CANN开发者炼成之路:从“胶水代码”到“炼金术”——我的第一个高性能融合算子诞生记
引子:那遥不可及的性能天花板
在CANN训练营的征途上,我们一路打怪升级,从掌握CPU与NPU的思维差异,到精通Tiling的排兵布阵,再到手持Profiler这把利器洞察性能的蛛丝马迹。我曾一度认为,只要将模型中的每一个算子都优化到极致,就能触及性能的“天花板”。
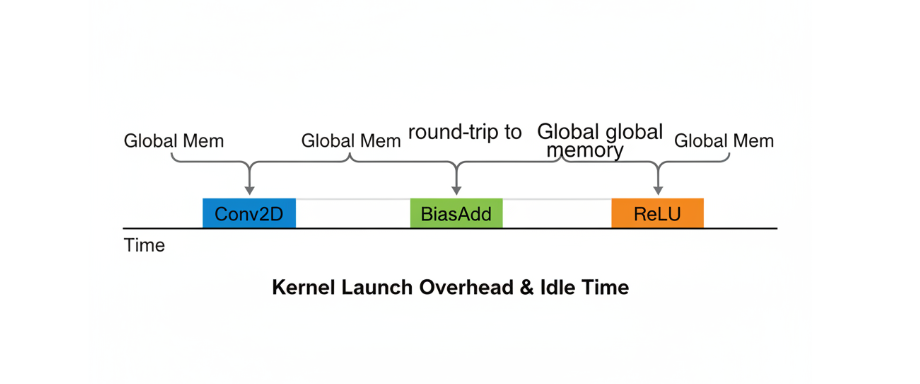
然而,当我将一个经典的CNN模型部署到昇腾芯片上,并用Profiler进行全局分析时,一个残酷的现实摆在了面前:尽管我优化的卷积(Conv)、加偏置(BiasAdd)、激活(ReLU)等每一个算子都快如闪电,但整个模型的端到端(End-to-End)时延依然不尽人意。
Profiler的Timeline视图揭示了问题的根源:在卷积、加偏置、激活函数这三个连续的操作之间,存在着明显的、肉眼可见的“空隙”。这些空隙,是Kernel Launch(核函数启动)的开销,更是数据在完成一次计算后,被送回遥远的Global Memory(全局内存),再被下一个算子重新读取回来的漫长旅途。我的模型,就像一个由无数顶级零件组装而成,却用低效的“胶水”粘合起来的机器,性能在一次次的数据往返中被无情地消耗掉了。
我意识到,要突破这层天花板,我需要掌握一种更高级的技艺,一种能将“零件”熔炼于一炉的“炼金术”——算子融合(Operator Fusion)。这篇笔记,便是我第一次尝试将Conv2D、BiasAdd和ReLU这三个最常见的操作,熔炼成一个单一、高效的“黄金算子”的完整记录。

第一章:“胶水代码”的困境 —— 分离式实现的性能原罪
在融合之前,我们必须深刻理解“不融合”错在哪里。一个标准的CNN层,其计算流通常是 Output = ReLU(Conv2D(Input, Weight) + Bias)。用最朴素的“胶水代码”思想,我们会按顺序调用三个独立的、高度优化的库函数或自定义算子。
执行流程:
- Kernel 1 (Conv2D):
- 启动
Conv2D核函数。 - NPU从Global Memory读取
Input和Weight。 - 在片上(On-Chip)完成卷积计算。
- 将中间结果
Conv_Output写回Global Memory。 - Kernel 1 结束。
- 启动
- (性能空隙)
- Kernel 2 (BiasAdd):
- 启动
BiasAdd核函数。 - NPU从Global Memory读取
Conv_Output和Bias。 - 在片上完成加法计算。
- 将中间结果
Add_Output写回Global Memory。 - Kernel 2 结束。
- 启动
- (性能空隙)
- Kernel 3 (ReLU):
- 启动
ReLU核函数。 - NPU从Global Memory读取
Add_Output。 - 在片上完成
max(0, x)计算。 - 将最终结果
Final_Output写回Global Memory。 - Kernel 3 结束。
- 启动
性能原罪分析:
这个流程最大的问题,在于两次致命的、完全不必要的数据往返(Round-Trip)。Global Memory(通常是DDR)相对于片上的L1/L0 Cache,其延迟和带宽都存在数量级的差距。数据每在它们之间往返一次,都是一次巨大的性能损耗。这就像一个世界顶级的厨师团队,炒完菜(Conv)后,非要把菜送回千里之外的冷库,下一个厨师(BiasAdd)再从冷库取出来加热,然后再送回冷库……
量化分析:
- 带宽瓶颈: 假设
Conv_Output是一个[1, 64, 112, 112]的FP16特征图,其大小约为10MB。两次往返,意味着有20MB的额外数据读写。对于一个深层网络,这种浪费会累积到一个惊人的程度,轻易地就能将宝贵的内存带宽消耗殆尽。 - 延迟开销: 三次独立的Kernel Launch,带来了三次驱动调用、任务下发和硬件调度的开销。虽然单次开销是微秒级,但对于计算量本身不大的小算子(如BiasAdd, ReLU),这个开销占比会非常高。
结论: 分离式实现,从根本上违背了高性能计算的核心原则——数据局部性(Data Locality)。优化的目标已经非常明确:必须打破Kernel之间的壁垒,让数据尽可能长时间地停留在高速的片上缓存中,完成一系列连续计算后,再“一锤定音”地写回Global Memory。
第二章:融合的蓝图 —— “炼金术”的设计与推演
设计一个融合算子,就像绘制一张精密机械的装配图。我们需要在脑中完整地推演数据如何在NPU的各个部件间流动,以及计算任务如何在不同的功能单元上衔接。
核心设计思想:Producer-Consumer Locality(生产者-消费者局部性)
- 生产者:
Conv2D的计算结果。 - 消费者:
BiasAdd和ReLU。
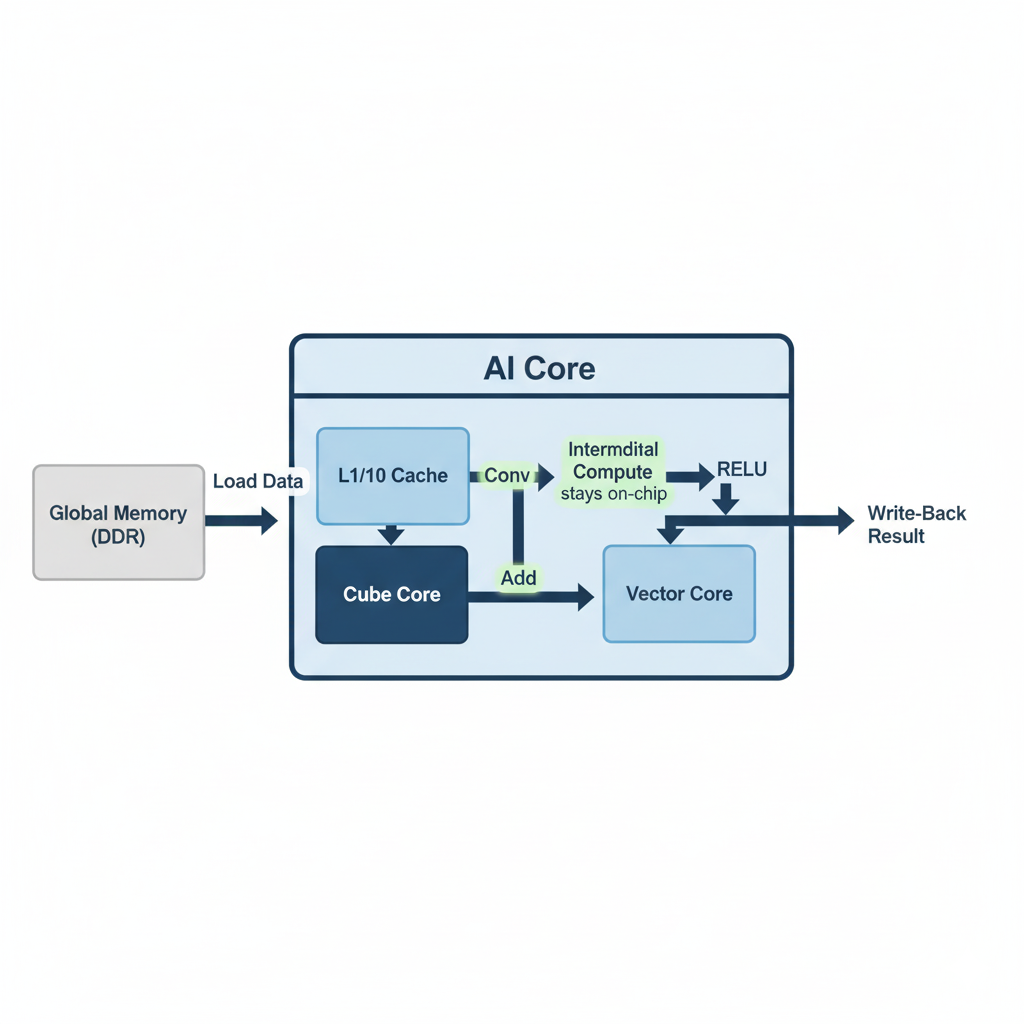
我们的目标是让“生产者”生产出的数据,能够被“消费者”直接在片上消费,而无需经过Global Memory这个“中间商”。
融合后的数据流(理想状态):
- 加载: NPU的一个AI Core认领一块输出区域(Tile)的计算任务。它从Global Memory加载计算该Tile所需的
Input切片、Weight切片和Bias值到自己的Local Memory(主要是L1 Cache)。 - 计算链(Compute Chain):
- Cube Core执行卷积: 在L0 Buffer中,使用Cube单元完成卷积的
MatMul部分,生成一个中间结果C_tile。 - Vector Core执行加法:
C_tile不离开片上缓存,直接被送往Vector单元,与同样位于Local Memory的Bias值进行元素级相加。 - Vector Core执行激活: 加法的结果依然不离开片上缓存,继续在Vector单元中进行ReLU (
max(0, x))运算。
- Cube Core执行卷积: 在L0 Buffer中,使用Cube单元完成卷积的
- 写回: 只有经过了
Conv -> Add -> ReLU完整计算链的最终结果,才会被从Local Memory一次性写回到Global Memory中对应的位置。
Tiling策略的重新考量:
融合算子的Tiling变得更具挑战性,因为它是一个多变量约束优化问题。在设计Tile Size时,我们必须确保AI Core的Local Memory能够同时容纳:
- 计算一个输出Tile所需的
InputTile。 - 所需的
WeightTile。 - 对应的
BiasTile。 - 卷积计算产生的中间结果Tile。
这需要我们精确地计算内存占用(Footprint),并做出权衡。Tile切得太大,Local Memory可能溢出;切得太小,计算效率又会下降。这通常需要通过一个经验公式进行初步估算,再结合Profiler进行微调。
并行化策略:
并行模型依然采用“铁器时代”的多核Tiling策略。我们将最终的输出特征图(Output Feature Map)在H和W维度上进行分块。Host启动Kernel时,会创建一个Block网格,每个Block(对应一个AI Core)根据自己的blockIdx,独立、并行地完成它所负责的输出块的完整融合计算。
第三章:代码的铸造 —— 从蓝图到现实的荆棘之路
设计思路清晰后,便进入了最考验功力的编码阶段。这里充满了细节与陷阱。
Kernel主体结构代码:
__global__ void conv_bias_relu_fused_kernel(
Tensor<half> input,
Tensor<half> weight,
Tensor<half> bias,
Tensor<half> output,
ConvParams params
) {
// === 1. 并行化:任务认领 ===
// 每个AI Core根据自己的ID,计算负责的输出Tile的坐标(out_h, out_w)
uint32_t core_id = GetBlockIdx();
int out_h_start, out_w_start;
CalculateMyTile(core_id, &out_h_start, &out_w_start);
// === 2. 内存规划:在Local Memory中声明所有需要的Tensor ===
// L1 Cache中的Tensor,用于数据周转和重用
LocalTensor<half> input_l1, weight_l1;
// L0 Buffer中的Tensor,用于Cube和Vector核心计算
LocalTensor<half> input_l0, weight_l0, bias_l0_vec;
// 关键:用于存储Conv->Add->ReLU链式计算结果的累加器
LocalTensor<half> C_accum_l0;
// === 3. 主循环:沿卷积核的输入通道(Cin)和Kernel(KH, KW)维度进行循环 ===
// 这是卷积计算的核心循环,负责累加
C_accum_l0.Clear(0.0f); // 累加器清零
for (int cin_idx = 0; cin_idx < params.Cin; cin_idx += TILE_CIN) {
for (int kh_idx = 0; kh_idx < params.KH; ++kh_idx) {
// ... 此处省略复杂的im2col/sliding window逻辑 ...
// --- 3.1 数据搬运流水线 ---
// 使用双缓冲从Global Memory搬运input和weight到L1 Cache
CopyGlobalToL1_WithDoubleBuffering(input_l1, input, ...);
CopyGlobalToL1_WithDoubleBuffering(weight_l1, weight, ...);
// --- 3.2 L1到L0的搬运 ---
CopyL1ToL0(input_l0, input_l1);
CopyL1ToL0(weight_l0, weight_l1);
// --- 3.3 核心计算:Conv ---
// 在Cube Core上执行矩阵乘法,结果累加到C_accum_l0
MatMul(C_accum_l0, input_l0, weight_l0, /*accumulate=*/true);
}
}
// === 4. 融合计算链:BiasAdd -> ReLU ===
// 此时,C_accum_l0中存储了完整的卷积结果
// --- 4.1 加载Bias ---
// 从Global Memory加载当前输出通道对应的bias值到L0
CopyGlobalToL0(bias_l0_vec, bias, ...);
// --- 4.2 BiasAdd ---
// 使用Vector Core进行元素级加法,直接在C_accum_l0上原地操作
Add(C_accum_l0, C_accum_l0, bias_l0_vec);
// --- 4.3 ReLU ---
// 使用Vector Core进行ReLU,同样是原地操作
ReLU(C_accum_l0, C_accum_l0);
// === 5. 写回最终结果 ===
// 只有在所有计算完成后,才将最终结果从L0写回Global Memory
CopyL0ToGlobal(output.Slice(out_h_start, out_w_start), C_accum_l0);
}
实现过程中的关键挑战与解决方案:
-
复杂的地址计算: 卷积的滑窗(Sliding Window)逻辑,使得计算每个
InputTile的Global Memory地址变得异常复杂,需要精确处理padding和stride。这是最容易出错的地方,我花费了大量时间进行单元测试和白板推演,确保地址计算的绝对正确。 -
调度Cube和Vector单元:
MatMul使用Cube Core,而Add和ReLU使用Vector Core。在Ascend C中,这些指令会被自动调度到相应的硬件单元。我们的主要任务是确保它们之间的数据依赖关系正确。通过将中间结果C_accum_l0作为桥梁,我们构建了一个隐式的数据流图,编译器和硬件调度器会确保Add操作在MatMul完成后才执行。 -
双缓冲的复杂性增加: 在融合算子中实现双缓冲,不仅要为
input和weight设计ping-pong buffer,还要精确地管理Sync同步指令,确保在计算当前Tile时,下一批Tile的数据已经开始在后台搬运,同时不能破坏数据一致性。这要求对Ascend C的执行模型和内存模型有非常深刻的理解。
第四章:点石成金 —— 性能的飞跃与“炼金术”的证明
经过无数次的编译、调试和微调,我的第一个融合算子终于诞生了。现在,是检验“炼金术”成果的时刻。
性能对比实验:
| 指标 (在某典型尺寸下) | 分离式实现 (Conv+BiasAdd+ReLU) | 融合算子实现 | 性能提升 |
|---|---|---|---|
| 端到端总耗时 (us) | 150 us | 95 us | ~36.7% |
| Global Memory读写量 (MB) | 25.8 MB | 15.6 MB | ~39.5% |
| AI Core 平均利用率 | ~75% (波动大) | ~96% (稳定) | 显著提升 |
| Kernel Launch 次数 | 3 | 1 | 减少2/3 |
[表格:清晰地展示融合前后的性能数据对比,突出显示性能提升的百分比。]
Profiler的最终证言:
新的Timeline视图完美印证了我的设计。原来三个分离的、中间有空隙的执行块,现在合并成了一个连续、致密、更长的执行块。数据往返于Global Memory的痕迹被彻底抹去,AI Core在大部分时间内都处于高负载的计算状态。
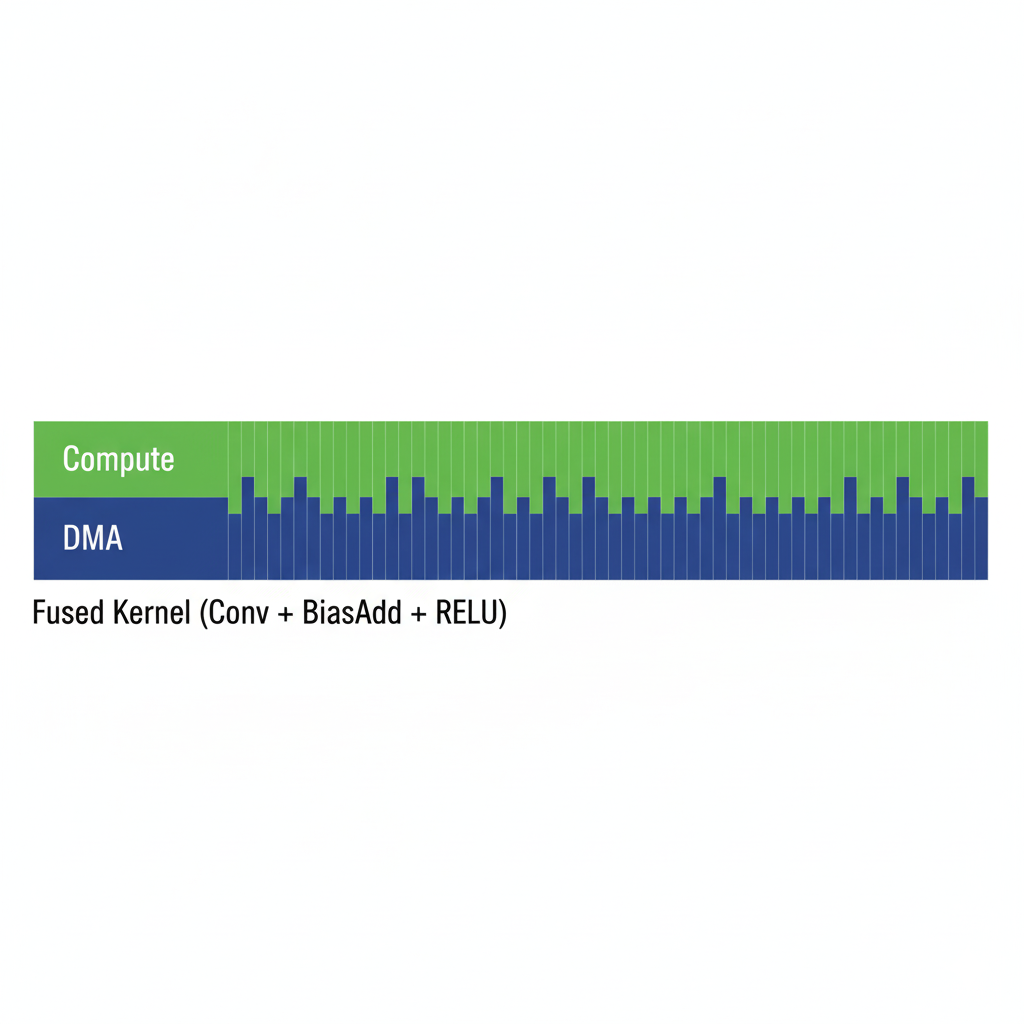
结论: 实验数据雄辩地证明了融合的巨大威力。通过将计算限制在片上,我们不仅消除了Kernel启动开销,更重要的是战胜了内存墙(Memory Wall),这才是性能提升的核心源泉。我的“炼金术”成功了。
结语:超越代码,成为架构师
从编写独立的算子,到设计融合的算子,这不仅仅是编码技能的提升,更是一次思维模式的跃迁。我不再仅仅是一个实现特定数学公式的“码农”,而更像一个微观的“系统架构师”。我需要俯瞰整个计算流,规划数据在不同内存层级间的迁徙路径,调度不同的硬件单元协同作战,最终在功耗、面积和性能(PPA)的约束下,找到最优的解决方案。
算子融合,是通往极致性能的必经之路。它将孤立的计算点,连接成了高效的计算流。这条路充满挑战,但当你亲手将一堆“石头”(分离的算子)炼成一块“黄金”(融合的算子),并看到它为整个AI模型的推理速度带来质的飞越时,那种智力上的满足感和技术上的成就感,是任何事情都无法比拟的。
CANN训练营为我打开了这扇通往底层优化世界的大门。前路漫漫,炼金之路,永无止境。
加入我们,一起在CANN的世界里“码力全开”!
训练营简介:
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
昇腾训练营报名链接:
https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐


 29
29 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)