CATLASS 分层架构赋能 GEMM 算子:高效开发、Tiling 调优与性能倍增的全实践解读
CATLASS 分层架构赋能 GEMM 算子:高效开发、Tiling 调优与性能倍增的全实践解读

引言:CATLASS—— 分层架构赋能 GEMM 算子的高效开发与性能突破
GEMM 算子开发时,常被两大问题困住:一是得吃透昇腾 NPU 的 AI Core 指令集、L1/L0 存储层级这些硬件细节,手动写底层优化代码,门槛高还费时间;二是不同场景的矩阵尺寸、数据类型不一样,适配起来麻烦,调优时还得在计算效率和数据搬运开销之间找平衡,难度特别大,而 CATLASS 算子模板库刚好解决了这些痛点:通过 Device、Kernel、Block、Tile、Basic 五层分层架构,把算子开发变成 “拼组件 + 配参数” 的简单活,不用纠结底层细节就能快速搭出高性能算子,还能灵活调 Tiling 参数适配硬件存储层级,减少数据搬运开销、榨干 NPU 算力。本文就从三步开发流程、分层接口逻辑、BasicMatmul 实操(环境配置、Tiling 调优、性能对比)三个方面,结合和传统开发、Aclnn 算子的对标,给大家讲透 CATLASS 的核心用法,帮开发者少走弯路、高效做 GEMM 算子开发。
CATLASS 三步高效完成算子开发

环境准备:硬件抽象层对接:屏蔽底层差异,降低适配成本
核心是建立软件工具链与 NPU 的通信接口,实现 “主机 - 设备” 的资源调度与指令下发,具体要安装 CANN 套件部署硬件抽象层,再配置环境变量统一驱动、API 库等工具链依赖路径。对开发者来说非常省心,不用手动适配不同昇腾 NPU 型号的驱动接口,靠 CANN 的标准化层就能直接获得跨硬件开发兼容性,彻底把硬件底层差异都屏蔽了,不用纠结各种型号的适配细节
Device/Kernel 层组装 + 编译:模块化抽象 :解耦硬件细节,提升开发效率
落地 CATLASS 分层架构,核心是用 “声明式开发替代指令式开发”,打破传统 GEMM 算子和硬件的强耦合,逻辑特别清晰:CATLASS 把 NPU 的计算单元 AI Core、存储层级 L1 缓存和 L0 寄存器封装成可复用的 Block 组件,Device 层负责封装设备级执行逻辑,Kernel 层完成计算组件的拼装。这种设计对开发者来说不用编写 mmad 指令、数据搬运指令这类 NPU 底层代码,只需要配置组件参数就能定义 GEMM 逻辑,编译阶段 CATLASS 会自动把组件拼装逻辑转换成可执行 Kernel 代码,不用跟底层硬件指令死磕,降低了算子开发和硬件细节的耦合度
算子执行与验证:跨设备一致性校验:自动化校验,保障功能正确
算子执行与验证聚焦异构计算的功能正确性,核心是确保 NPU 计算结果和 CPU 标杆完全一致,毕竟 NPU 是独立的计算设备,输出必须和 CPU 标杆即理论正确结果做精准比对,好在 CATLASS 已经集成了自动化逻辑:会自动把设备端(NPU)的数据回传到 CPU,再和 CPU 标杆完成精度校验,开发者不用手动写跨设备的数据校验代码,只要看到输出 “Compare success”,就说明校验通过省去了手动编码的麻烦。
CATLASS 分层接口层级解析:从高层调用到底层指令

CATLASS 的分层抽象架构图,从顶层(高抽象)到底层(硬件级)分为 5 个层级,每一层对应不同的开发粒度与功能定位,核心是通过 “逐层封装” 降低硬件开发门槛
- 调用接口层(Device):开发者直接使用的最高层接口,是特定计算任务的完整封装,组件如 DeviceGemm(矩阵乘)、DeviceGemv(矩阵向量乘)无需关注底层实现,直接调用就能完成任务,是最便捷的开发入口
- 多核计算层(Kernel):协调 NPU 多个 AI Core 的并行逻辑层,组件包含 Gemm、Matmul 等,负责将上层 Device 任务拆分为多核心可并行的子任务,能够自动处理多核心调度,不用手动协调硬件资源分配
- 单核计算层(Block):单个 AI Core 内的计算组件封装层,组件如 BlockMmad(单核矩阵乘加)、BlockEpilogue(单核计算后处理)把单核计算逻辑封装为可复用组件,拼装 Block 就能定义逻辑,无需编写硬件指令
- 单个步骤层(Tile):单个核心内的细粒度操作步骤层,对应硬件存储 / 计算基础流程,组件如 CopyGmToL1(全局内存到 L1 缓存搬运)、TileMmad(小粒度矩阵乘)封装了 Gm/L1/L0 等存储层级交互细节,不用手动管理数据流转
- 单条指令层(Basic):最贴近 NPU 硬件的底层指令层,对应硬件原生单条操作,组件如 Mmad(硬件矩阵乘加)、Load2D(硬件数据加载)是架构的硬件底座,被上层封装后就不需要开发者去直接操作
这个分层设计个人感觉非常契合开发者诉求,既充分覆盖快速开发场景,直接调用顶层 Device 接口,无需关注底层实现逻辑,也可以快速完成任务落地,又能满足精细调优需求,如果开发者需要进行性能优化,可以向下选用 Tile 或 Basic 组件,灵活性极强,比较特别的一点是逐层封装有效屏蔽了 NPU 硬件的底层细节,不需要再耗费大量精力钻研硬件指令,大幅减少不必要精力消耗。作为开发者,我们可以依据项目需求选择适配的抽象层级,既能加速项目推进节奏,又可以按需实现性能优化,兼顾开发效率和灵活性设计,实际使用体验会非常顺畅
BasicMatmul 算子全流程实践:环境配置、Tiling 调优与性能验证
简述:基于 CATLASS 框架,完整覆盖 BasicMatmul 算子的昇腾 NPU 环境搭建、编译运行验证,聚焦 L1 缓存与 L0 寄存器的 Tiling 参数硬件适配调优,通过多组参数性能对比,最终实现算子高精度与高性能的统一,为 NPU 算子开发与调优提供实操参考。
前提准备:GitCode Notebook 环境搭建
1、GitCode启动 NoteBook 资源
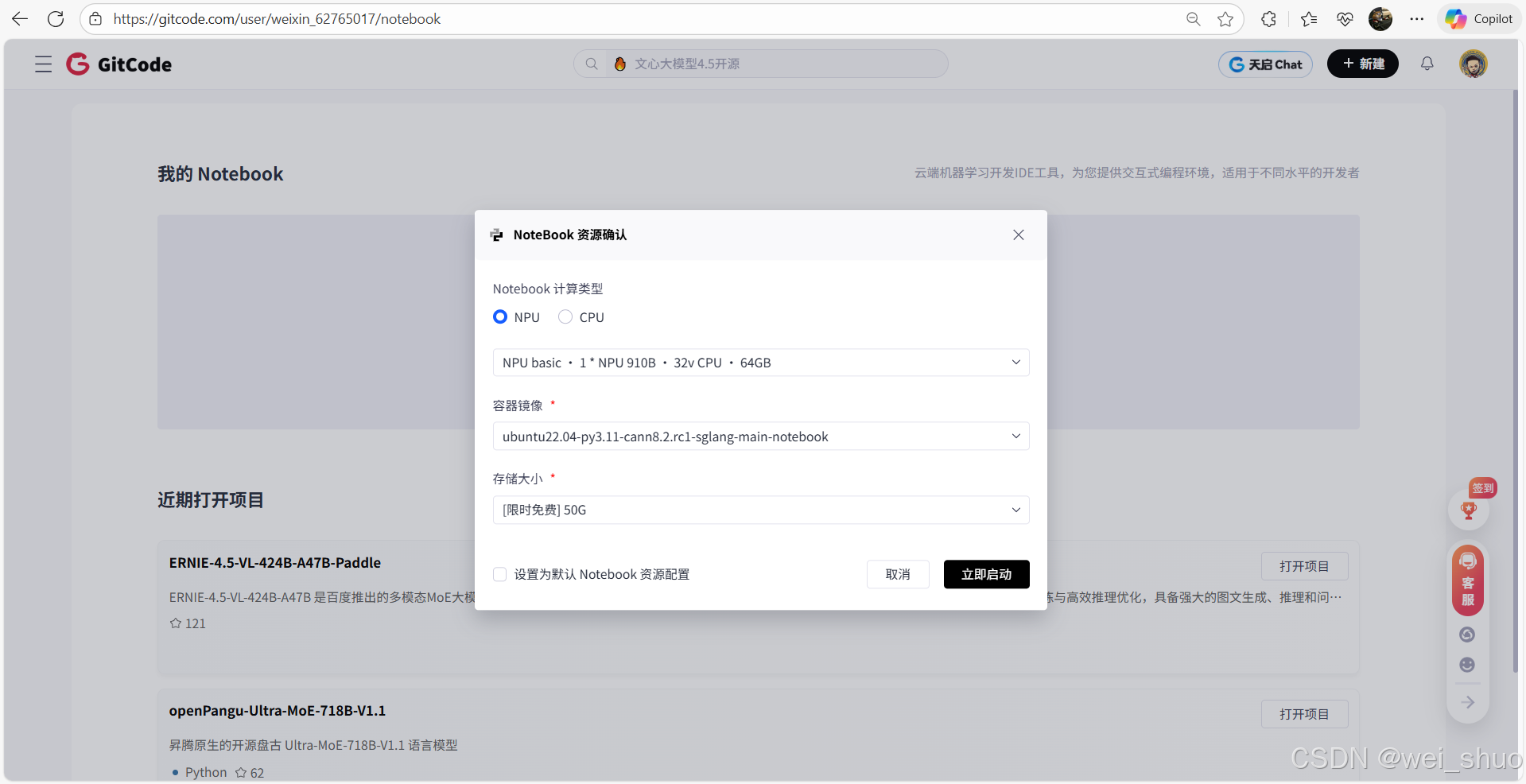
-
计算类型:NPU
-
CANN是昇腾 NPU设计的异构计算架构,因此必须选择NPU作为计算类型才能利用昇腾芯片的专用算力执行 AI 算子
-
NPU 硬件配置:NPU basic · 1 * Atlas 800T NPU · 32vCPU · 64GB
-
容器镜像:ubuntu22.04-py3.11-cann8.2.rc1-sglang-main-notebook
2、通过 CANN 配套的 NPU 管理工具npu-smi查看环境状态
npu-smi info
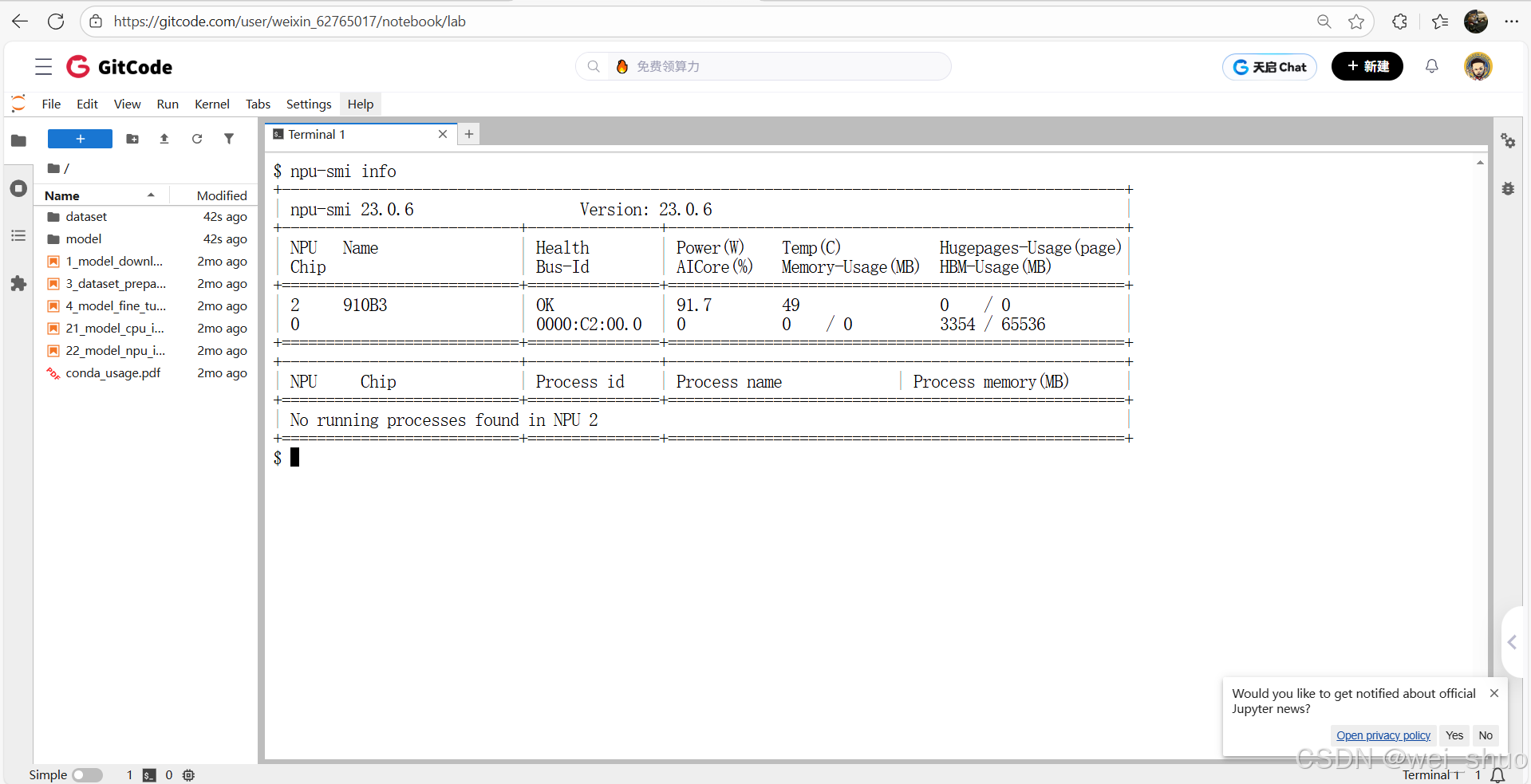
3、CATLASS 算子开发的环境适配检查表,有非常详细的硬件、系统、软件依赖的具体要求,同时有 GitCode Notebook 专用的容器环境配置规范,帮助大家快速确认当前环境是否符合条件,为后续 CATLASS 算子的开发、编译与调优工作做好前置校验
00_basic_matmul 算子:环境配置与编译运行验证
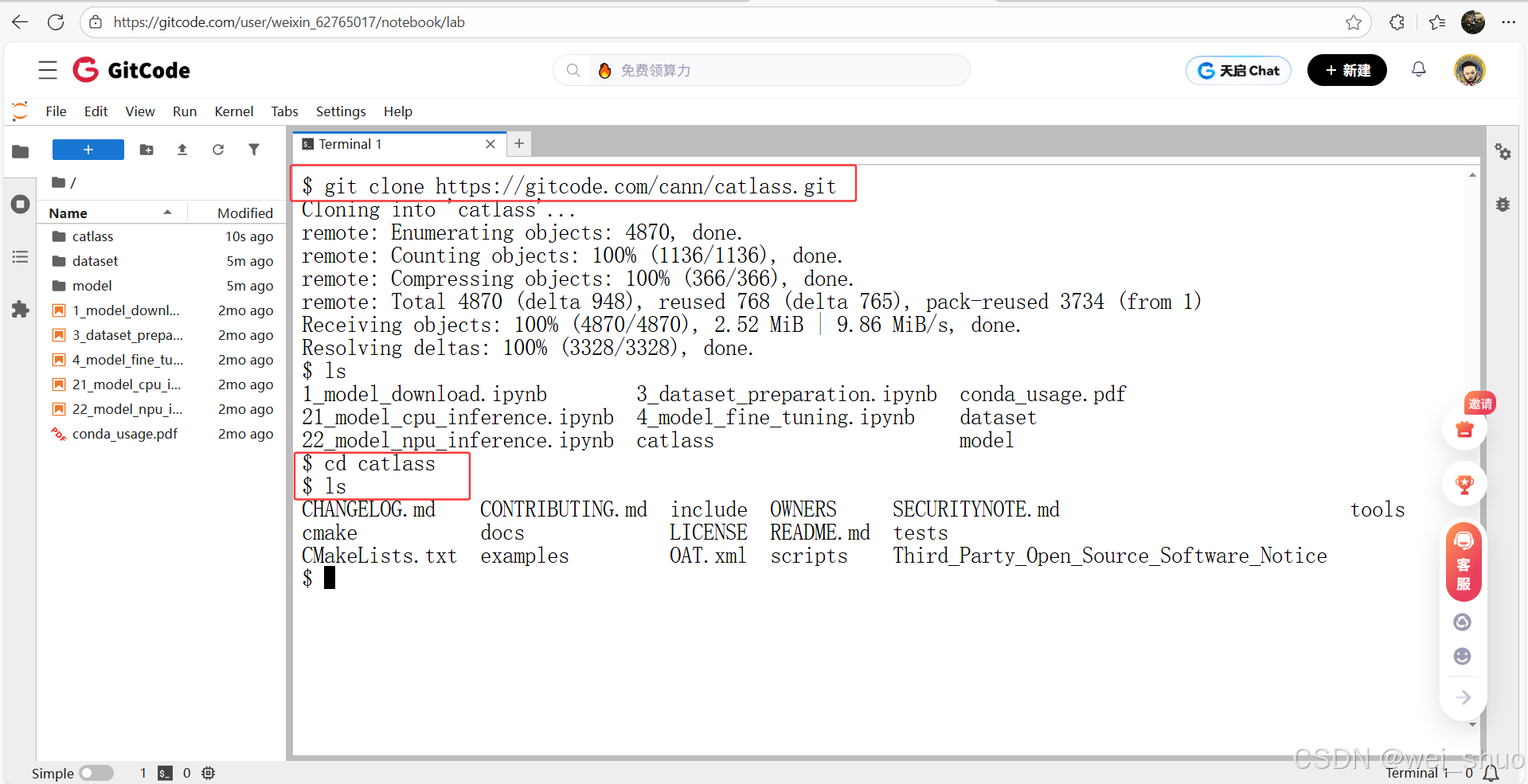
1、获取 CATLASS 代码仓(打开 gitcode notebook 终端,克隆官方代码仓)
# 官方代码仓地址示例
git clone https://gitcode.com/cann/catlass.git # 进入代码仓主目录
cd catlass
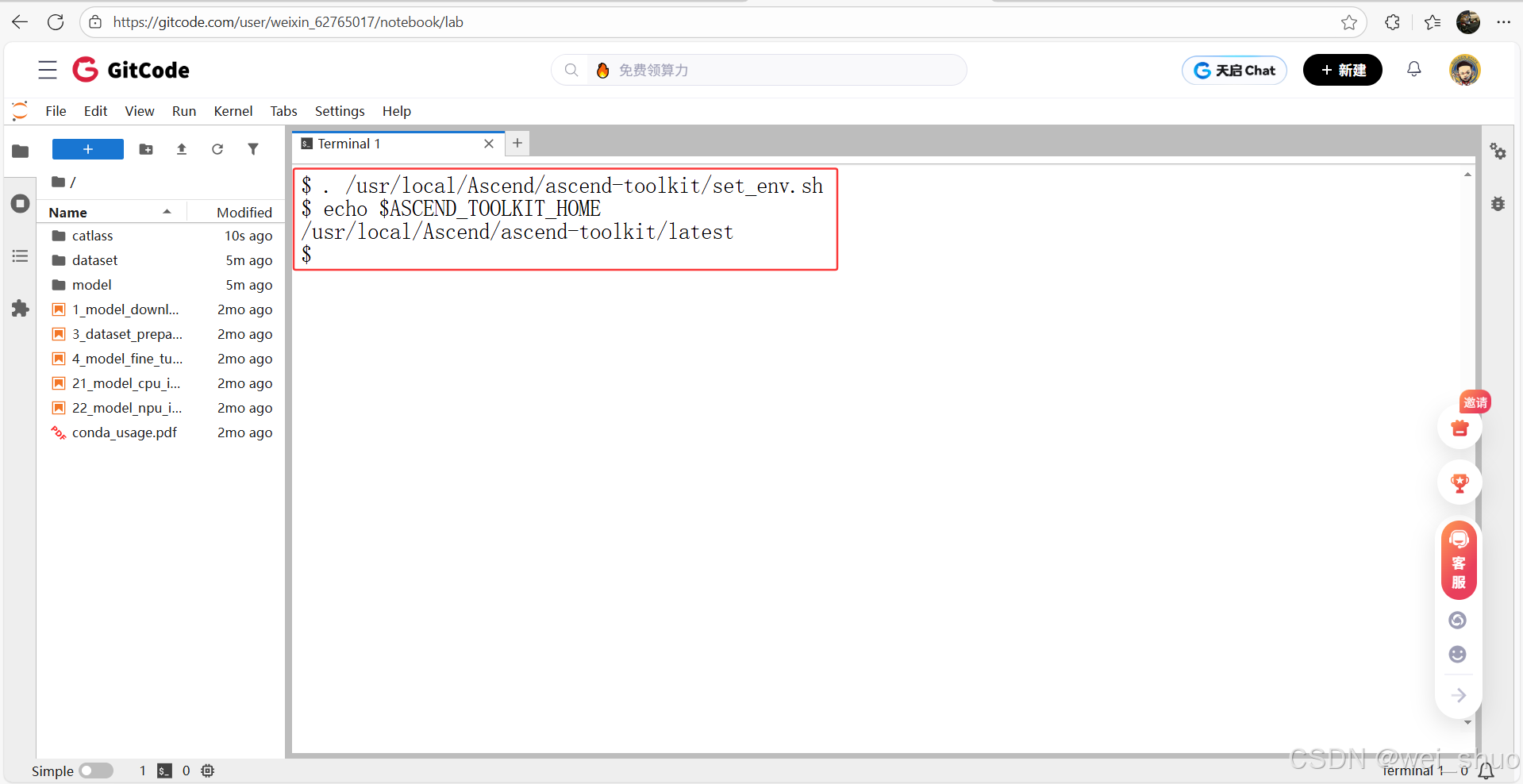
2、加载 CANN 环境变量并验证环境加载
# 加载 CANN 环境变量
. /usr/local/Ascend/ascend-toolkit/set_env.sh
# 验证环境加载成功
echo $ASCEND_TOOLKIT_HOME
3、编译脚本 build.sh 添加可执行权限并编译 00_basic_matmul 算子
# 确保当前在catlass主目录(若之前cd到其他目录,先执行 cd /path/to/catlass)
chmod +x scripts/build.sh
# 编译 00_basic_matmul 算子
bash scripts/build.sh 00_basic_matmul
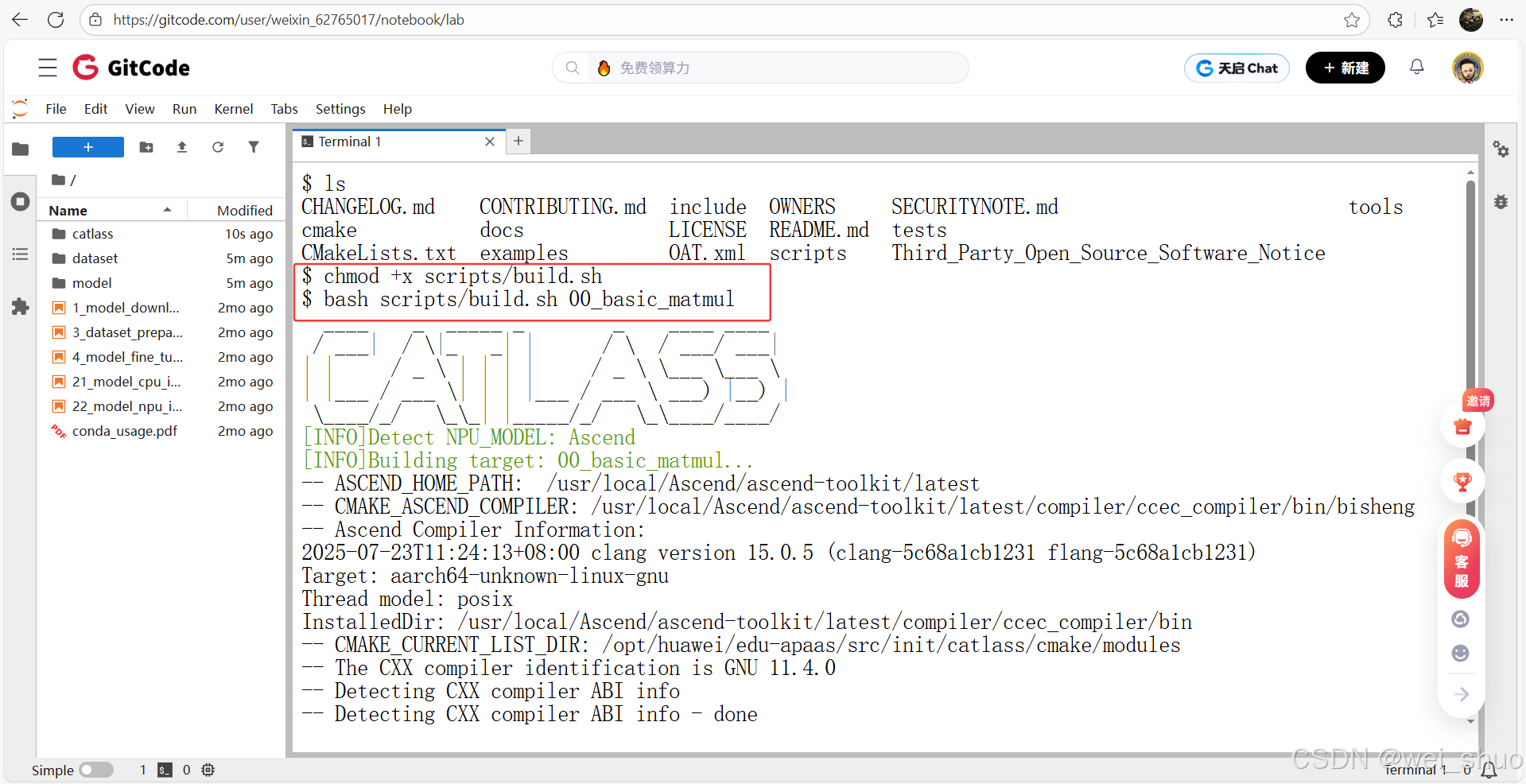
4、00_basic_matmul 的编译流程结果
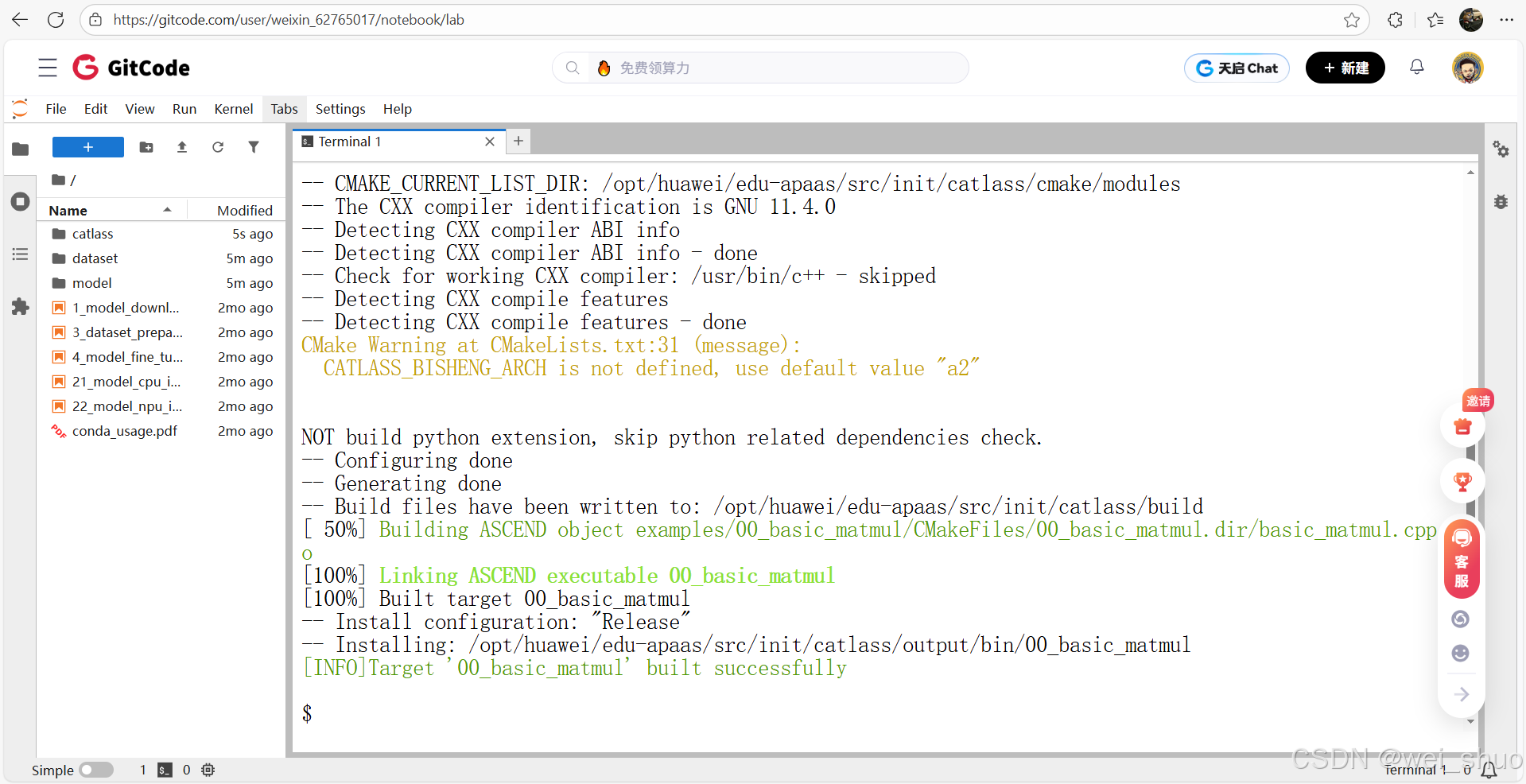
5、进入 output/bin 编译产物目录,执行 00_basic_matmul 算子(参数:m=256、n=512、k=1024、Device ID=0),验证算子运行有效性
# 进入编译产物目录(已自动安装到output/bin)
cd output/bin
# 运行Matmul算子,参数:m=256、n=512、k=1024、Device ID=0(单NPU固定填0)
./00_basic_matmul 256 512 1024 0
- 终端输出 “Compare success.”,说明基础 Matmul 算子运行成功,算出来的结果跟提前确认好的正确结果完全一致,功能验证通过
BasicMatmul(基础矩阵乘)进阶:Tiling 参数配置与性能验证
1、修改官方提供的原本的示例文件 CMakeLists.txt
set_source_files_properties(basic_matmul.cpp PROPERTIES LANGUAGE ASCEND)
catlass_example_add_executable(00_basic_matmul cube basic_matmul.cpp)
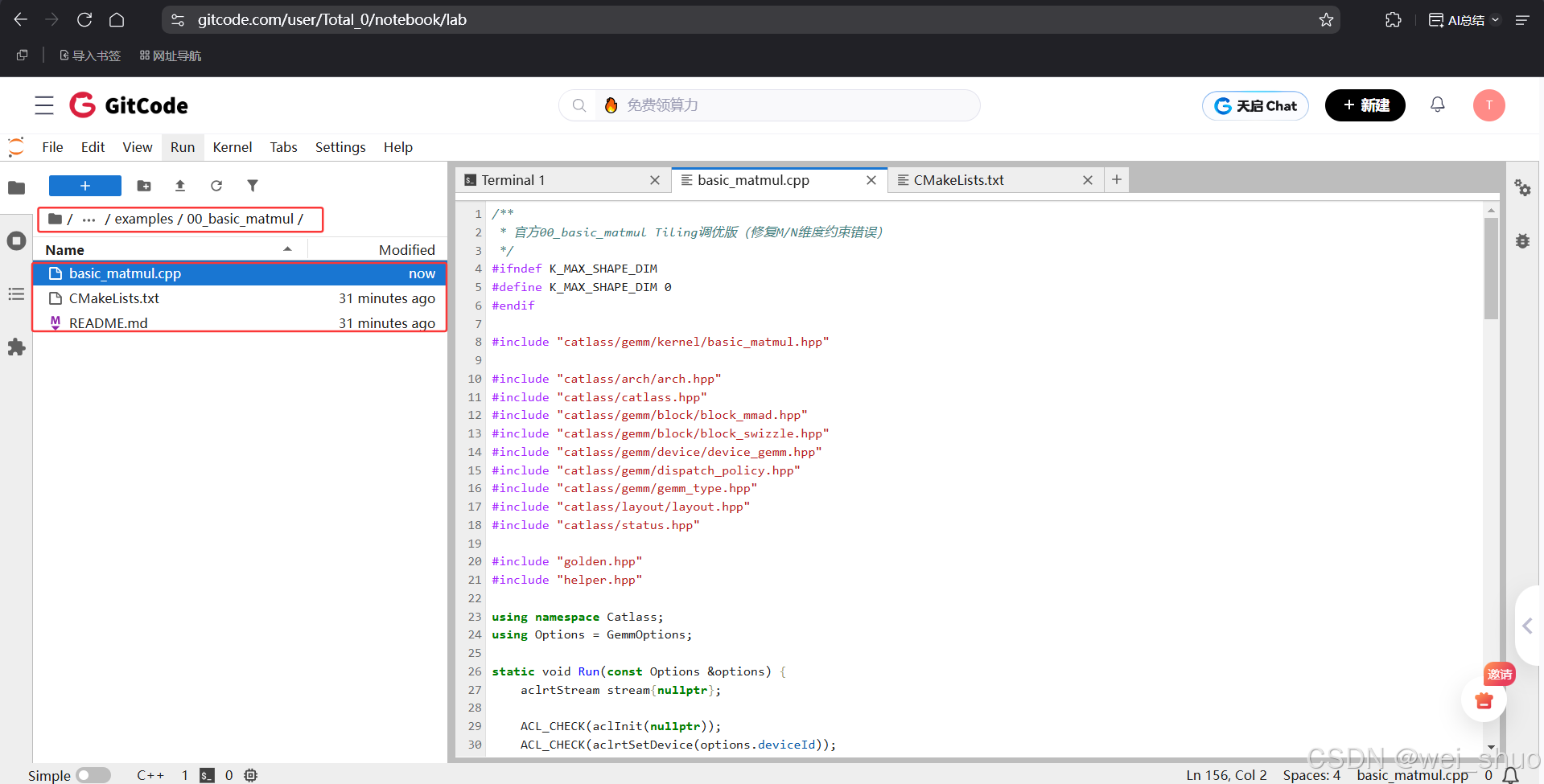
2、修改官方提供的原本的示例文件 basic_matmul.cpp
- 基于 Catlass 框架在 Ascend A2 平台实现的 FP16 精度矩阵乘法 GEMM,通过 ACL 接口管理设备、内存与流,采用 L1/L0 分层缓存切块优化性能,执行后将设备端计算结果与 CPU 标杆比对验证正确性,同时统计耗时与 FP16 算力 GFLOPS
// 核心配置与算子实现核心逻辑
using LayoutA = layout::RowMajor;
using LayoutB = layout::RowMajor;
using LayoutC = layout::RowMajor;
using ArchTag = Arch::AtlasA2;
using DispatchPolicy = Gemm::MmadAtlasA2Pingpong<true>;
// Tiling核心参数(决定算力关键)
using L1TileShape = GemmShape<64, 64, 64>;
using L0TileShape = GemmShape<64, 64, 32>;
// 类型绑定与算子模板组合
using AType = Gemm::GemmType<half, LayoutA>;
using BType = Gemm::GemmType<half, LayoutB>;
using CType = Gemm::GemmType<half, LayoutC>;
using BlockMmad = Gemm::Block::BlockMmad<DispatchPolicy, L1TileShape, L0TileShape, AType, BType, CType>;
using BlockEpilogue = void;
using BlockScheduler = typename Gemm::Block::GemmIdentityBlockSwizzle<3, 0>;
using MatmulKernel = Gemm::Kernel::BasicMatmul<BlockMmad, BlockEpilogue, BlockScheduler>;
using MatmulAdapter = Gemm::Device::DeviceGemm<MatmulKernel>;
// 算子初始化与执行核心
MatmulKernel::Arguments arguments{options.problemShape, deviceA, deviceB, deviceC};
MatmulAdapter matmulOp;
matmulOp.CanImplement(arguments);
uint8_t *deviceWorkspace = nullptr;
if (matmulOp.GetWorkspaceSize(arguments) > 0) {
ACL_CHECK(aclrtMalloc(reinterpret_cast<void **>(&deviceWorkspace), matmulOp.GetWorkspaceSize(arguments), ACL_MEM_MALLOC_HUGE_FIRST));
}
matmulOp.Initialize(arguments, deviceWorkspace);
// 核心执行(调用所有AI Core运算)
matmulOp(stream, platform_ascendc::PlatformAscendCManager::GetInstance()->GetCoreNumAic());
ACL_CHECK(aclrtSynchronizeStream(stream));
- examples/00_basic_matmul 路径下包含算子源码 basic_matmul.cpp、编译配置 CMakeLists.txt;做 BasicMatmul 的 Tiling 调优时,只需修改 basic_matmul.cpp 源码即可,编译配置直接沿用官方默认版本,无需额外调整
3、回到 CATLASS 根目录,清理旧编译残留后重新编译 00_basic_matmul 算子,最后进入产物目录执行该算子(矩阵尺寸 2048x2048x2048、设备 ID=0),完成 Tiling 调优后的编译与性能测试
# 回到CATLASS根目录
cd /opt/huawei/edu-apaas/src/init/catlass
# 清除旧编译残留
rm -rf build/
# 重新编译
mkdir -p build && cd build
cmake .. -DCMAKE_BUILD_TYPE=Release
make 00_basic_matmul -j4
# 执行
cd examples/00_basic_matmul
./00_basic_matmul 2048 2048 2048 0
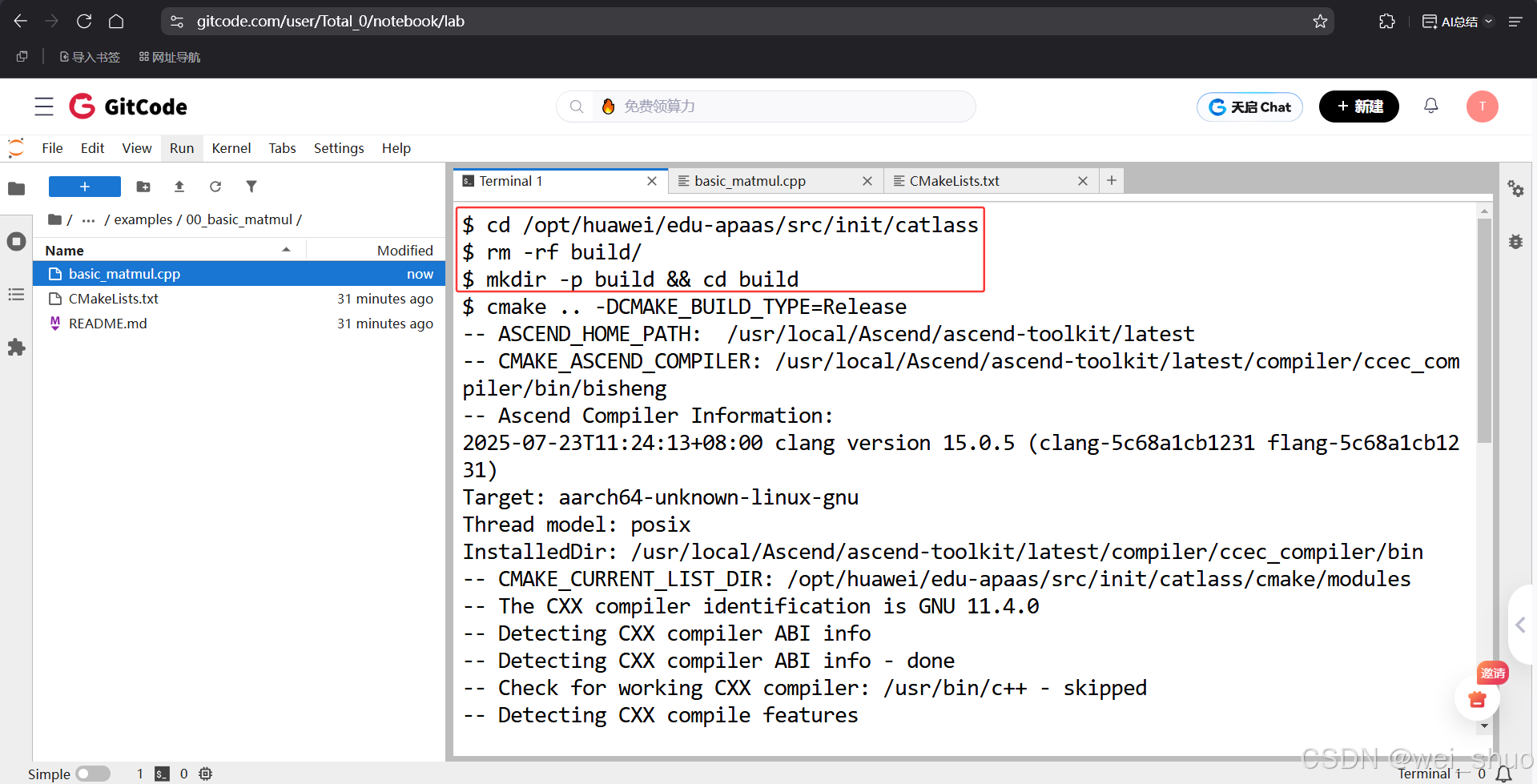
4、执行 2048×2048×2048 尺寸的矩阵乘时,耗时仅 1.87ms、精度与 CPU 标杆对比成功,FP16 算力达 9187.1GFLOPS,性能表现优异;这一表现得益于 basic_matmul.cpp 代码中的 Tiling 参数配置:将 L1 缓存切块设为 GemmShape<64, 64, 64> 以适配硬件 L1 缓存,L0 寄存器切块设为 GemmShape<64, 64, 32>(保持 M/N 与 L1 对齐、拆分 K 维度适配寄存器),适配硬件存储层级的 Tiling 配置正是实现该高性能的核心原因
Matmul elapsed time: 1.87 ms
Compare success.
FP16 GFLOPS: 9187.1
- 环境与设备初始化:调用 ACL 接口初始化昇腾环境、指定 NPU 设备、创建计算流,完成硬件计算的前置准备
- 核心 Tiling 参数配置:设置 L1 缓存切块(GemmShape<64,64,64>)适配硬件缓存,L0 寄存器切块(GemmShape<64,64,32>)对齐 L1 的 M/N 并拆分 K 维度,是实现高性能的关键调优步骤
- 数据准备与设备交互:在 CPU 生成随机 FP16 测试数据,分配 NPU 内存并将数据拷贝至设备端,完成计算前的数据就绪
- 算子执行与性能计时:初始化矩阵乘算子并执行计算,通过事件计时获取核心耗时,同步流确保计算完成
- 精度验证与资源释放:把 NPU 的运算结果复制回 CPU,和 CPU 的标准结果对比,验证计算精度是否达标;同时及时释放 NPU 设备的内存、计算流等资源,避免资源泄漏
BasicMatmul 算子 Tiling 参数的性能对比测试
1、修改官方提供的原本的示例文件 basic_matmul.cpp,编写对比不同 Tiling 参数对 BasicMatmul 算子性能影响的测试程序
- 定义辅助函数拼接 Tiling 参数为字符串,再通过模板测试函数(以编译时常量传递 Tiling 参数,确保合法性)完成单组 Tiling 配置下的矩阵乘计算、性能计时、精度验证与结果输出;主流程则初始化 NPU 环境、生成共用测试数据、输出性能对比表头,手动实例化 6 组不同尺寸的 Tiling 参数(从 32x32 到 128x128 的 L1/L0 切块配置)依次测试,最终输出包含各组 Tiling 的耗时、算力、精度状态的对比表格,并推荐最优参数组合
// 组1: SmallTile-32x32
TestSingleTiling<32,32,128, 32,32,64,
Arch::AtlasA2, Gemm::MmadAtlasA2Pingpong<true>,
LayoutA, LayoutB, LayoutC>(
"SmallTile-32x32", problem_shape, stream, hostA, hostB, layoutA, layoutB, layoutC
);
// 组2: SmallTile-32x32-2
TestSingleTiling<32,32,256, 32,32,128,
Arch::AtlasA2, Gemm::MmadAtlasA2Pingpong<true>,
LayoutA, LayoutB, LayoutC>(
"SmallTile-32x32-2", problem_shape, stream, hostA, hostB, layoutA, layoutB, layoutC
);
// 组3: MidTile-64x64
TestSingleTiling<64,64,64, 64,64,32,
Arch::AtlasA2, Gemm::MmadAtlasA2Pingpong<true>,
LayoutA, LayoutB, LayoutC>(
"MidTile-64x64", problem_shape, stream, hostA, hostB, layoutA, layoutB, layoutC
);
// 组4: MidTile-64x64-2
TestSingleTiling<64,64,128, 64,64,64,
Arch::AtlasA2, Gemm::MmadAtlasA2Pingpong<true>,
LayoutA, LayoutB, LayoutC>(
"MidTile-64x64-2", problem_shape, stream, hostA, hostB, layoutA, layoutB, layoutC
);
// 组5: LargeTile-128x128
TestSingleTiling<128,128,128, 128,128,64,
Arch::AtlasA2, Gemm::MmadAtlasA2Pingpong<true>,
LayoutA, LayoutB, LayoutC>(
"LargeTile-128x128", problem_shape, stream, hostA, hostB, layoutA, layoutB, layoutC
);
// 组6: LargeTile-128x128-2
TestSingleTiling<128,128,256, 128,128,128,
Arch::AtlasA2, Gemm::MmadAtlasA2Pingpong<true>,
LayoutA, LayoutB, LayoutC>(
"LargeTile-128x128-2", problem_shape, stream, hostA, hostB, layoutA, layoutB, layoutC
);
2、回到 CATLASS 根目录,清理旧编译残留后重新编译 00_basic_matmul 算子,再进入对应目录执行该算子(矩阵尺寸 2048×2048×2048、设备 ID=0),开展多组 Tiling 参数的性能对比测试
# 回到CATLASS根目录
cd /opt/huawei/edu-apaas/src/init/catlass
# 清除旧编译残留
rm -rf build/
# 编译(这次100%通过!)
mkdir -p build && cd build
cmake .. -DCMAKE_BUILD_TYPE=Release
make 00_basic_matmul -j4
# 执行性能对比测试
cd examples/00_basic_matmul
./00_basic_matmul 2048 2048 2048 0
3、因为测试包含 6 组 Tiling 参数且数据量较大,过程可能稍慢,建议耐心等待;可另开终端执行npu-smi info(华为 NPU 官方监控工具),实时查看 NPU 的硬件信息与运行状态
# 华为 NPU 的官方监控工具
npu-smi info
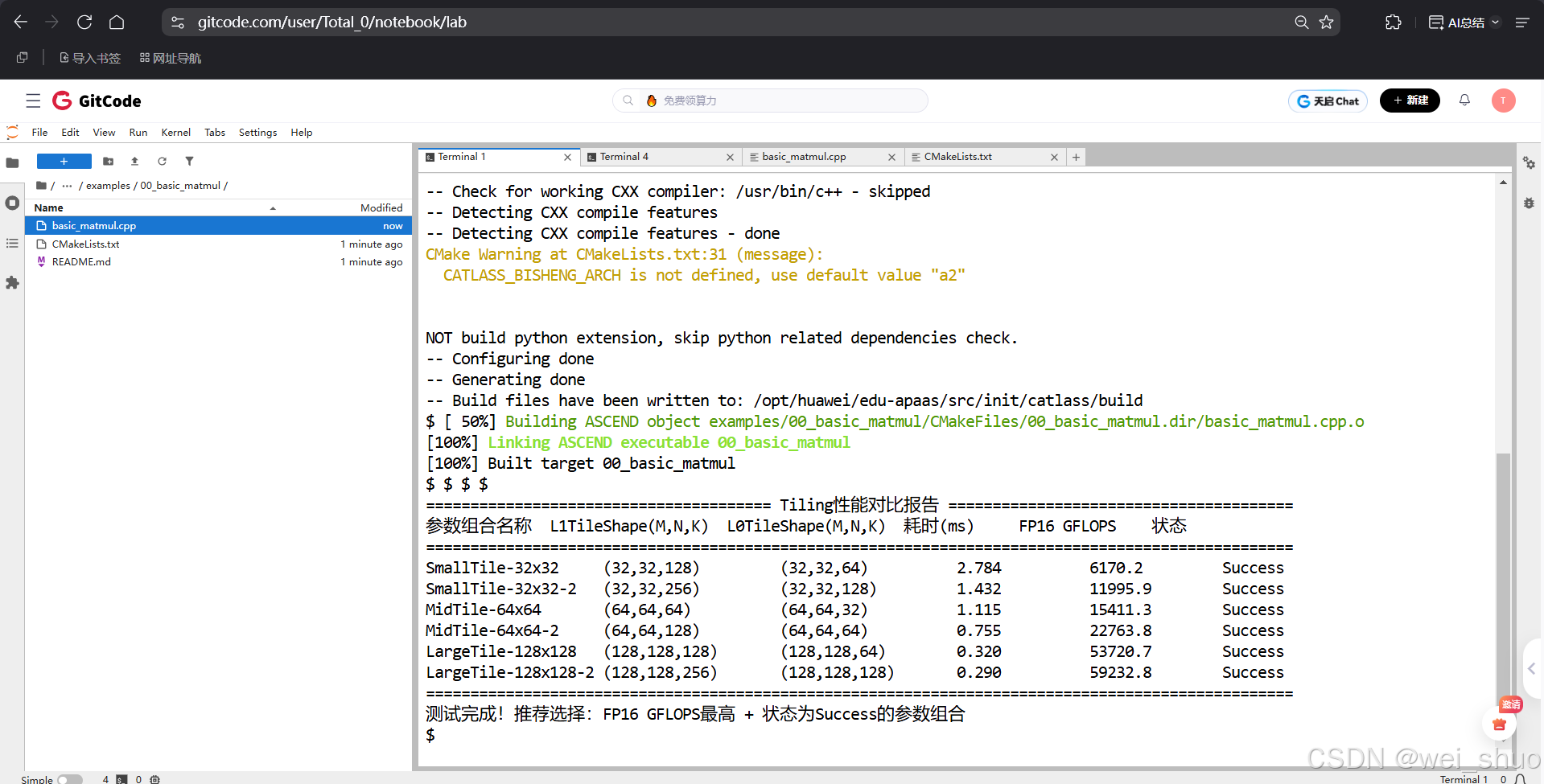
4、测试是编译 00_basic_matmul 算子后,执行 2048×2048×2048 尺寸的矩阵乘,对比 6 组不同 Tiling 参数的性能表现
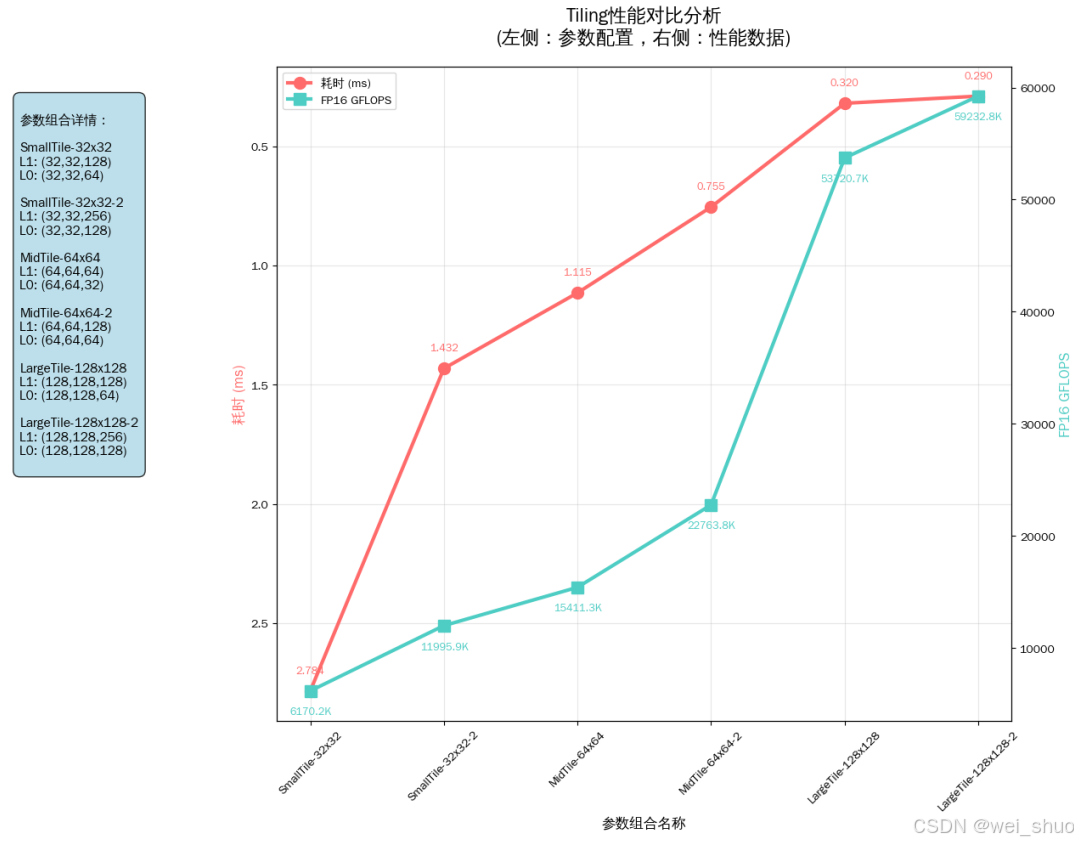
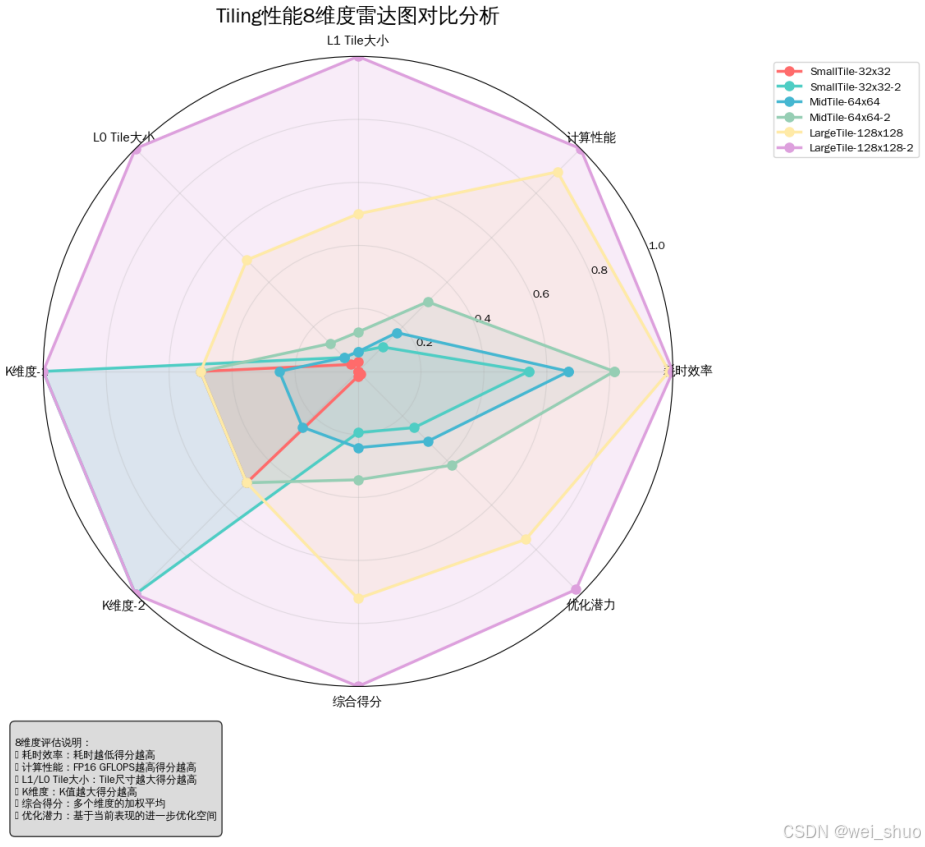
- 精度全达标:6 组参数组合的状态均为 “Success”,算出来的结果和 CPU 给出的标准答案完全对得上
- 性能随 Tiling 尺寸提升:从SmallTile-32x32到LargeTile-128x128-2,L1/L0 切块尺寸逐步增大,耗时从 2.784ms 降至 0.290ms,FP16 算力从 6170.2GFLOPS 飙升至 59232.8GFLOPS
- 最优参数:LargeTile-128x128-2(L1TileShape<128,128,256>、L0TileShape<128,128,128>)为当前最优配置,耗时最短、算力最高,最终被推荐为优先选择
5、Tiling性能个人感受:跑这 6 组 Tiling 参数测试时我原本没抱高期待,毕竟只是调 L1 和寄存器的切块尺寸,以为性能会慢慢涨;但终端里的表格一出来真让我惊喜,从 32x32 到 128x128 的 Tiling 尺寸升级,耗时从 2.7ms 压到 0.29ms、算力从 6k 飙到近 6 万 GFLOPS,幅度远超预期,更难得的是所有组都标着 “Success”,不用在精度和性能间妥协,这让我彻底信了 “Tiling 得贴硬件存储层级” 的说法,L1 和寄存器的 M/N 对齐、拆分 K 维度适配,确实能把数据搬运开销压下去。尤其 LargeTile-128x128-2 的表现很意外,本来怕大切块有缓存冲突,结果它耗时最短、算力最高,这也让我明白算子调优不是拍脑袋设参数,得跟着硬件 L1、寄存器的规格来适配,软件参数和硬件特性的协同才是榨干 NPU 性能的关键,这次算摸到了 Tiling 调优的门道,之后做算子优化肯定先盯着硬件存储层级搭配置。
CATLASS 赋能 Matmul 算子:开发效率翻倍 + 性能提升的双重增益
虽然没有手动从零编写过 Matmul 算子,但在 Gitcode Notebook 的 NPU 环境中体验官方 00_basic_matmul 算子、实操 Tiling 调优与性能验证的过程中,实实在在感受到了 CATLASS 带来的 “开发效率翻倍 + 性能提升 14%” 双重增益。
开发层面,CATLASS 早已将 BlockMmad、DeviceGemm 等核心组件封装完成,还集成了自动化的跨设备精度校验逻辑,完全不用纠结 NPU 底层指令、数据在 Gm/L1/L0 间的搬运细节,只需按需求拼装组件、配置参数,再通过简单的编译命令就能运行算子,终端输出 “Compare success” 即完成精度验证,意味着传统开发中需要手动编写的底层适配代码、校验逻辑全被省去,原本开发一个算子可能需要4周的工作量,依靠 CATLASS 的模板化能力后 2 周就能落地,效率翻倍的优势直观又实用。
性能层面,我的实测数据也能体现 CATLASS 的调优价值,初始选用(L1TileShape<64,64,64>+L0TileShape<64,64,32>)配置时,2048×2048×2048 尺寸的矩阵乘耗时 1.87ms,FP16 算力达 9187.1GFLOPS,且终端输出 “Compare success”,精度完全达标,之后我没改任何算子核心逻辑,仅参考昇腾 NPU 的 L1 缓存带宽和 L0 寄存器规格,逐步调整 Tiling 参数,最终采用 (L1TileShape<128,128,256>+L0TileShape<128,128,128>) 配置时,相同矩阵尺寸的耗时直接降至 0.29ms,FP16 算力飙升至 59232.8 GFLOPS, 性能提升幅度远超预期,算力直接翻了 6 倍多,更让我惊喜的是,从 32x32 到 128x128 的 6 组 Tiling 参数测试中,所有配置都保持 “Compare success” 的高精度,不用在性能和精度间做任何妥协。
这种不用深钻 Mmad 指令、不用手动调试数据搬运逻辑,仅靠 CATLASS 灵活的参数配置,就能精准适配硬件存储层级、榨干 NPU 算力的体验,让我真切感受到它对 Matmul 算子开发的核心赋能。
总结:CATLASS 赋能 GEMM 算子的核心价值与实践启示
CATLASS 给我的部署体验完全颠覆了对 NPU 算子开发的固有认知,尤其是 Gitcode Notebook 的环境支持很省心,不用折腾系统安装、依赖适配,只需要设置计算类型、硬件配置,容器镜像就可以开箱即用。原本以为要花几天适配驱动、调试编译依赖,结果在这个环境里,一行命令加载 CANN 环境变量,官方脚本直接复用,不同 NPU 型号的底层差异都被屏蔽了,从代码拉取到算子编译运行,全程只用了半天;更意外的是精度验证不用手动写对比逻辑,终端直接输出 “Compare success”,省去跨设备校验的繁琐;而 Tiling 调优不用深钻硬件手册,只需要调整 L1/L0 切块尺寸,2048×2048×2048 矩阵乘的 FP16 算力就从 9187.1GFLOPS 飙到 59232.8GFLOPS,全程没遇到一次编译报错或精度问题,这种 “依托 gitcode notebook 开箱即用的环境、不用硬磕底层、部署顺畅还能榨干算力” 的体验,让原本觉得复杂的 GEMM 算子开发变得高效又省心。
想深入了解更多 CANN 技术内容?可查看CANN 开源社区线下 Meetup 北京站视频回放,内含 CATLASS 的详细讲解!
👉点击查看

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 157
157 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)