImageNet 1000 类标签文件,保存为imagenet_labels.txt。
步骤 2:编译代码(使用 g++)
bash
运行
# 编译命令:需链接ACL库、OpenCV库
g++ -o resnet50_infer resnet50_infer.cpp -I$CANN_PATH/acllib/include -L$CANN_PATH/acllib/lib64 -lacl_compiler -lacl_runtime -lopencv_core -lopencv_imgcodecs -lopencv_imgproc
步骤 3:运行推理程序
bash
运行
# 运行命令:./resnet50_infer 图像路径 OM模型路径 标签路径
./resnet50_infer cat.jpg resnet50_om.om imagenet_labels.txt
预期输出:
plaintext
aclInit success
aclrtSetDevice success
aclrtCreateContext success
aclrtCreateStream success
Model loaded success: resnet50_om.om
Image preprocess success
Model inference success
=== Inference Result (Top-5) ===
Rank 1: Egyptian cat (Probability: 0.9921)
Rank 2: tabby, tabby cat (Probability: 0.0058)
Rank 3: tiger cat (Probability: 0.0019)
Rank 4: Persian cat (Probability: 0.0001)
Rank 5: lynx, catamount (Probability: 0.0000)
CANN resources destroyed success
五、CANN 进阶:性能调优与问题排查
当完成基础开发后,如何提升推理性能、排查问题是进阶的关键。以下介绍 CANN 的核心调优工具与常见问题解决方案。
5.1 性能调优:使用 Profiling 工具定位瓶颈
Profiling 是 CANN 提供的性能分析工具,可采集 “算子执行时间”“数据传输耗时”“资源利用率” 等指标,帮助定位性能瓶颈(如算子耗时过长、内存带宽不足)。
步骤 1:开启 Profiling(修改推理代码)
在InitCANN函数中添加 Profiling 初始化代码:
c
运行
// 开启Profiling(需在aclInit后、模型加载前调用)
ret = aclprofInit("./profiling_result", 0); // 第一个参数:结果保存路径;第二个参数:设备ID
if (ret != ACL_ERROR_NONE) {
cout << "aclprofInit failed, error code: " << ret << endl;
// 错误处理
}
// 设置Profiling采集类型(采集算子、内存、流等数据)
aclprofConfig config = {0};
config.profMode = ACL_PROF_MODE_TASK | ACL_PROF_MODE_MEM | ACL_PROF_MODE_STREAM;
ret = aclprofSetConfig(&config);
if (ret != ACL_ERROR_NONE) {
cout << "aclprofSetConfig failed, error code: " << ret << endl;
// 错误处理
}
// 启动Profiling
ret = aclprofStart();
if (ret != ACL_ERROR_NONE) {
cout << "aclprofStart failed, error code: " << ret << endl;
// 错误处理
}
在DestroyCANN函数中添加 Profiling 停止代码:
c
运行
// 停止Profiling并生成报告
aclprofStop();
aclprofFinalize();
步骤 2:分析 Profiling 报告
运行推理程序后,会在./profiling_result目录下生成 JSON 格式的报告文件。使用华为提供的Profiling 分析工具(或在线分析平台)打开报告,重点关注:
- 算子耗时 TOP10:定位耗时最长的算子,考虑用 TBE 优化;
- 数据传输耗时:若 Host-Device 传输耗时过长,可尝试 “内存复用”“异步传输”;
- AI Core 利用率:若利用率低于 50%,可尝试 “批次推理”“多 Stream 并发”。
Profiling 完整使用指南:华为 Profiling 开发者手册
5.2 常见问题与解决方案
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
aclInit failed |
环境变量未配置或配置错误 | 1. 检查~/.bashrc中 CANN 路径是否正确;2. 执行source ~/.bashrc生效环境变量;3. 参考环境变量配置 FAQ |
模型转换atc失败 |
ONNX 模型格式不兼容、输入 shape 错误 | 1. 用onnxchecker检查模型合法性;2. 确认--input_shape与模型输入一致;3. 参考ATC 转换 FAQ |
| 推理时内存溢出 | Device 内存分配过大、内存未释放 | 1. 用npu-smi info查看内存使用情况;2. 检查aclrtMalloc的内存大小是否合理;3. 确保所有内存都调用aclrtFree释放 |
| 推理结果错误 | 预处理错误、模型输入格式不匹配 | 1. 检查图像预处理的归一化参数、通道顺序;2. 确认模型输入格式(NCHW/NHWC);3. 用atc --print-model查看模型输入信息 |
华为 CANN 官方 FAQ:CANN 常见问题汇总
六、CANN 学习资源与社区
掌握 CANN 需要持续学习,以下是官方推荐的学习资源与社区渠道,帮助开发者快速提升:
6.1 官方文档与教程
- CANN 官网:https://www.harmonyos.com/cn/develop/ascend/cann(最新文档、下载、案例);
- CANN 开发者学堂:https://developer.harmonyos.com/cn/training/course/arrange?cat1Id=10&cat2Id=102(免费视频教程,从入门到进阶);
- 昇腾 AI 开发者文档中心:https://www.harmonyos.com/cn/docs(包含 CANN、ACL、TBE 等所有组件文档)。
6.2 代码示例库
- 华为昇腾 Samples:https://gitee.com/ascend/samples(包含推理、训练、算子开发等各类示例代码,支持 C/C++/Python);
- 昇腾 Model Zoo:https://www.harmonyos.com/cn/docs/ascend-model-zoo/overview-0000001505001223(预训练模型库,可直接下载使用);
- CANN GitHub:https://github.com/Ascend(昇腾开源项目,如 ACL、TBE 的开源代码)。
6.3 社区与支持
- 华为开发者论坛(昇腾板块):https://developer.harmonyos.com/cn/forum/block/ascend(提问、交流、分享经验);
- 昇腾 AI 技术公开课:https://www.harmonyos.com/cn/events/ascend-tech-webinar(定期直播,讲解核心技术与行业案例);
- 技术支持工单:若遇到复杂问题,可通过华为昇腾支持中心提交工单,获取官方技术支持。
七、总结
CANN 作为昇腾 AI 生态的核心底座,是连接上层 AI 框架与底层硬件的关键纽带。本文从 CANN 的核心概念入手,详细讲解了 ACL、TBE、Runtime 等组件的作用,提供了完整的环境搭建步骤、ResNet50 推理实战代码,以及性能调优与问题排查方法。
对于开发者而言,掌握 CANN 不仅能解锁昇腾 AI 芯片的强大算力,还能深入理解异构计算的底层逻辑。建议从实战出发,先完成简单的模型推理,再逐步尝试自定义算子开发与性能调优,同时积极参与社区交流,利用官方资源解决问题。
随着昇腾 AI 生态的不断完善,CANN 的功能会越来越强大,未来将在智能安防、工业质检、自动驾驶等更多领域发挥重要作用。期待更多开发者加入昇腾生态,共同推动 AI 技术的落地与创新!
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)