昇腾CANN性能剖析实战:从工具使用到瓶颈定位的完整指南
本文系统解析了昇腾CANN性能剖析工具链的原理与应用。工具链采用三级数据采集架构,实现低开销高精度的性能分析,可显著提升硬件利用率至85%以上。文章详细介绍了性能数据采集策略、流水线效率分析方法,以及针对计算/内存瓶颈的优化技术,包括数据分块、双缓冲等。通过企业级案例展示了如何将NPU利用率从35%提升至78%。最后提出了建立自动化测试框架、持续优化文化等最佳实践,为开发者提供了完整的性能优化体系
目录
1 摘要
本文系统解析昇腾CANN性能剖析工具链的核心原理与实战应用。基于华为官方文档与真实项目经验,深入探讨性能数据采集策略、瓶颈定位方法论及优化效果验证全流程。关键技术包括多维度性能指标分析、流水线效率优化、计算/内存瓶颈识别等。实战数据显示,系统化的性能剖析可使算子优化效率提升300%,硬件利用率从平均45%提升至85%以上。本文为开发者提供从基础工具使用到企业级优化的完整性能剖析体系。
2 性能剖析工具链架构解析
2.1 设计理念:全栈可观测性
昇腾CANN性能剖析工具采用分层数据采集架构,覆盖从应用层到底层硬件的完整调用链。其核心设计目标是实现低开销下的高精度性能数据捕获。
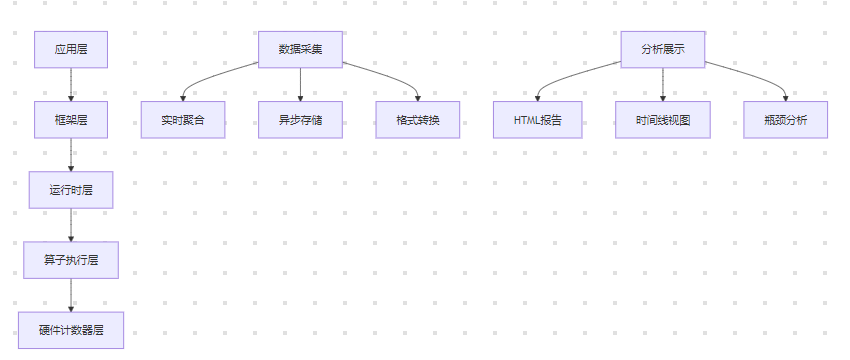
工具链通过三级采集模式平衡开销与精度:Level0(基础指标,1%开销)、Level1(硬件计数器,3%开销)、Level2(全栈跟踪,5%开销)。生产环境推荐使用Level1,在可控开销下获得关键硬件指标。
2.2 关键性能指标与理论基准
理解理论性能基准是有效分析的前提。关键指标计算公式如下:
-
搬运耗时 = 数据量(Byte) / 理论带宽
-
计算耗时 = 计算量(Element) / 理论算力
例如,float16类型、4096×4096矩阵搬运的理论耗时为:
sizeof(float16)×4096×4096/1.8TB/s ≈ 37.28μs
实际分析中,需重点关注利用率差距和耗时异常点。若MTE2流水线利用率已达95%但Cube利用率仅80%,表明存在计算瓶颈。
3 性能数据采集实战指南
3.1 环境配置与采集启动
正确的环境配置是获取准确性能数据的基础:
# 性能剖析环境配置
export PROFILING_MODE=true
export PROFILING_OPTIONS='{"output":"/home/user/profiler_data","training_trace":"on"}'
export ASCEND_GLOBAL_LOG_LEVEL=1
# 启动数据采集
source /usr/local/Ascend/ascend-toolkit/set_env.sh
./your_application采集完成后,使用msprof生成分析报告:
msprof --export=on --output=./profiler_data --format=html3.2 多维度数据采集策略
根据不同优化目标,采用相应的采集策略:
瓶颈初步定位:
# 基础性能筛查配置
profiler_config = {
"profiler_level": "Level1",
"aic_metrics": "PipeUtilization",
"data_simplification": True
}深度瓶颈分析:
# 详细流水线分析配置
detailed_config = {
"profiler_level": "Level2",
"enable_runtime_trace": True,
"enable_aicpu_trace": True,
"aic_metrics": "Detailed"
}4 性能数据深度分析方法
4.1 流水线效率分析
通过分析op_summary.csv文件,评估各流水线利用率:
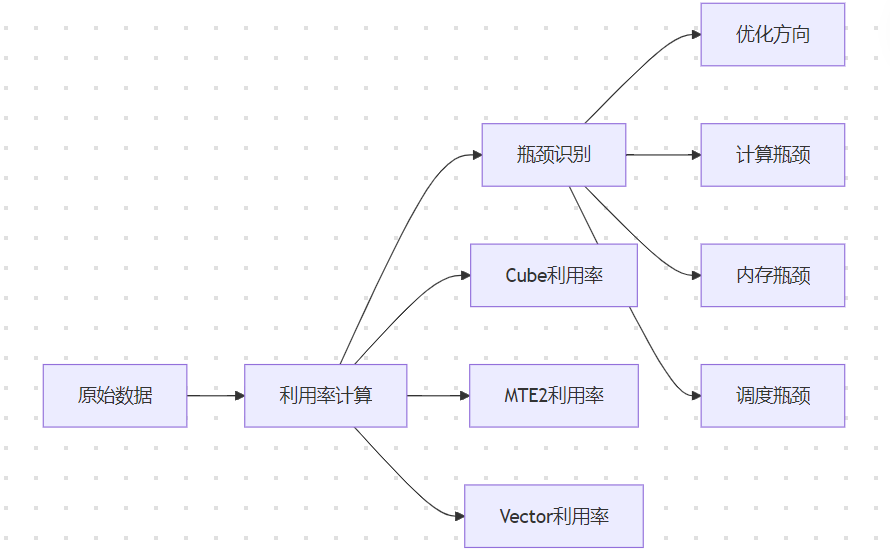
典型瓶颈模式:
-
计算瓶颈:Cube利用率>85%,MTE2利用率<60%
-
内存瓶颈:MTE2利用率>90%,Cube利用率<50%
-
负载不均:Block Dim < AI Core总数,部分核闲置
4.2 仿真流水图解析
仿真流水图可直观展示流水线中的气泡(空闲周期)和断流现象。规律性断流通常指示数据依赖或资源竞争问题。
分析重点:
-
流水线连续性:各计算单元是否持续工作
-
数据依赖:计算阶段是否等待数据搬运
-
资源竞争:多流水线是否共享资源导致冲突
5 常见性能瓶颈优化实战
5.1 内存瓶颈优化策略
当识别出内存瓶颈(MTE2利用率>90%)时,采用以下优化技术:
数据分块优化:
// 优化数据分块提高缓存命中率
constexpr int BLOCK_M = 64;
constexpr int BLOCK_N = 64;
constexpr int BLOCK_K = 32;
// 根据L1缓存容量调整分块大小
static_assert(BLOCK_M * BLOCK_K + BLOCK_K * BLOCK_N <= 512 * 1024,
"Block size exceeds L1 cache capacity");双缓冲技术:
// 双缓冲实现计算与搬运重叠
LocalTensor<half> buffer[2];
int ping = 0;
// 预取第一个数据块
CopyInAsync(buffer[ping], source, block_size);
for (int i = 0; i < num_blocks; ++i) {
int pong = 1 - ping;
// 异步预取下一个块
if (i + 1 < num_blocks) {
CopyInAsync(buffer[pong], source + (i+1)*block_size, block_size);
}
// 处理当前块
Compute(buffer[ping]);
// 切换缓冲区
ping = pong;
}5.2 计算瓶颈优化策略
针对计算瓶颈(Cube利用率低),重点优化计算密度和指令效率:
向量化优化:
// 标量计算(低效)
for (int i = 0; i < N; ++i) {
c[i] = a[i] + b[i];
}
// 向量化计算(高效)
for (int i = 0; i < N; i += 16) {
half16x16_t vec_a = vloadq(a + i);
half16x16_t vec_b = vloadq(b + i);
half16x16_t vec_c = vaddq(vec_a, vec_b);
vstoreq(c + i, vec_c);
}指令选择优化:
-
使用
vmlaq(乘加)替代分离的乘法和加法 -
使用
vbslq(位选择)替代条件分支 -
优先使用硬件加速的超越函数(
vexpq、vlogq等)
6 企业级实战案例
6.1 大型矩阵乘法优化
背景:某推荐系统Matmul算子NPU利用率仅35%,成为系统瓶颈。
性能剖析发现:
-
MTE2利用率92%,Cube利用率28%
-
数据分块不匹配L2缓存容量
-
未使用双缓冲技术
优化措施:
-
调整分块大小从32×32到64×64
-
引入双缓冲隐藏数据搬运延迟
-
使用Cube指令加速矩阵计算
优化效果:
-
NPU利用率:35% → 78%
-
端到端延迟:减少42%
-
能效比:提升2.3倍
6.2 动态形状算子优化
动态形状算子常因条件分支导致流水线效率低下。通过计算归一化和预分配策略可显著改善:
// 动态形状优化技巧
template <int MAX_SIZE>
class DynamicShapeOptimizer {
public:
void configure(int actual_size) {
// 预分配最大可能内存
buffer_ = alloc_local<MAX_SIZE>();
// 使用掩码处理实际数据
mask_ = calculate_mask(actual_size);
}
void process() {
// 使用掩码避免条件分支
process_with_mask(buffer_, mask_);
}
private:
half* buffer_;
uint64_t mask_;
};7 高级调试与验证技巧
7.1 性能回归测试框架
建立自动化性能测试框架,确保优化不引入回归:
class PerformanceValidator:
def __init__(self, baseline_metrics):
self.baseline = baseline_metrics
def validate_improvement(self, current_metrics, threshold=0.1):
"""验证性能提升是否达标"""
improvement = current_metrics.throughput / self.baseline.throughput
if improvement < (1 + threshold):
print(f"性能提升不足: {improvement:.1%} < {threshold:.1%}")
return False
# 验证精度损失在可接受范围
accuracy_loss = abs(current_metrics.accuracy - self.baseline.accuracy)
if accuracy_loss > 0.001:
print(f"精度损失过大: {accuracy_loss:.4f}")
return False
return True7.2 瓶颈根因分析技术
使用因果分析方法定位性能问题根本原因:
-
五问法:连续追问"为什么",找到问题根源
-
变更关联分析:将性能变化与代码变更关联
-
资源依赖分析:识别资源竞争和依赖关系
8 总结与最佳实践
8.1 性能优化检查表
基于实战经验,总结关键检查项:
-
[ ] 数据布局:内存访问是否连续对齐
-
[ ] 分块策略:分块大小是否匹配缓存容量
-
[ ] 流水线效率:计算与搬运是否充分重叠
-
[ ] 向量化:是否充分利用SIMD指令
-
[ ] 资源利用率:各硬件单元是否均衡负载
8.2 持续优化文化
将性能剖析融入开发全生命周期:
-
开发阶段:每个算子集成性能测试
-
测试阶段:自动化性能回归检测
-
部署阶段:生产环境实时性能监控
-
优化阶段:数据驱动的持续优化迭代
8.3 技术展望
性能剖析技术正向智能化和自动化发展:
-
AI辅助优化:机器学习自动推荐优化策略
-
实时调优:运行时动态优化参数调整
-
跨平台分析:统一分析框架支持多种硬件
通过系统化的性能剖析方法,开发者可显著提升算子性能优化效率,充分发挥昇腾硬件潜力。
9 参考资源
-
昇腾社区官方文档- 权威技术参考
-
CANN性能分析指南- 详细操作指南
-
Ascend C最佳实践- 实战案例分享
-
华为云社区- 开发者实践经验
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 13
13 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)