【昇腾CANN训练营·行业篇】去伪存真:基于 AI Core 的高效 NMS(非极大值抑制)算子开发
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

前言
在 YOLO、SSD、Faster R-CNN 等检测网络中,NMS 是最后一道关卡。 它的算法逻辑非常“贪心”:
-
Sort:按置信度从高到低排序。
-
Pick:拿出得分最高的框 A。
-
Compare:计算 A 与剩余所有框的 IoU(交并比)。
-
Suppress:如果 IoU > 阈值,删掉那个框。
-
Loop:从剩下的框里再选最高的,重复步骤 2。
这个过程之所以难优化,是因为第 i 轮的结果依赖于第 i-1 轮的删除操作。这直接打破了 SIMD 的并行性。 但在 Ascend C 中,我们可以利用 Vector 强大的批量计算能力 来加速最耗时的 IoU 计算环节。
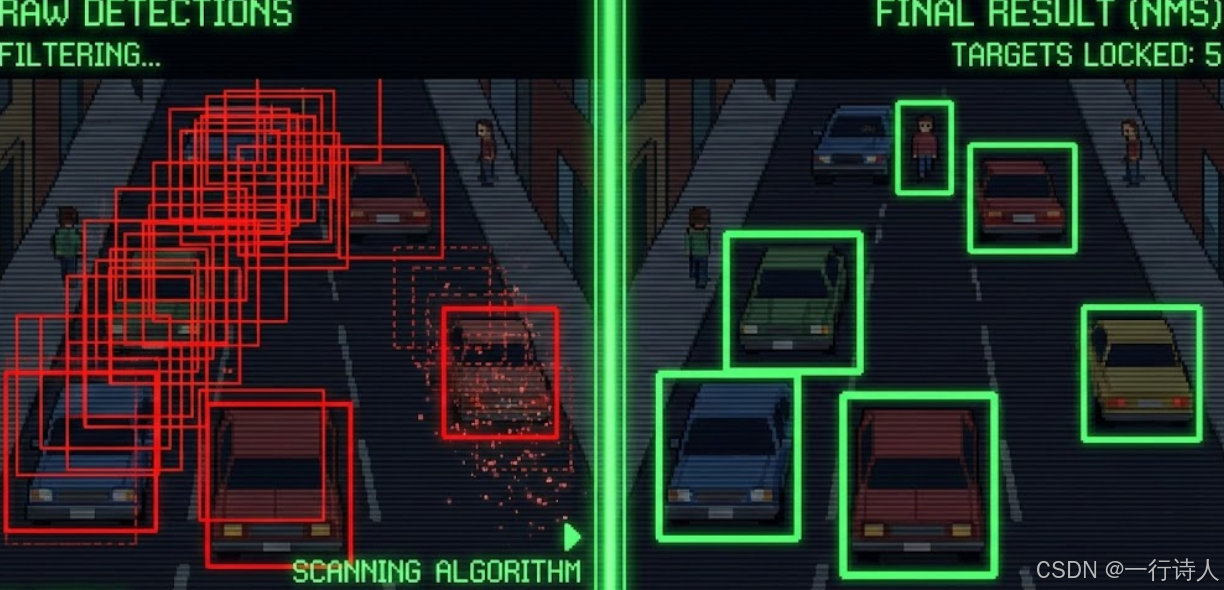
一、 核心图解:像剥洋葱一样过滤
NMS 的过程就像是剥洋葱,一层一层去掉外面的皮(重叠框),只留下核心。
二、 算法优化:并行 IoU + 串行 Mask
既然循环逻辑无法避免,我们就优化循环体内部。 在每一次迭代中,我们需要计算 1 个主框 vs N 个剩余框 的 IoU。这是一个典型的向量运算!
Ascend C 策略:
-
Host 侧/前置算子:先完成 Sort(利用第 41 期学的 Bitonic Sort 或 AI CPU)。
-
Kernel 侧:
-
将排好序的框搬入 UB。
-
利用 Vector 指令一次性计算 128 个 IoU。
-
利用
Compare生成 Mask,更新状态位。
-
三、 实战:Ascend C 实现 NMS
3.1 Kernel 类定义
输入是 boxes $[N, 4]$ 和 scores $[N]$(假设已排序)。输出是 selected_indices。
class KernelNMS {
public:
__aicore__ inline void Init(...) {
// Init...
// 申请 UB 空间存放 Boxes (Proposal)
// 假设 N 较小 (如 2048),可以一次性放入 UB
// 如果 N 很大,需要分块 NMS (这里演示一次性)
}
__aicore__ inline void Process() {
// 1. CopyIn Boxes
DataCopy(boxesLoc, boxesGm, num_boxes * 4);
// 2. 初始化状态 (Keep Mask)
// 全部置为 1 (有效)
Duplicate(keepMask, (uint16_t)1, num_boxes);
// 3. 执行 NMS
ComputeNMS();
// 4. CopyOut Indices
// 根据 keepMask 导出索引
}
};
3.2 Compute 核心逻辑 (IoU 计算)
IoU 计算公式:
$$\text{IoU} = \frac{\text{Inter}}{\text{Area1} + \text{Area2} - \text{Inter}}$$
其中 $\text{Inter} = \max(0, \min(x2_a, x2_b) - \max(x1_a, x1_b)) \times \dots$
我们需要用到大量的 Min, Max, Sub, Mul 指令。
__aicore__ inline void ComputeNMS() {
// 预计算所有框的 Area
// Area = (x2 - x1) * (y2 - y1)
// 这一步是 Vector 并行的
ComputeAllAreas(areaLoc, boxesLoc);
// 主循环:串行遍历每一个框
for (int i = 0; i < num_boxes; i++) {
// 1. 检查当前框 i 是否已被抑制
if (keepMask.GetValue(i) == 0) continue;
// 2. 将当前框 i 广播 (Broadcast)
// currentBox: [x1, y1, x2, y2]
// 我们需要构造 currentBoxVec,让它跟剩余所有 boxes 对齐
// 实际上可以用标量广播指令,或者 Brcb
// 3. 并行计算 IoU (Vector)
// 计算 Inter section
// ix1 = max(box_i_x1, boxes_all_x1)
// iy1 = max(box_i_y1, boxes_all_y1)
// ix2 = min(box_i_x2, boxes_all_x2)
// iy2 = min(box_i_y2, boxes_all_y2)
// Ascend C 伪代码:
// Max(inter_x1, current_x1_brc, all_x1);
// Min(inter_x2, current_x2_brc, all_x2);
// Sub(w, inter_x2, inter_x1);
// Max(w, w, 0); // 负数置0
// IoU = inter_area / (area_i + area_all - inter_area)
// 4. 生成抑制掩码 (Suppress Mask)
// mask = (IoU > thresh)
Compare(suppressMask, iouVec, threshVec, CMP_GT);
// 5. 更新全局 Keep Mask
// 如果 suppressMask 为真,则将对应的 keepMask 置 0
// 注意:只更新 i 之后的框
// keepMask = keepMask & (~suppressMask)
// 这通常需要位运算指令或 Select 指令
// 简单逻辑:如果 IoU > thresh,就把 keepMask 设为 0
// Select(keepMask, suppressMask, 0, keepMask);
}
}
四、 进阶:性能优化的深水区
NMS 的性能瓶颈在于标量(循环控制)与向量(IoU 计算)的频繁交互。
4.1 减少 Scalar 交互
在上面的代码中,keepMask.GetValue(i) 是一个标量读取操作,非常慢。 优化策略:
-
尽量在 Vector 侧维护状态。
-
或者一次处理一个 Block(如 32 个框),如果整个 Block 都被抑制了,就直接跳过。
4.2 坐标精度 (FP16 vs FP32)
检测框坐标对精度敏感。 如果用 FP16 计算 x2 - x1,可能会因为精度不够导致 IoU 计算偏差。 建议:在计算 IoU 的中间步骤(特别是 Area 和 Sub 操作),临时转为 FP32。
4.3 硬件加速指令
部分昇腾芯片(如 Ascend 310)内置了专门的 Region Proposal 硬件单元。 如果你的场景是标准的检测后处理,可以考虑直接调用 acl.op.NMSWithMask 等融合大算子接口,而不是自己手写 Kernel。
五、 总结
NMS 是算法逻辑与硬件特性的博弈。
-
矛盾:串行贪心逻辑 vs 并行硬件架构。
-
解法:“串行遍历主框,并行计算 IoU”。
-
关键:利用 Vector 单元一次算完所有重叠度,而不是一个个算。
攻克了 NMS,你就能处理几乎所有 CV 领域的后处理逻辑,让 AI Core 真正接管端到端流程。

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐


 27
27 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)