深入解析华为CANN算子开发:向量加法算子实战与优化
硬件方面,开发者可选择Atlas 300I Pro推理卡或Atlas 800T A2训练服务器,并确保NPU状态正常。软件环境推荐使用CANN 6.3版本及以上,搭配Ascend C Toolkit。编译工具方面,CMake建议使用3.15+,GCC版本在7.3.0至9.4.0之间,以避免语法兼容问题。辅助工具包括npu-smi用于监控硬件状态、ascend-debugger用于内核调试,以及Go
深入解析华为CANN算子开发:向量加法算子实战与优化
在人工智能加速计算领域,华为Ascend系列AI处理器提供了强大的NPU计算能力,而CANN(Compute Architecture for Neural Networks)为开发者提供了完整的算子开发与优化框架。本文以向量加法(Vector Add)算子为例,结合CANN 6.x版本的环境与工具链,详细介绍算子开发流程、Tiling策略设计、Kernel优化、主机端调度以及测试验证,帮助开发者深入理解Ascend算子的实战开发方法。
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
一、环境准备与工程配置实战
算子开发的第一步是确保环境和工程结构的合理性。Ascend AI Core算子开发对硬件、软件和工具链都有严格要求。
1.1 精准的开发环境
硬件方面,开发者可选择Atlas 300I Pro推理卡或Atlas 800T A2训练服务器,并确保NPU状态正常。软件环境推荐使用CANN 6.3版本及以上,搭配Ascend C Toolkit。编译工具方面,CMake建议使用3.15+,GCC版本在7.3.0至9.4.0之间,以避免语法兼容问题。辅助工具包括npu-smi用于监控硬件状态、ascend-debugger用于内核调试,以及Google Test进行单元测试。
1.2 工程目录优化设计
一个清晰且企业级规范的工程目录,有助于开发与维护。向量加法算子工程结构如下:
vector_add_tiling/
├── CMakeLists.txt
├── include/
│ ├── vector_add_op.h
│ └── tiling_config.h
├── kernel/
│ ├── vector_add_kernel.cc
│ └── kernel_utils.h
├── host/
│ ├── vector_add_host.cc
│ └── main.cpp
├── tests/
│ ├── unit_test/
│ │ └── test_vector_add.cpp
│ └── benchmark/
│ └── perf_test.cpp
├── scripts/
│ ├── build.sh
│ └── run_test.sh
└── docs/
└── api_description.md
其中 docs 用于存放接口文档,benchmark 用于性能测试脚本,这种结构利于大型团队协作。
1.3 CMakeLists.txt 配置优化
CMake配置不仅要支持设备端内核编译,还需增强工程健壮性,例如环境变量检查、库依赖查找及安装规则。核心点包括:
- 强制使用C++11标准,保证Ascend C内核编译要求。
- 检查 ASCEND_HOME 环境变量,避免依赖全局配置。
- 根据系统位数查找库路径,确保 32/64 位自适应。
- 设备端代码使用
aarch64-target-linux-gnu-g++编译,支持优化选项。 - 将设备端内核对象文件嵌入主机端可执行程序。
此外,开发者需注意 LD_LIBRARY_PATH 包含 CANN lib64 目录,并确保 GCC 版本匹配,否则会出现编译或运行时错误。
二、Tiling策略设计与实现
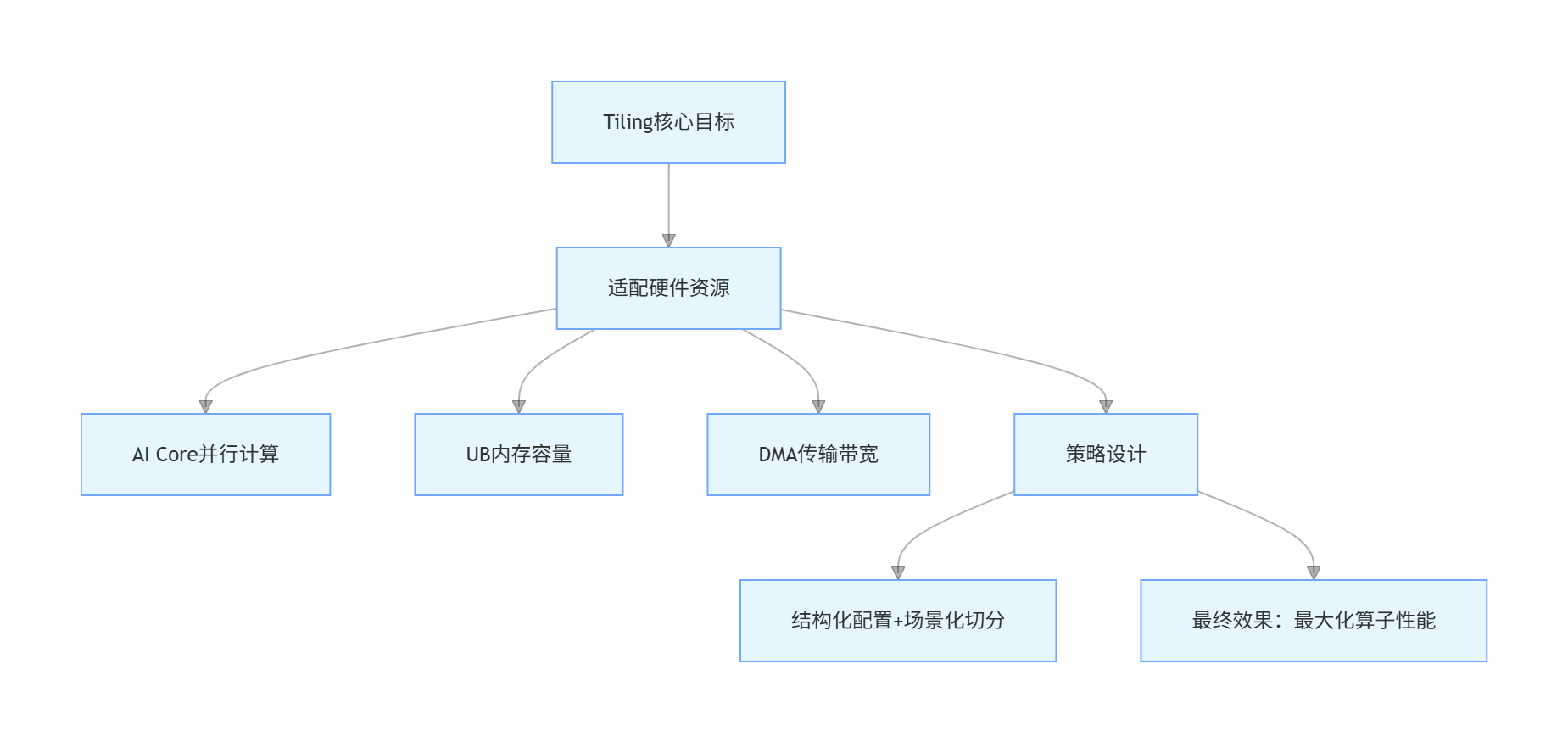
Tiling是Ascend算子优化的核心,主要目的是适配硬件资源,充分利用AI Core并行计算能力、UB内存容量及DMA传输带宽。
2.1 Tiling配置结构设计
增强型Tiling数据结构不仅包含向量长度和块数,还结合硬件特性与优化参数:
typedef struct {
int32_t total_len;
int32_t tile_count;
int32_t tile_base_len;
int32_t tile_last_len;
int32_t data_type_bytes;
int32_t ai_core_num;
int32_t ub_total_size;
int32_t ub_reserve_size;
int32_t align_bytes;
int32_t double_buf_len;
bool is_align_enable;
bool is_double_buf_enable;
} VectorAddTilingCfg;
支持多种策略,包括简单均匀切分、负载均衡切分、内存对齐切分、双缓冲切分以及性能优先策略,通过动态计算硬件参数选择最优切分方式。
2.2 多场景Tiling策略实现
在性能优先策略中,算子会根据向量长度动态选择切分策略:
- 小规模数据:使用简单切分,减少调度开销。
- 中规模数据:采用内存对齐切分,提高访存效率。
- 大规模数据:使用双缓冲切分,掩盖DMA传输延迟。
策略实现中,需保证块数不超过AI Core数量,避免调度开销过高;双缓冲长度需适配UB内存,避免溢出;内存对齐可减少访存效率损失,提升计算吞吐。
三、设备端Kernel深度实现
Kernel是算子在NPU上的执行核心,其设计直接影响性能。
3.1 内核优化与边界处理
基础向量加法函数适用于小规模块,但在实际应用中必须处理对齐和越界:
static __aicore__ void vector_add_aligned(const float* a, const float* b, float* c, int32_t len, int32_t total_len) {
typedef float V8F32 __attribute__((vector_size(32)));
const V8F32* a_vec = reinterpret_cast<const V8F32*>(a);
const V8F32* b_vec = reinterpret_cast<const V8F32*>(b);
V8F32* c_vec = reinterpret_cast<V8F32*>(c);
// 向量计算
...
// 处理剩余元素
...
}
对于大规模数据,还可利用双缓冲机制掩盖DMA传输延迟,确保计算与数据传输并行进行。
3.2 Kernel开发关键点
- UB内存管理:通过
ub_alloc分配,使用后必须释放。 - 向量指令:EU支持8路 float32 并行计算,可显著提高吞吐。
- DMA传输同步:异步传输必须使用
pipeline_wait()等待完成。 - 边界处理:对齐后可能超出总长度,需要过滤无效索引,避免内存越界。
四、主机端算子调度实现
主机端负责算子初始化、内存管理、Tiling策略计算、Kernel启动及结果回传。
4.1 主机端算子类设计
主机端使用 C++ 封装算子类 VectorAddOp,提供统一接口:
int32_t Run(const std::vector<float>& a,
const std::vector<float>& b,
std::vector<float>& c,
TilingStrategyType strategy = TILING_STRATEGY_PERF);
主要流程包括:
- 初始化CANN运行环境和计算流。
- 计算并验证Tiling策略。
- 分配设备端内存并拷贝数据。
- 启动Kernel。
- 拷贝结果回主机。
同时提供 Benchmark 方法进行性能测试,支持预热和重复执行,确保测试结果稳定。
4.2 主机端开发注意事项
- 释放资源顺序:先流、再上下文、最后关闭设备。
- 内存分配标志结合大页和对齐,优化访存。
- 异步操作必须同步,否则会读取脏数据。
- 性能测试需预热,排除初始化开销干扰。
五、测试验证与性能分析
测试覆盖功能正确性、边界场景及性能指标,是算子开发不可或缺的一环。
- 单元测试:基于Google Test,随机生成向量,验证加法结果。
- 性能测试:通过多次重复计算获取平均执行时间,评估Tiling策略与Kernel优化效果。
测试过程中需关注边界处理、对齐策略以及双缓冲是否正常工作,确保算子在各种规模下均能稳定运行。
总结
华为CANN算子开发涉及从环境准备、工程设计、Tiling策略到Kernel优化及主机端调度的全链路流程。本文通过向量加法算子实战,深入剖析了:
- 环境配置及工程目录规范化
- Tiling策略设计与多场景适配
- Kernel的向量化与双缓冲优化
- 主机端算子类封装与调度流程
- 测试与性能验证实践
掌握这些技巧后,开发者能够在Ascend AI Core上高效实现复杂算子,充分发挥硬件性能,为AI应用提供稳定可靠的计算基础。

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 8
8 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)