Ascend C 算子开发全流程揭秘 - 从 msopgen 到精度校验
本文系统介绍了昇腾AI处理器上基于AscendC的自定义算子全流程开发方法。首先阐述了msopgen工具链的核心作用,解析了其生成的标准项目结构;深入讲解了AscendC算子的三层流水线架构原理(Copy-In、Compute、Copy-Out)。通过构建Add算子的实战案例,详细展示了从工程生成、内核函数实现到主机端调用的完整开发过程,并重点强调了精度校验作为质量保障的关键环节。文章还提供了企业
目录
3.2. ⚙️ 灵魂所在:三层流水线(Three-Stage Pipeline)
4.2. Step 2: 实现内核函数(Kernel Implementation)
4.3. Step 3: 主机端调用器(Host Runner)
5.1. 黄金参考(Golden Reference)对比法
6.3. 🐞 常见问题排查(Troubleshooting)
1. 引言:为何要关注“全流程”?
在昇腾(Ascend)AI处理器上开发自定义算子,Ascend C 是当仁不让的首选。但很多开发者初接触时,容易陷入一个误区:以为算子开发就等于编写内核函数(Kernel Function)。这大错特错。
一个在生产环境可用的算子,其开发流程是一个系统工程。它关乎可维护性、可测试性、可集成性以及最终的性能。回想一下图片开头的“互动问题”,它实际上点出了核心:工程化算子开发流程是怎样的? 今天,我们就来彻底回答这个问题。
核心价值:本文将带你俯瞰从 msopgen工具链生成工程骨架,到编写精度校验脚本的完整闭环。你会掌握一套标准化的方法论,从而能高效、可靠地开发出属于你自己的高性能算子。
2. 初识基石:msopgen 工具链的核心作用
2.1. 🤖 什么是 msopgen?
简单来说,msopgen是 Ascend C 算子开发的 “脚手架”(Scaffolding)生成器。它是一个命令行工具,接受一个 XML 格式的算子描述文件(如 add_op.xml),然后自动生成一个完整、规范的算子工程目录结构。
它的设计理念是“约定优于配置”(Convention Over Configuration)。这意味着工具强制你按照一种最佳实践的方式来组织代码,避免了项目结构的混乱,极大降低了后续的集成和调试成本。
2.2. 🏗️ msopgen 生成的项目结构解析
运行 msopgen -i add_op.xml -o . -l cpp后,你会得到一个如下所示的典型工程结构(基于图片中的“AclnnInvocation工程”进行增强说明):
add_op/
├── op_kernel/ # 算子内核实现
│ ├── add_kernel.h # 内核函数头文件
│ └── add_kernel.cpp # 内核函数实现文件
├── op_proto/ # 算子原型定义
│ └── add_op.proto
├── op_runner/ # 算子的主机端(Host)调用器
│ ├── op_runner.h
│ └── op_runner.cpp # 关键!封装设备内存、流水线任务等
├── framework/ # 一些通用的框架代码
├── build.sh # 自动化编译脚本
├── cmake/ # CMake 构建配置
└── requirements.txt # Python 依赖(用于后续的测试脚本)这个结构的意义在于:
-
隔离性:内核代码(
op_kernel)与主机端调用代码(op_runner)分离,符合异构计算编程范式。 -
标准化:CANN 软件栈期望算子以这种形式被识别和集成。
-
自动化:
build.sh脚本内部处理了复杂的依赖和编译选项,你只需一条命令即可编译。
下面的 Mermaid 流程图展示了 msopgen在算子开发生命周期中的关键定位:
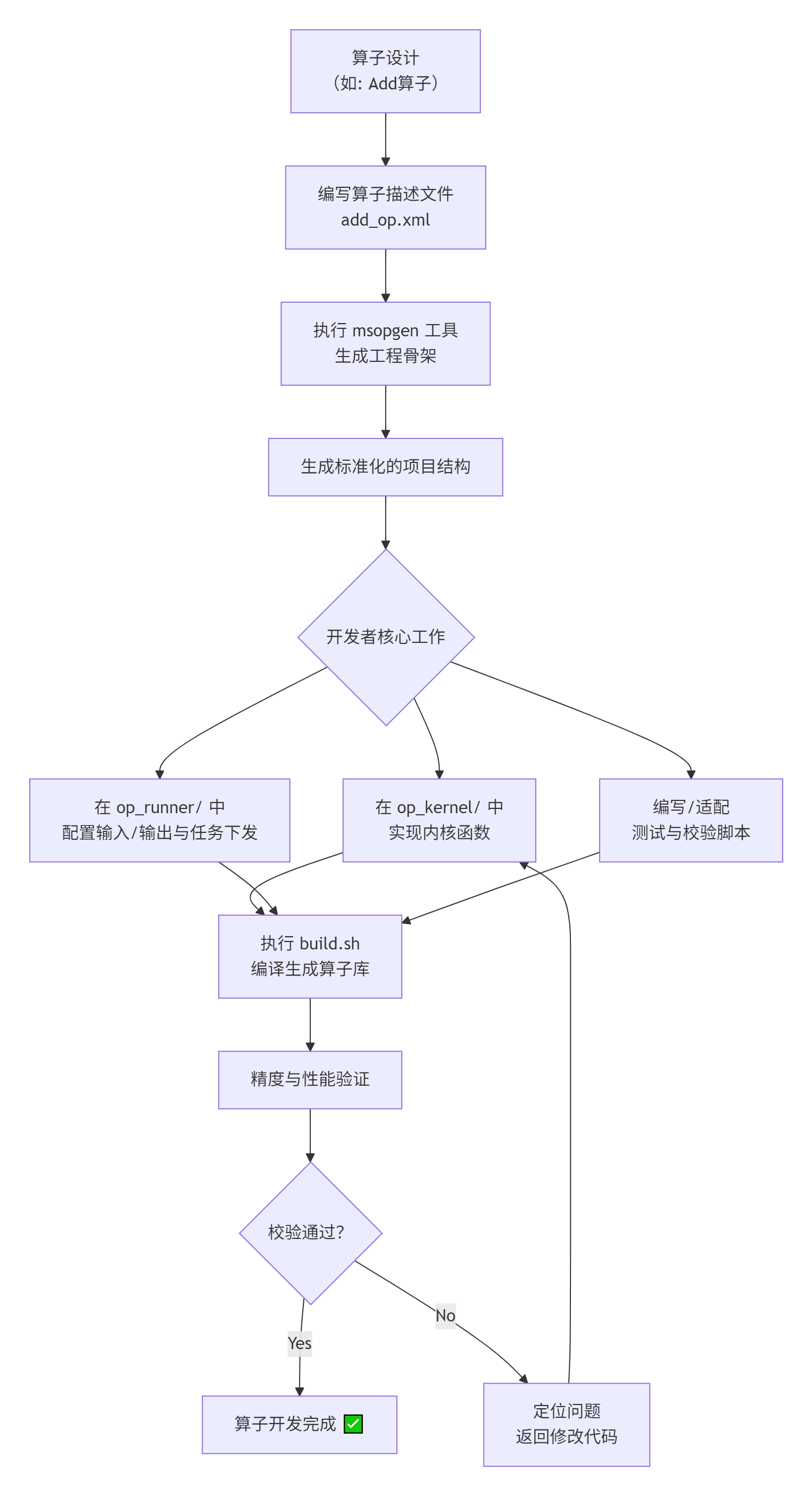
3. 核心原理:Ascend C 算子架构与三层流水线
3.1. 🧠 异构计算编程模型
在 Ascend C 中,编程模型遵循典型的主机-设备(Host-Device) 模式。
-
Host(主机):指 x86/ARM CPU。它负责控制流,管理设备内存的分配与释放,以及向设备下发计算任务。
-
Device(设备):指昇腾 AI Core。它执行计算密集的核心算子和向量运算。
两者通过异步任务队列进行通信。Host 下发任务后不会傻等,而是可以继续处理其他工作,从而实现计算与通信的重叠,这是高性能的关键。
3.2. ⚙️ 灵魂所在:三层流水线(Three-Stage Pipeline)
这是 Ascend C 高性能的核心设计。它将一个算子的执行过程精妙地划分为三个相互重叠的阶段:
-
Copy-In(数据搬入):将输入数据从外部存储(External Memory)(如DDR)搬运到片上缓冲(Unified Buffer)。
-
Compute(计算):在 AI Core 的计算单元(Cube Unit, Vector Unit) 上,利用片上数据进行计算。
-
Copy-Out(结果搬出):将计算结果从片上缓冲搬运回外部存储。
为什么是“流水线”?
因为这三个阶段可以像工厂流水线一样并行工作。当第 N 次迭代在进行 Compute 时,第 N+1 次迭代的 Copy-In 和第 N-1 次迭代的 Copy-Out 可以同时进行。这极大地隐藏了数据搬运的延迟,使得计算单元几乎时刻处于“饱腹”工作状态。
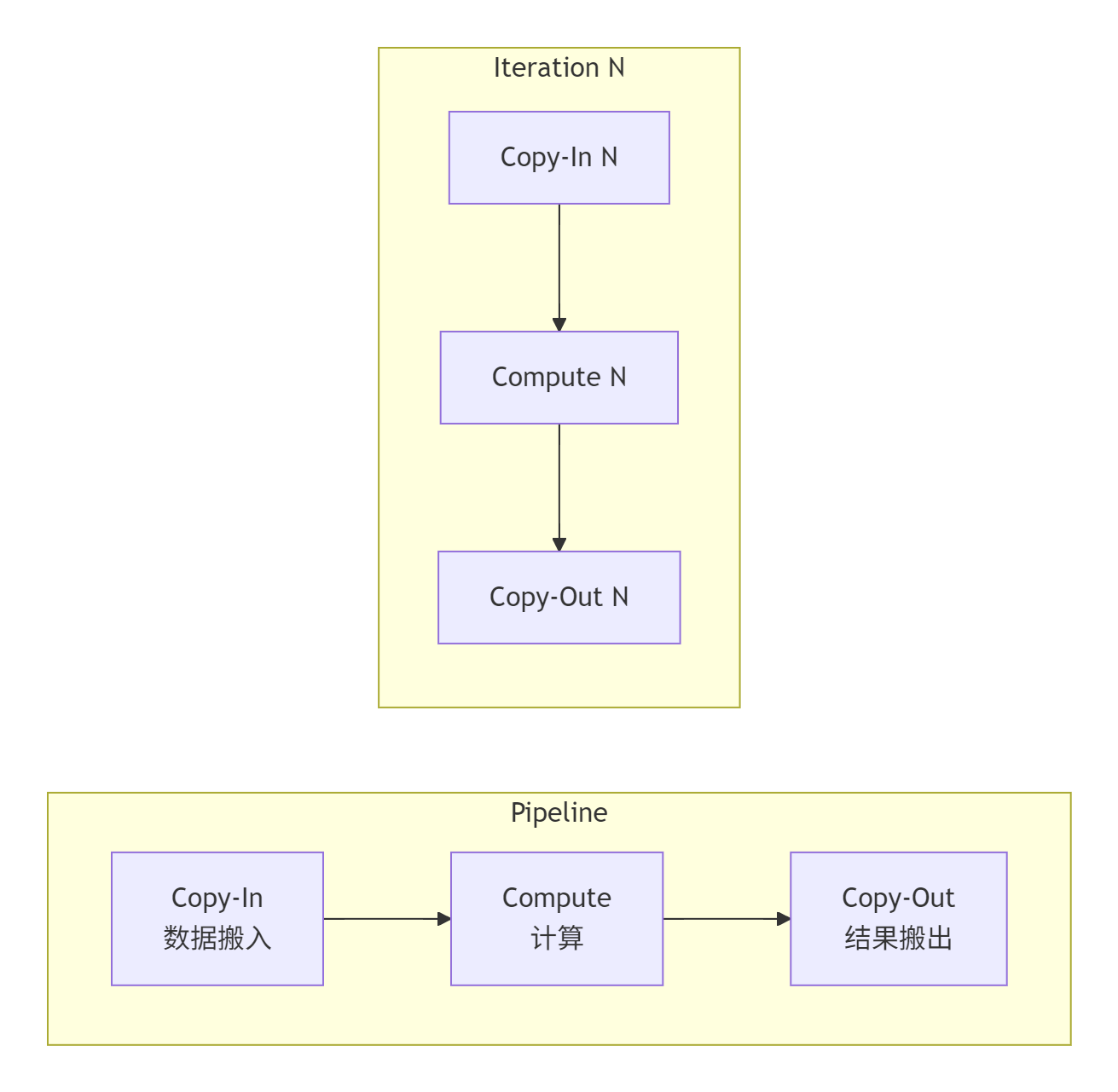
图示:理想状态下,三次迭代在流水线中的重叠执行情况
4. 实战演练:构建一个完整的 Add 算子
现在,我们以图片中提到的 Add功能为例,串联整个流程。
4.1. Step 1: 定义算子并生成工程
首先,我们需要一个简单的 XML 描述文件 add_op.xml:
<?xml version="1.0" encoding="UTF-8"?>
<op>
<name>Add</name>
<input>
<name>x1</name>
<dtype>float16</dtype> <!-- 使用AI核心偏好的FP16 -->
<format>ND</format>
</input>
<input>
<name>x2</name>
<dtype>float16</dtype>
<format>ND</format>
</input>
<output>
<name>y</name>
<dtype>float16</dtype>
<format>ND</format>
</output>
<kernel>
<name>AddKernel</name>
</kernel>
</op>使用命令生成工程:msopgen -i add_op.xml -o ./add_project -l cpp
4.2. Step 2: 实现内核函数(Kernel Implementation)
在 op_kernel/add_kernel.cpp中,我们需要实现核心逻辑。这里可以看到 Ascend C 特有的编程接口。
// add_kernel.cpp
#include "add_kernel.h"
#include "acl/acl.h"
#include "aclrt/aclrt.h"
// 使用 Ascend C 命名空间
using namespace AscendC;
// 内核类,继承自 AscendC::Kernel
class AddKernel {
public:
__aicore__ inline AddKernel() {}
// 初始化函数,用于设置输入输出Tiling信息等
__aicore__ inline void Init(AddParam param) {
this->param = param;
}
// 核心处理函数
__aicore__ inline void Process() {
// 1. 为输入输出数据在片上分配Pipe(流水线)内存块
LocalTensor<half> x1Local = x1GM.GetLocalTensor();
LocalTensor<half> x2Local = x2GM.GetLocalTensor();
LocalTensor<half> yLocal = yGM.GetLocalTensor();
// 2. 数据搬入 (Copy-In Stage)
DataCopy(x1Local, x1GM);
DataCopy(x2Local, x2GM);
// 3. 计算 (Compute Stage): 简单的逐元素加法
for (int i = 0; i < param.length; i++) {
yLocal[i] = x1Local[i] + x2Local[i];
}
// 4. 结果搬出 (Copy-Out Stage)
DataCopy(yGM, yLocal);
}
private:
AddParam param;
// 使用GlobalMemory指针指向设备上的输入输出数据
GlobalTensor<half> x1GM, x2GM, yGM;
};
// 核函数入口,由运行时系统调用
extern "C" __global__ __aicore__ void Add(AddParam param) {
AddKernel kernel;
kernel.Init(param);
kernel.Process();
}代码解读:
-
__aicore__是 Ascend C 的关键字,表明函数在设备端 AI Core 上执行。 -
LocalTensor和GlobalTensor是核心抽象,分别代表片上快存和片外大存。 -
Process函数清晰地体现了三层流水线的编程范式。
4.3. Step 3: 主机端调用器(Host Runner)
图片中重点展示了 op_runner.cpp。它的职责是:
-
分配设备内存:使用
aclrtMalloc。 -
准备数据:将 Host 上的输入数据拷贝到 Device。
-
设置内核参数:并下发内核函数到设备执行。
-
同步等待:任务下发是异步的,需要显式同步以确保完成。
-
取回结果:将 Device 上的结果拷贝回 Host。
关键代码片段(基于图片内容重构):
// op_runner.cpp (关键部分)
#include "acl/acl.h"
#include "op_runner.h"
bool AddRunner::Run() {
// 1. 内存分配
aclrtMalloc((void**)&x1Dev_, dataSize_, ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMalloc((void**)&x2Dev_, dataSize_, ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMalloc((void**)&yDev_, dataSize_, ACL_MEM_MALLOC_HUGE_FIRST);
// 2. 数据H2D (Host to Device)
aclrtMemcpy(x1Dev_, dataSize_, x1Host_, dataSize_, ACL_MEMCPY_HOST_TO_DEVICE);
aclrtMemcpy(x2Dev_, dataSize_, x2Host_, dataSize_, ACL_MEMCPY_HOST_TO_DEVICE);
// 3. 设置内核参数块
AddParam param = { .length = totalLength_ };
param.x1 = x1Dev_;
param.x2 = x2Dev_;
param.y = yDev_;
// 4. 下发内核任务(使用Aclnn接口或更底层的rtKernelLaunch)
// 此处是流程关键,具体API调用与版本相关
ACLNN_ADD_INVOKE(param, stream_); // 伪代码,示意Aclnn接口调用
// 5. 流同步
aclrtSynchronizeStream(stream_);
// 6. 结果D2H (Device to Host)
aclrtMemcpy(yHost_, dataSize_, yDev_, dataSize_, ACL_MEMCPY_DEVICE_TO_HOST);
return true;
}5. 质量保障:精度校验——算子开发的“生死线”
一个算子上线前,必须证明其计算结果是正确的。这就是图片中 verify_result.py脚本的使命。
5.1. 黄金参考(Golden Reference)对比法
核心思想:在 Host 端(通常用 NumPy)实现一个逻辑相同但简单可靠的算法作为“标准答案”,然后将 Ascend C 算子的结果与之对比。
# verify_result.py
import numpy as np
import sys
def golden_ref_add(x1, x2):
"""黄金参考:使用NumPy实现加法"""
return x1 + x2
def verify(ascend_c_result_path, golden_result_path):
"""精度校验函数"""
# 读取Ascend C算子的计算结果
ascend_c_result = np.fromfile(ascend_c_result_path, dtype=np.float16)
# 读取之前生成的黄金参考结果
golden_result = np.fromfile(golden_result_path, dtype=np.float16)
# 计算绝对误差和相对误差
abs_diff = np.abs(ascend_c_result - golden_result)
rel_diff = abs_diff / (np.abs(golden_result) + 1e-9) # 防止除零
max_abs_error = np.max(abs_diff)
max_rel_error = np.max(rel_diff)
print(f"最大绝对误差: {max_abs_error}")
print(f"最大相对误差: {max_rel_error}")
# 设定误差容限(Threshold)
abs_threshold = 1e-3
rel_threshold = 1e-3
if max_abs_error < abs_threshold and max_rel_error < rel_threshold:
print("✅ 精度验证通过!")
return True
else:
print("❌ 精度验证失败!")
# 可以打印出误差最大的前几个点,辅助调试
return False
if __name__ == "__main__":
verify("./result/ascend_c_add_result.bin", "./data/golden_ref_result.bin")经验之谈:
-
误差阈值的选择至关重要,需要根据数据类型(FP16/FP32)和算子特性来定。FP16 的误差通常比 FP32 大。
-
如果校验失败,脚本是第一道防线。接下来需要结合 Debug 工具(如 printf 调试、Ascend Debugger)定位是内核代码的哪个部分出了问题。
6. 高级应用与避坑指南
6.1. 🚀 企业级实践:持续集成(CI)中的算子测试
在正规团队中,gen_data.py和 verify_result.py不会只在你本地运行。它们应该被集成到 CI(如 Jenkins、GitLab CI)流水线中。每次代码提交,都会自动触发一组包含多种输入规模(大、中、小、特殊尺寸)和数据类型的测试用例,确保代码修改不会引入回归错误。
6.2. 🔧 性能优化初探
-
Tiling 策略:对于大尺寸数据,需要分块(Tiling)处理以适配有限的片上存储。如何分块是性能优化的首要问题。
-
双缓冲(Double Buffer):这是流水线的进阶技巧,通过分配两套缓冲区,使得 Copy-In 和 Compute 能更加彻底地重叠,进一步压榨硬件性能。
6.3. 🐞 常见问题排查(Troubleshooting)
-
编译错误
undefined reference: 99% 的原因是build.sh的链接参数不对,检查是否包含了所有必要的库文件(.a或.so)。 -
运行时报错
ACL_ERROR_RT_PARAM: 内核参数(Param)传递有问题,检查 Host 与 Device 代码中的结构体定义是否完全一致(特别是数据指针类型)。 -
精度校验失败,但误差不大: 首先怀疑是黄金参考的实现逻辑与内核逻辑有细微差别,比如计算顺序、精度累加方式等。
-
性能不及预期: 使用 Ascend Profiler 性能分析工具,查看 AI Core 的利用率是否过低,分析是内存带宽受限还是计算瓶颈。
7. 总结与展望
本文系统性地拆解了 Ascend C 算子开发的全流程。我们揭示了:
-
msopgen 是标准化和工程化的起点。 -
三层流水线是 Ascend C 高性能的灵魂架构。
-
内核函数与主机端调用器的分离是异构编程的基本法。
-
精度校验是保证算子正确性的生命线。
将以上环节串联起来,你就拥有了在昇腾平台上创造高性能算子的基本能力。然而,这仅仅是开始。后续我们将深入探讨 Aclnn 接口的设计哲学、Pybind 的集成技巧,以及更复杂的性能优化战术。
讨论点:在你的实际项目中,遇到的最棘手的算子集成问题是什么?是精度调优,还是性能瓶颈的定位?欢迎在评论区分享,我们一起探讨。
参考链接
-
昇腾社区: 获取CANN工具包、文档和论坛支持的官方门户。
-
Ascend C 算子开发指南: 官方最全面的开发文档(需登录)。
-
msopgen 工具使用说明: 详细参数说明和示例。
-
Ascend C API 参考: 查询所有内置函数和数据类型。
-
模型精度比对工具使用方法: 官方提供的更强大的精度调试工具文档。
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 23
23 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)