CANN ops-math算子仓之BitwiseAnd算子贡献
ops-math仓提供了算子工程模板,极大的提高了算子开发效率;,算子的开发并不是一蹴而就的,而是不断经过调试和优化的,这是一个不断迭代的过程,直到算子的功能和性能符合需求为止,在这个过程中需要不断地进行调试、调优,官方在调试调优上提供两个API:一个printf可以用来打印标量或在指定位置插入,打印指定内容;通过图片我们可以看到指令的执行顺序,还有vector的指令有VAND,执行了一次,执行的
摘要
本文主要讲述BitwiseAnd算子从开发到pr合入的全流程体验,最大的感受就是提供了一站式开发平台,直接杜绝繁琐的环境部署;ops-math仓提供了算子工程模板,极大的提高了算子开发效率;提交pr后,专家审核快速,合入时间短。通过本次的体验还感受到Ascend C编程语言的上手难度低,可以直接通过调用相关功能的API,直接实现算子的与运算。对于API提供了不同的使用方式,可以通过mask来实现更高级的功能,也可以直接使用数据长度进行调用,降低开发难度。
一、背景
该算子源于CANN2025年训练营任务,需要对齐已经实现的tbe算子,tbe算子的算子原型支持的数据类型有int16、uint16和int32,支持的数据排布格式是ND,要实现的功能是算子的与运算。
二、ops-math仓介绍
先来介绍下ops-math仓,它主要存放与数学运算相关的算子,该仓的算子都是在NPU的环境下使用Ascend C来进行实现的。目录分为公共代码、算子实现、示例和测试等部分。算子实现包括Host侧逻辑、Device侧Kernel、以及UT测试等模块,该仓目前已经实现了很多的math类算子可以直接使用,开发者也可以提pr贡献自己的math算子。
三、环境安装及测试
开发者可以通过点击昇腾社区右上角的"在线开发",会跳转到如下页面,点击体验Notebook,就有香喷喷的CANN8.5环境使用,不用再自己额外安装环境或任何依赖了,直接避免了繁琐的环境配置,我作为之前被环境安装配置折磨过的开发者,这简直就是最大的福音!
四、算子设计及核心实现
在进入算子分析之前,给开发者们一些经验分享:如果是新手,开发第一个算子可以先基于Kernel直调的调用方式来实现,该方式的优势在于,让开发者聚焦Kernel实现,不需要进行复杂的动态tiling设计,而且编译时间更短,可以快速验证算子功能,缩短核函数开发时间;核函数功能没问题之后就可以编写算子工程,就可以把精力放在tiling策略和UT测试上。
因为这个算子功能比较简单,所以我选择直接用算子工程方式。在ops-math仓贡献算子时除了算子工程实现还要有ut测试和README说明文档,看上去需要的东西有点多,不过好在仓上已经有了算子样例,可以直接复制过来,只需要改一改就好。
接下来让我谈一谈BitwiseAnd算子的开发历程,在前面我们介绍了算子的背景,知道要实现的算子的数据类型有int16、uint16和int32。查看算子的py文件,发现就是调用vand接口进行与运算。Ascend C对应的API接口是And,但是在官方文档里面关于And API支持的数据类型只有int16和uint16数据类型。
那么问题来了,对于int16和uint16类型可以直接调用,int32类型不支持怎么办?
BitwiseAnd算子的功能是将数据按位进行与操作,也就是说跟实际的数据类型和具体数值大小其实是没有关系的。一个int32就是2个int16或者2个uint16。问题就转换为如何将int32类型按照int16类型解释,查找官方API文档找到了ReinterpretCast接口。
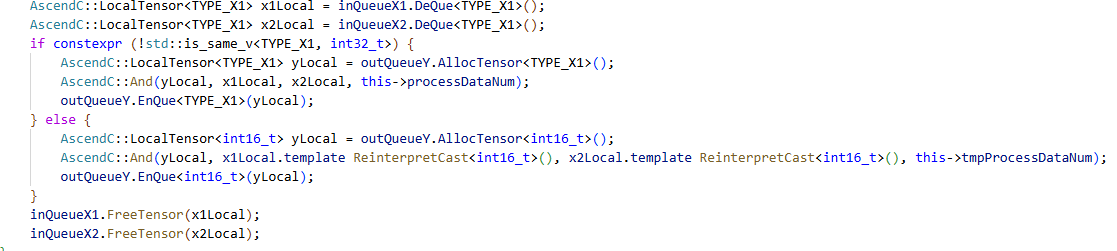
官方给的调用示例如下图:

在最开始使用这个API时,我是通过创建额外的临时变量来接收重解释后的数据。但发现这样操作浪费了额外不必要的空间,实际上可以直接将输入x1Local和x2Local重解释后直接使用的,所以有了下面的版本。
接下来就是Host侧Tiling的设计,该算子的tiling设计可以参考其他逐元素操作算子的实现。
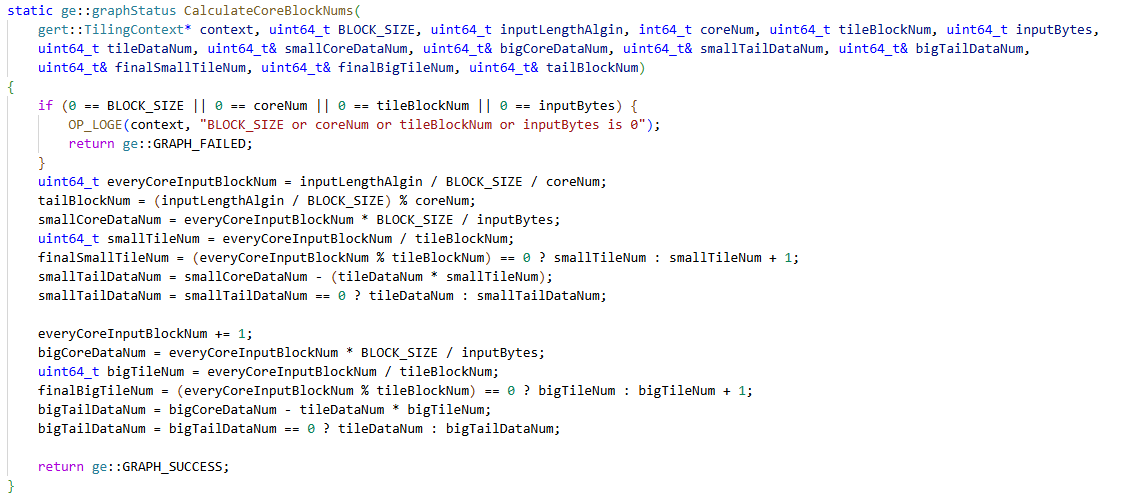
不过需要注意的点时在处理int32类型时,需要将数据数量做翻倍的处理(为了便于维护,上仓不能有魔鬼数字,所以宏定义INT32_DOUBLE_DATA=2):

如果开发者想要了解这个算子的更多信息,可以去ops-math仓查看,也可以直接点击链接:BitwiseAnd。
五、算子功能测试
当完成上述操作后算子的实现过程其实就算完成了,但是还需要进行测试算子功能是否正确,性能是否足够达标。而测试算子ops-math仓提供了两种调用方式进行测试:UT和aclnn调用方式,具体参考文档:算子调用。
首先介绍UT方式,需要在算子工程目录下创建tests目录,编写ut测试代码,不用从0开始编写,可以参考现有算子根据开发算子的类型及实现的功能做出相应进行的修改。在编写完成后即可进行测试,UT提供了针对不同的部分有不同的测试方式:op_api、op_host和op_kernel。如下就是测试kernel侧是否正确的指令:
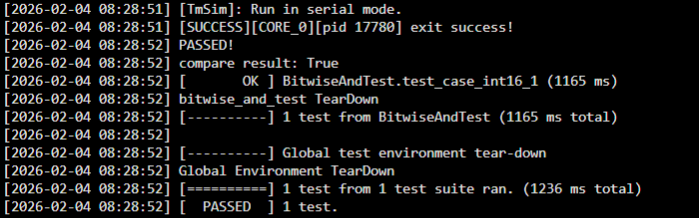
bash build.sh -u --opkernel --ops=bitwise_and --experimental
有如下图的输出,就说明算子测试通过:
因为ut仅包含了一种shape方式,因此需要开发者对输入的shape和数据类型进行不断的修改,来确保算子有足够的泛化能力。
测试算子除了ut测试外,还可以通过aclnn调用的方式进行测试,可以使用ascendoptest工具进行算子功能和性能的测试。
六、算子性能测试
ops-math仓关于算子的调试和调优提供了详细的指导:算子调试调优操作,算子的开发并不是一蹴而就的,而是不断经过调试和优化的,这是一个不断迭代的过程,直到算子的功能和性能符合需求为止,在这个过程中需要不断地进行调试、调优,官方在调试调优上提供两个API:一个printf可以用来打印标量或在指定位置插入,打印指定内容;另一个是DumpTensor可以用来打印计算过程中的LocalTensor的具体数值。其次还提供了性能测试工具msProf,它可以采集和分析运行在昇腾AI处理器上算子的关键性能指标。
在完成了上面的功能测试后,接下来就进入性能测试部分。
在性能测试我们通过ascendoptest工具进行测试,测试命令为:
python run_test.py -i ../case/bitwiseand.json -c ../case/case.json --build --op-type custom --op --msprof
会显示算子运行的时间和实际运行的AiCore核数,具体如下图:
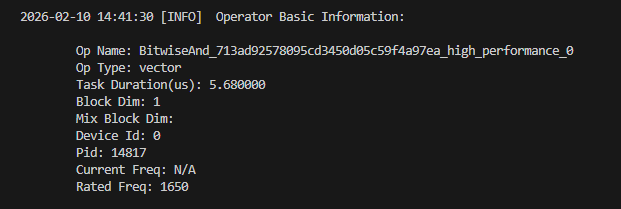
其中Task Duration就是算子的执行时间,单位是us,BlockDim是核数。除了性能测试时的打屏信息,还会生成详细的性能测试信息目录,具体的目录结构如下图:
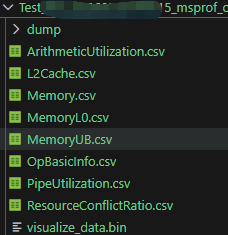
其中的OpBasicInfo表格记录了算子的基本信息,包括算子名称和运行时间。作为性能优化的重要参考就是计算和搬运过程中的耗时及占比,而PipeUtilization.csv文件则详细记录了这一切,包括每个核上的耗时都完整的记录了下,记录了scalar计算、vector计算以及数据搬运过程分别消耗的时间,为性能优化指明了方向。
如下图所示,可以看到算子的scalar的耗时占比比较大,那么就可以考虑scalar的计算是否可以进一步优化,比如减小kernel侧的scalar计算,或者将非必要的scalar计算放到host侧完成。
这是优化前,scalar耗时为4.08us:

优化后,scalar耗时降到了3.17us:

此外我们还可以进行仿真操作,首先需要配置仿真环境变量:
#配置环境变量
export LD_LIBRARY_PATH=/usr/local/Ascend/tools/simulator/Ascend910B4/lib:$LD_LIBRARY_PATH
其次执行仿真测试,在这里说一个我走过的坑,就是做仿真测试输入的数据尽可能的小一些,如果数据shape比较大,仿真测试完成一个case要等很久,而且生成的文件也会很大,不便于查看,因此建议用小shape跑仿真。结果如下图:
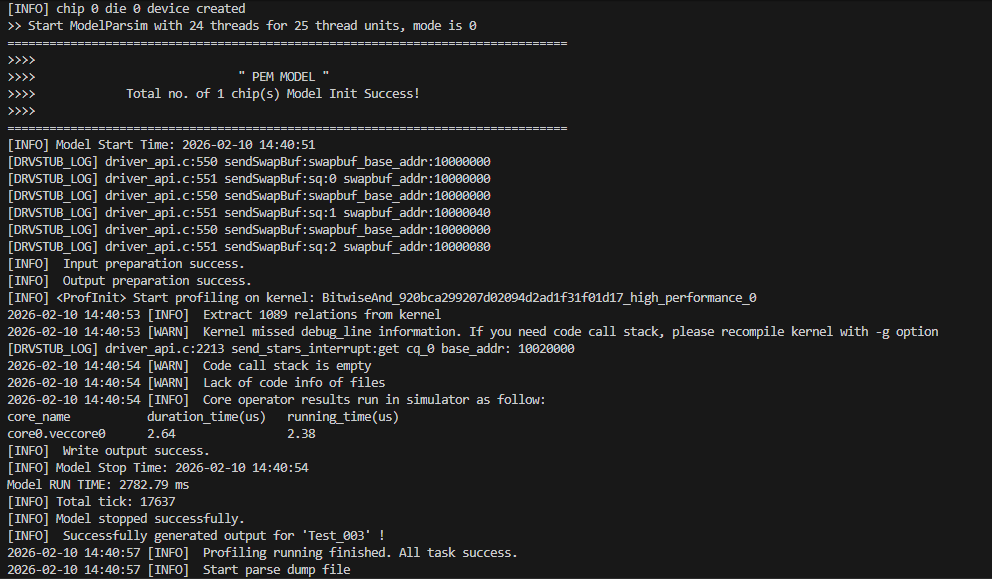
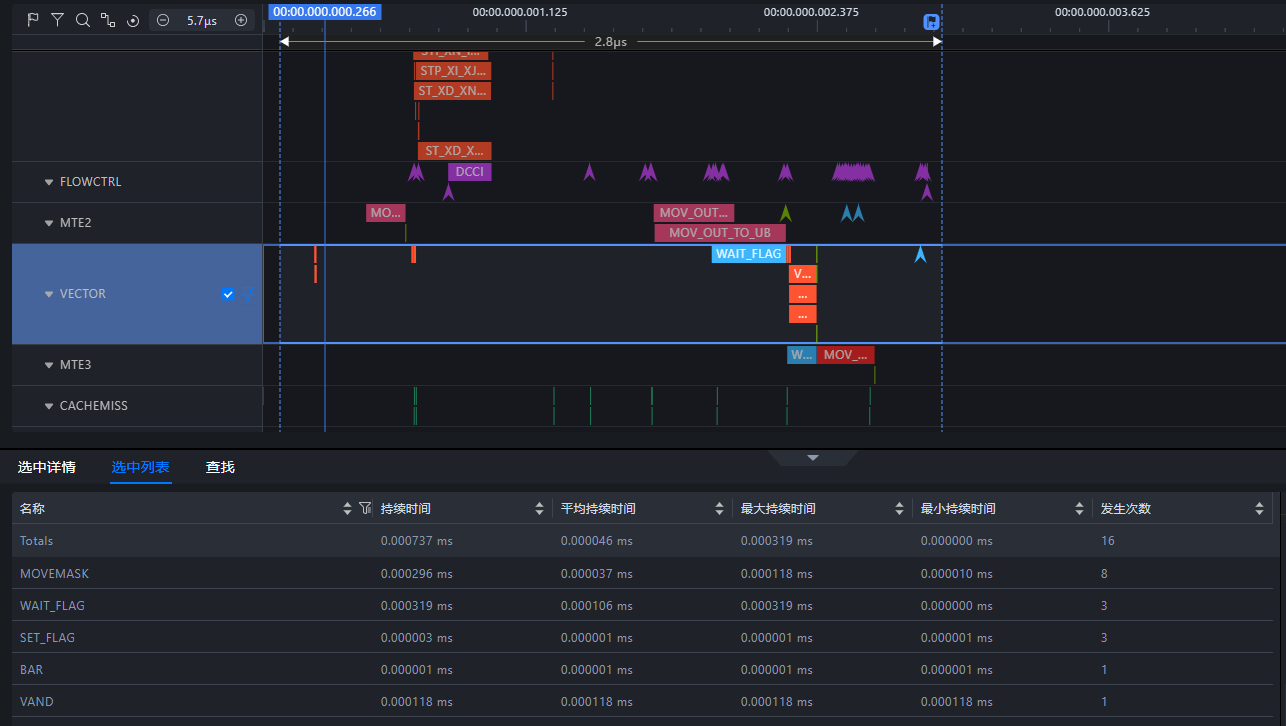
可以看到仿真测试也会打印出算子的执行时间,仿真的目录结果如下,其中trace.json和visualize_data.bin文件包含了指令流水。通过官方文档得知,提供了两种方式查看算子指令执行情况。其中bin结尾的文件可以通过MindStudio Insight官方的工具查看仿真流水,其次还提供了trace.json文件,可以不用工具就能查看指令的执行,使用浏览器就行,不用额外下载工具也能查看。
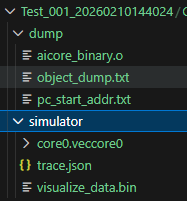
通过图片我们可以看到指令的执行顺序,还有vector的指令有VAND,执行了一次,执行的时间是0.000118 ms,很直观的能够看到算子的每条指令的执行过程,确定该算子没有执行多余的指令。仿真指令如下图:
七、算子贡献
pr的合入流程分为创建pr、专家给出检视意见、修改检视意见和pr合入。
创建pr之前需要拉取下需要最新的分支,然后将算子工程放到指定的目录下,之后就可以创建pr。pr创建后需要执行compile,进行门禁测试。门禁包含了codeckeck、SCA、病毒扫描、编译、UT测试等多个测试环节。门禁执行时间比较久,半个小时左右。代码审核部分失败了,因为有魔鬼数字所以无法通过门禁,修改后codecheck通过。
门禁失败,给的原因都是很直接明了的,可以很直观的看到自己哪一部分代码有问题,很容易进行修改。评审专家的审核也是比较严格的,包括README、代码风格是否一致等等,保证了仓上算子的准确性。
具体的可以点击pr合入链接:BitwiseAnd算子贡献。

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)