CANN码力全开特辑:不只是切分——我的Tiling策略“进化史”与性能调优实录
前言:从“正确”到“高效”的鸿沟
在完成上一篇关于“告别CPU思维”的心得总结后,我满怀信心地投入到了一个更复杂的算子开发任务中——实现一个高性能的矩阵乘法(MatMul)。我熟练地运用了Ascend C的API,逻辑严谨,编译一次通过,功能验证完美无误。然而,当我用性能分析工具(Profiler)查看结果时,一盆冷水从头浇到脚:算子的执行时间长得离谱,GFLOPS(每秒十亿次浮点运算)低得可怜。我的代码是“正确”的,但它距离“高效”之间,隔着一条深不见底的鸿沟。
这条鸿沟,就是Tiling。
起初,我以为Tiling不就是把大矩阵切成小块,一个循环搞定吗?但随着在CANN训练营的深入学习和无数次的性能调试,我才恍然大悟:Tiling不是一种简单的操作,它是一门艺术,一门在算法逻辑、硬件架构和内存层次之间寻找最佳平衡点的科学。它决定了数据如何在漫长而昂贵的内存 Hierarchy(层级)中流动,决定了NPU那数以万计的计算单元能否被持续“喂饱”。
这篇文章,就是我个人Tiling策略的“进化史”,记录了我从“石器时代”的朴素实现,一步步走向“现代文明”精细化调优的全过程。希望我的踩坑与思考,能为你点亮前行的路。

第一阶段:“石器时代”—— Host侧驱动的幼稚Tiling
在我旅程的最初,我的大脑里依然残留着CPU编程的惯性。我当时的想法非常直观:既然NPU一次只能处理一小块,那我就在Host(主机CPU)侧写一个循环,每次循环启动一个Kernel任务,去处理一小块数据。
核心思想:
- Host侧控制循环: 在CPU上编写
for循环,遍历整个输出矩阵C的Tile。 - Device侧简单执行: Kernel函数非常简单,它只负责计算一个固定大小的Tile。每次调用,它都像一个全新的、独立的任务。
Host侧逻辑:
// Host侧代码 (C++ / Python)
void launch_naive_tiling_kernel(Tensor A, Tensor B, Tensor C, TilingInfo tiling) {
// 遍历输出矩阵C的Tile
for (int i = 0; i < C.height; i += tiling.TILE_M) {
for (int j = 0; j < C.width; j += tiling.TILE_N) {
// 为每一个Tile启动一个Kernel
// 参数包括当前Tile的偏移量
enqueue_kernel("matmul_kernel", A, B, C, i, j);
}
}
}
Kernel代码:
// Device侧Kernel (Ascend C)
// Kernel只知道自己要处理一个Tile,不知道全局信息
__global__ void matmul_kernel(Tensor A, Tensor B, Tensor C, int offset_i, int offset_j) {
// 1. 分配Local Memory (L1/L0)
LocalTensor<float> A_tile, B_tile, C_tile;
// 2. 循环K维度,搬运和计算
for (int k = 0; k < A.width; k += TILE_K) {
// 从Global Memory搬运数据到Local Memory
Copy(A_tile, A.Slice(offset_i, k));
Copy(B_tile, B.Slice(k, offset_j));
// 计算
MatMul(C_tile, A_tile, B_tile);
}
// 3. 写回结果
Copy(C.Slice(offset_i, offset_j), C_tile);
}
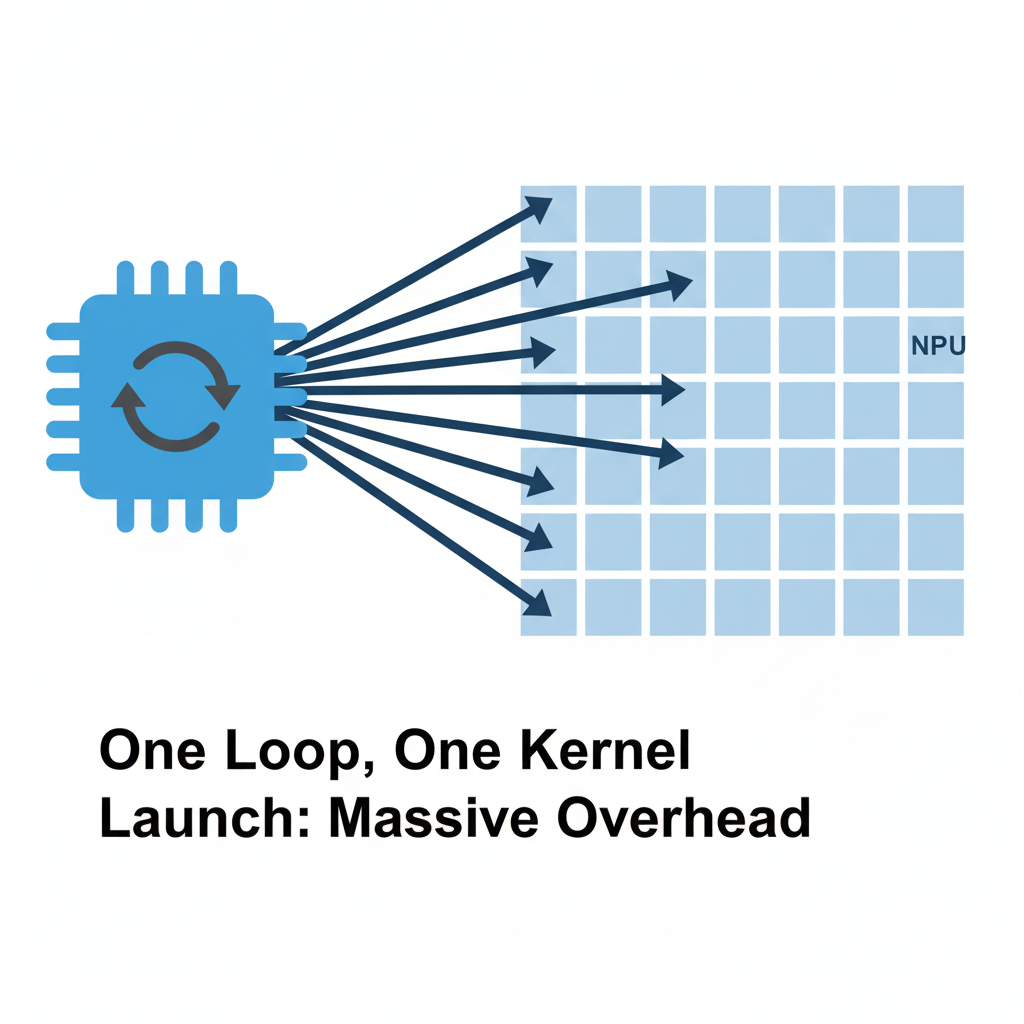
血的教训:为何如此之慢?
这种实现方式逻辑清晰,易于理解,但性能却是灾难性的。原因在于一个被我完全忽略的致命因素:Kernel Launch Overhead(核函数启动开销)。
每次从Host侧启动一个Device侧的Kernel,都不是零成本的。它涉及到一系列复杂的底层操作:驱动程序调用、上下文切换、参数传递、任务下发到硬件调度器等。这个过程可能需要花费几微秒(us)甚至更多的时间。
如果我的Tile很小,Kernel本身的计算时间可能也只有几微秒。这意味着,我大部分的时间都花在了“准备工作”上,而不是真正的“计算”上! 就像请一位世界级大厨,每次只让他炒一粒米,然后让他下班,再请他回来炒下一粒米。无论厨师手艺多高,出餐速度都会慢得令人发指。
结论: Host侧驱动的Tiling是一种反模式(Anti-Pattern)。它将NPU强大的并行计算能力,切割成了无数个被高昂启动开销扼杀的串行任务。优化的第一步,必须是将Tiling的控制权,从Host转移到Device内部。
第二阶段:“青铜时代”—— Kernel内部循环与数据重用
吸取了教训,我迎来了Tiling策略的第一次重大进化。我意识到,必须让一个Kernel Launch去干更多的事情。
核心思想:
- 单次Kernel启动: Host只启动一次Kernel,这个Kernel负责完成整个矩阵的计算。
- Kernel内循环: 将原来在Host侧的
for循环,移入到Kernel内部。Kernel内部通过循环来遍历和处理不同的Tile。 - 数据重用的曙光: 这种结构天然地为数据重用创造了条件。
Kernel代码(进化版):
// 单次启动,Kernel内部完成所有工作
__global__ void matmul_kernel_internal_loop(Tensor A, Tensor B, Tensor C) {
// 在最外层,循环遍历输出矩阵C的Tile
for (int i = 0; i < C.height; i += TILE_M) {
for (int j = 0; j < C.width; j += TILE_N) {
// --- 处理单个C_ij Tile的逻辑 ---
LocalTensor<float> C_tile; // 用于累加的Tile
C_tile.Clear(); // 清零
// 循环K维度
for (int k = 0; k < A.width; k += TILE_K) {
LocalTensor<float> A_tile, B_tile;
// 从Global Memory加载A的一个Tile和B的一个Tile
Copy(A_tile, A.Slice(i, k));
Copy(B_tile, B.Slice(k, j));
// 计算并累加
MatMul(C_tile, A_tile, B_tile, /*accumulate=*/true);
}
// 单个C_ij Tile计算完毕,写回Global Memory
Copy(C.Slice(i, j), C_tile);
// --- 单个Tile处理结束 ---
}
}
}
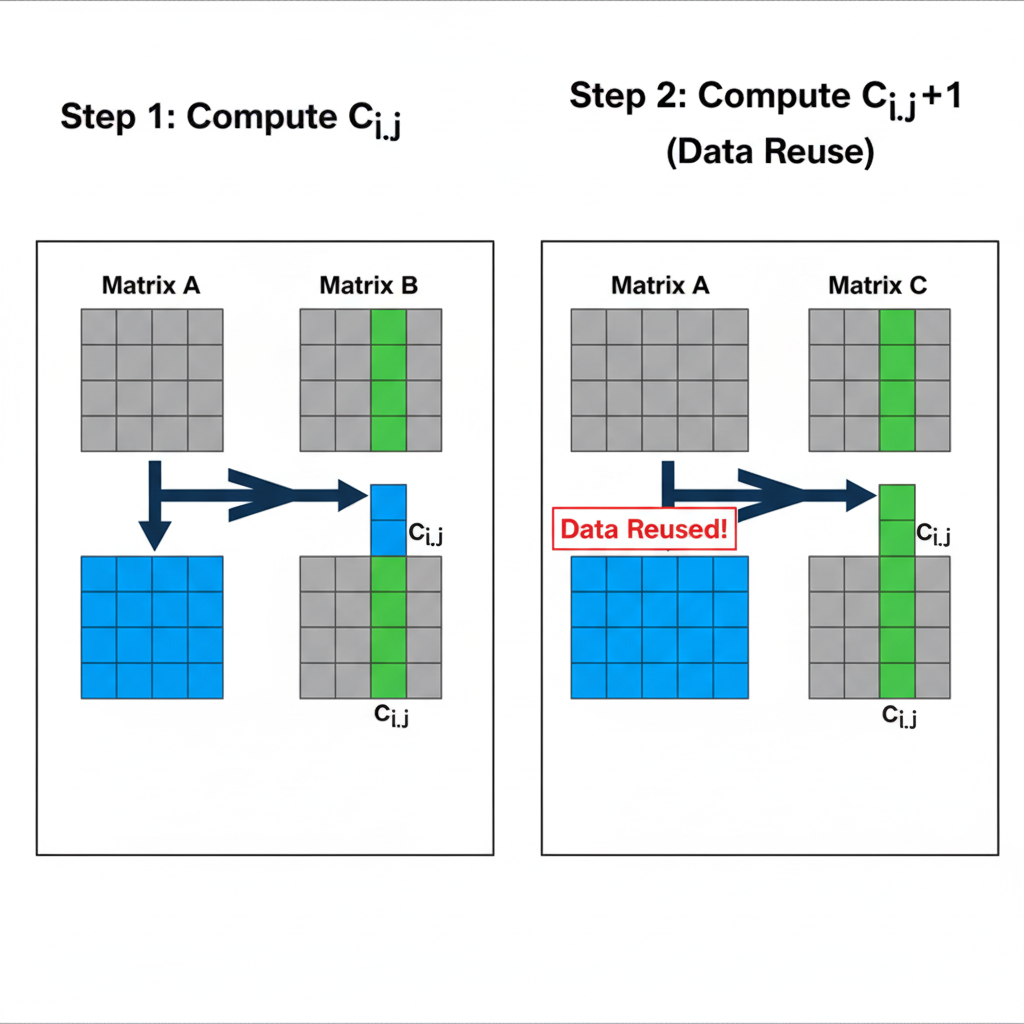
性能的第一次飞跃:数据重用(Data Reuse)
当我用这种方式重写代码后,性能得到了数量级的提升。我激动地分析着Profiler,终于找到了关键原因——数据重用。
让我们聚焦于内层的k循环。在计算C.Slice(i, j)时,我们需要加载A.Slice(i, 0...K)和B.Slice(0...K, j)的所有小块。现在,考虑计算旁边的C.Slice(i, j+TILE_N)。它需要加载A.Slice(i, 0...K)和B.Slice(0...K, j+TILE_N)。
发现了吗?A.Slice(i, 0...K)这部分数据被重复使用了!
在“青铜时代”的实现中,我们可以通过更巧妙的循环组织,将一个A_tile加载到高速缓存(如L1 Cache)后,用它来计算所有相关的C_tile,然后再加载下一个A_tile。
优化的循环结构:
// 优化的循环顺序,最大化数据重用
for (int i = 0; i < C.height; i += TILE_M) {
for (int k = 0; k < A.width; k += TILE_K) {
// 1. 加载一个A_tile到高速缓存 (L1)
LocalTensor<float> A_tile_L1;
Copy(A_tile_L1, A.Slice(i, k));
for (int j = 0; j < C.width; j += TILE_N) {
// 2. 加载一个B_tile到高速缓存 (L1)
LocalTensor<float> B_tile_L1;
Copy(B_tile_L1, B.Slice(k, j));
// 3. 计算 (数据实际在L0中)
// ... MatMul逻辑 ...
// A_tile_L1在这里被重复用于多个j的循环
}
}
}
结论: Kernel内部循环消除了启动开销,并开启了数据重用的大门。这是从“能用”到“可用”的关键一步。此时,我的思维已经开始从关注“如何计算”,转向关注**“如何最小化数据搬运”**。
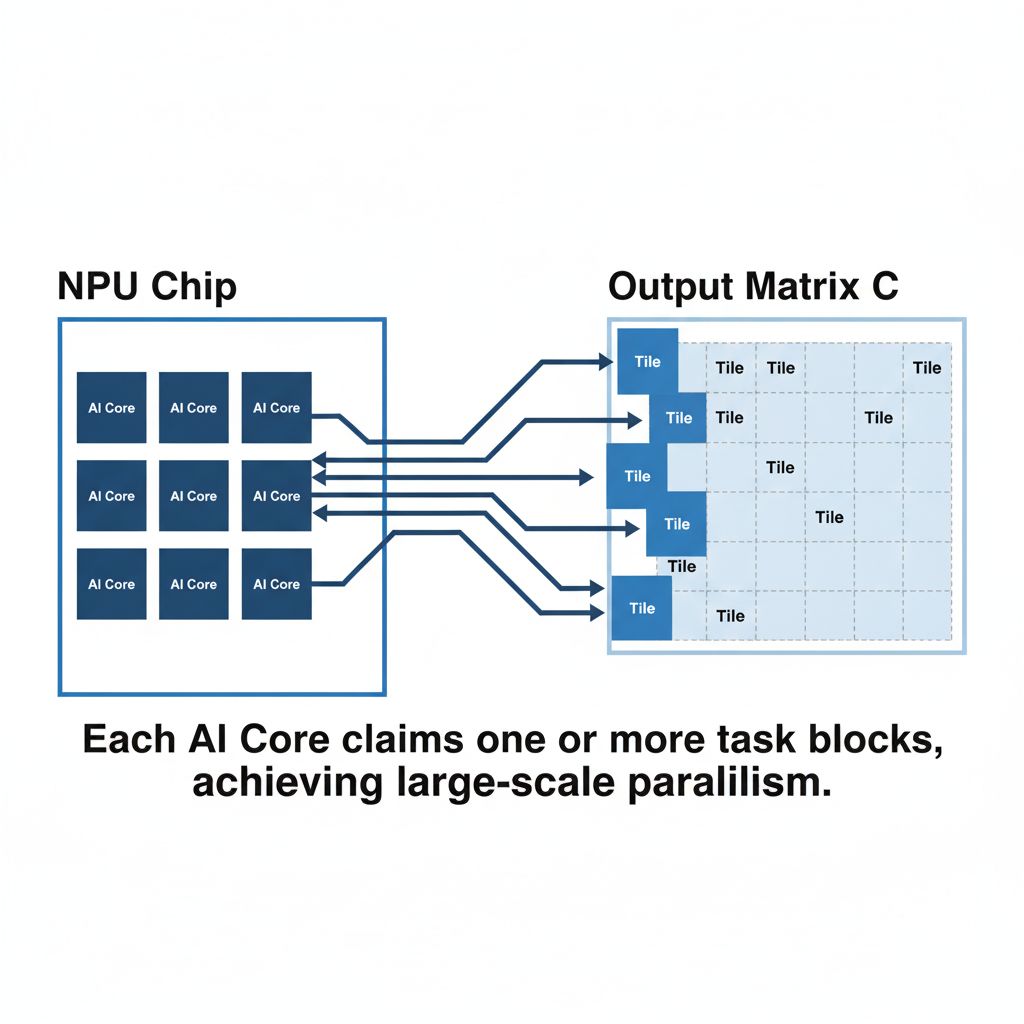
第三阶段:“铁器时代”—— 拥抱硬件并行,多核Tiling
“青铜时代”的算子虽然快了不少,但Profiler显示,NPU芯片上那么多的AI Core(计算核心),只有一个在忙碌!我只是把一个单线程任务做得更快了,完全没有利用到NPU大规模并行的本质。
进入“铁器时代”,我的核心任务是:将Tiling与硬件的并行单元(AI Core)映射起来,让所有核心同时工作。
核心思想:
- Grid-Block-Thread模型: 借鉴并行计算中常见的模型,我们将整个计算任务看作一个Grid(网格),Grid由多个Block(块)组成。在昇腾NPU中,一个Block通常可以看作是分配给一个AI Core的任务。
- 任务划分: 不再用循环遍历所有Tile,而是让每个AI Core根据自己的唯一ID(
blockIdx)去“认领”它负责计算的Tile。 - 并行计算: Host一次启动Kernel,会同时在多个AI Core上创建Kernel实例。这些实例同时执行,但由于
blockIdx不同,它们会各自处理C矩阵的不同部分,从而实现真正的并行。
Kernel侧代码(并行版):
// 并行版Kernel,每个AI Core执行一个实例
__global__ void matmul_kernel_parallel(Tensor A, Tensor B, Tensor C) {
// 1. 获取当前AI Core的ID
// 假设我们启动了一个2D的Block网格
uint32_t block_id_x = GetBlockIdx_X(); // 在j维度上的ID
uint32_t block_id_y = GetBlockIdx_Y(); // 在i维度上的ID
// 2. 根据ID计算当前Core负责的C_tile的基地址
// 不再有最外层的i, j循环!
int i = block_id_y * TILE_M;
int j = block_id_x * TILE_N;
// --- 处理单个C_ij Tile的逻辑 (与之前类似) ---
LocalTensor<float> C_tile;
C_tile.Clear();
// 循环K维度,这部分仍然是每个Core内部的串行逻辑
for (int k = 0; k < A.width; k += TILE_K) {
LocalTensor<float> A_tile, B_tile;
Copy(A_tile, A.Slice(i, k));
Copy(B_tile, B.Slice(k, j));
MatMul(C_tile, A_tile, B_tile, /*accumulate=*/true);
}
// 写回当前Core负责的那个Tile的结果
Copy(C.Slice(i, j), C_tile);
}
性能的巅峰体验:榨干硬件
当我终于调通了这个并行版本的算子后,性能数据让我热血沸腾。GFLOPS值飙升到了一个前所未有的高度,Profiler显示所有的AI Core都在高负载运行。这感觉就像之前我一直在用一根手指弹钢琴,而现在,我终于学会了用双手和十指奏出雄壮的和弦。
关键转变:
- 从时间切分到空间切分: 以前的循环是在“时间”上先后处理不同的Tile。现在的并行模型,是在“空间”上将不同的Tile分配给不同的硬件单元同时处理。
- 全局视角的重要性: 编写并行Kernel需要更强的全局观。你需要清晰地规划任务如何划分,每个Core如何定位自己的数据,以及如何处理边界情况(比如矩阵尺寸不是Tile尺寸的整数倍)。
挑战:边界处理(Tailgating)
一个常见的问题是,如果矩阵的维度,例如C.height,不能被TILE_M整除,那么最后一行的Tile就会有“尾巴”。block_id_y计算出的i可能会超出矩阵边界。这就需要在代码中加入边界检查:
// 在数据拷贝和写回前,必须进行边界检查
if (i < C.height && j < C.width) {
// ... 执行拷贝和计算 ...
}
这会增加一些逻辑复杂度,但对于保证算子的通用性和正确性至关重要。
第四阶段:“现代文明”—— 精雕细琢,探寻性能极限
达到了“铁器时代”,我的算子已经非常高效了。但CANN训练营的导师告诉我们:“性能优化永无止境”。在“现代文明”阶段,我们追求的是在细节中榨取最后5%-10%的性能。这需要我们对硬件的微观特性有更深的理解。
1. 双缓冲(Double Buffering)与流水线
在之前的实现中,数据拷贝(Copy)和计算(MatMul)是串行的。AI Core在计算时,DMA(数据搬运单元)在等待;DMA搬运时,AI Core在空闲。我们可以通过双缓冲技术,让它们流水线式地并行工作。
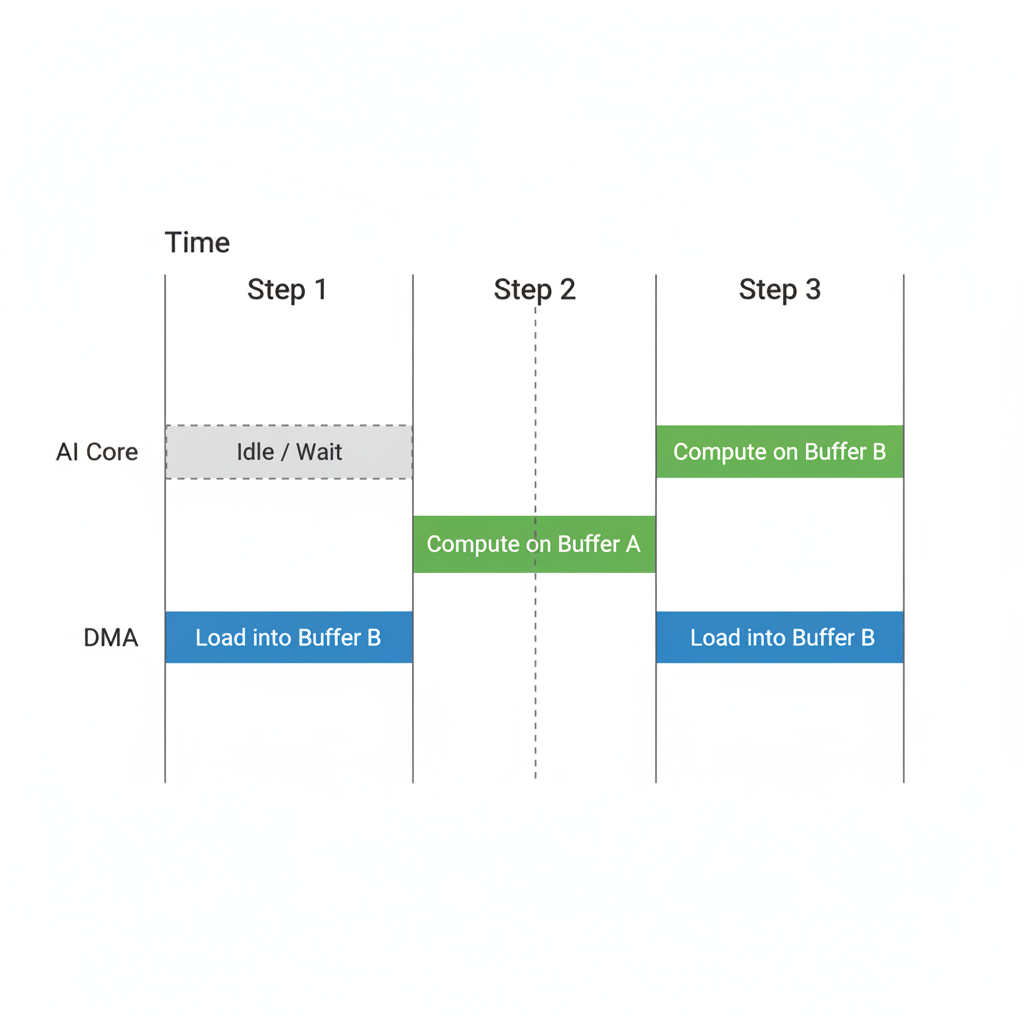
2. 内存Bank冲突(Bank Conflict)
片上高速缓存(L0/L1)为了提供高带宽,被分成了多个独立的Bank。如果一次内存访问中的多个地址,恰好落在了同一个Bank上,就会发生Bank冲突,导致访问必须串行化,大大降低了有效带宽。
一个真实的踩坑案例: 我曾经将一个Tile的宽度设置为32。在FP16(2字节)下,一次加载一行(32个元素)就是64字节。而当时硬件的Bank数量恰好是32个,每个Bank宽度为4字节。这导致每一行的起始地址,其Bank ID的计算方式(如 addr / 4 % 32)高度相关,造成了严重的Bank冲突。仅仅是将Tile宽度从32改为36(加入padding),通过错开地址,就让性能提升了15%。
3. 向量化(Vectorization)与数据对齐
除了Cube单元,NPU上还有强大的Vector单元,用于执行元素级(element-wise)的计算。为了最大化Vector单元的效率,数据在内存中的地址最好是对齐的(比如对齐到32字节)。在Tiling时,选择合适的Tile尺寸和数据布局,确保每次内存拷贝都能满足对齐要求,可以让向量指令的执行效率最大化。
4. 自动调优(Auto-Tuning)的启示
手动选择最优的Tile尺寸(TILE_M, TILE_N, TILE_K)是一个极其复杂的组合优化问题,它依赖于具体的硬件型号、数据类型和问题规模。这就是为什么昇腾提供了Auto-Tuning和**TBE(Tensor Boost Engine)**这样的工具。它们可以自动搜索最佳的Tiling配置。
虽然工具可以帮我们完成搜索,但理解前面几个“时代”的进化过程,能让我们:
- 设定合理的搜索空间: 告诉工具应该在哪个范围内搜索。
- 理解调优结果: 明白为什么某个配置比另一个更好。
- 调试性能问题: 当自动生成的算子性能不佳时,能有针对性地去分析瓶颈。
最终的感悟:Tiling是算法与硬件的对话
回顾我的Tiling“进化史”,我深刻地体会到,编写高性能算子,本质上是在促成一场算法与硬件之间的深度对话。
- 你要倾听硬件的语言: 了解它的并行结构、内存层次、带宽限制、指令特性。
- 你要让算法适配硬件: 用Tiling、流水线、数据布局等技术,将你的计算意图,翻译成硬件最喜欢、最容易高效执行的形式。
这场对话充满了挑战,但也充满了创造的乐趣。当你通过精妙的Tiling设计,最终在Profiler上看到那条近乎完美的性能曲线时,那种成就感,是任何语言都难以形容的。
加入我们,一起在CANN的世界里“码力全开”!
训练营简介:
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
昇腾训练营报名链接:
https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐


 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)