Ascend C与CANN架构深度解析:从硬件融合到算子开发实战
🚀摘要:本文深度解析昇腾AI软件栈CANN的"软硬件协同"设计精髓,将AscendC编程模型比作连接AI算法与NPU硬件的"神级翻译官"。文章通过实战案例揭示三级存储架构的关键性,指出"数据搬运"比"计算"更影响性能的核心认知,并演示双缓冲流水线优化的向量加法实现。作者提出两种开发范式:快速原型适合算法验证,工程化手
目录
🛠️ 第二部分:Ascend C语法 —— “SOP”的书写规则
🚀 摘要
本文带你穿透昇腾AI软件栈CANN的层层抽象,直抵其“软硬件协同”设计的核心。我将以多年老兵的视角,用大白话拆解Ascend C编程模型为何是连接AI算法与NPU硬件的“神级翻译官”。文章将彻底抛开理论手册,聚焦实战,清晰展示从一条C++代码到AI Core晶体管如何“闪动”的完整旅程。你将理解为何三级存储是命门、为何“搬数据”比“算数据”更关键,并最终能亲手用两种截然不同的开发思维(快速原型 vs. 工程化手搓)实现高性能算子。我会用真实项目数据告诉你,何时该“相信编译器”,何时必须“手搓底层”来压榨硬件。
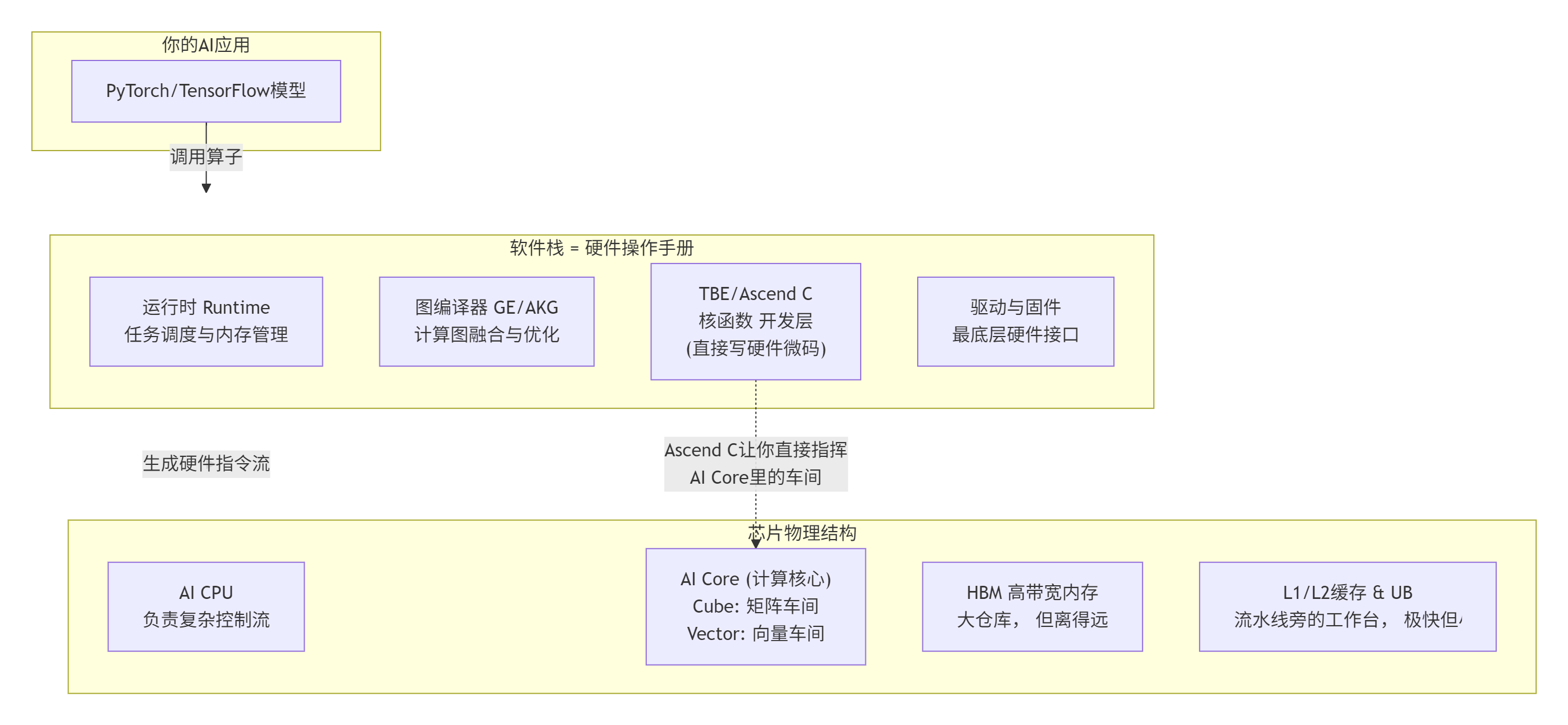
🧱 第一部分:CANN不是软件栈,是“硬件说明书”
干了这么多年高性能计算,我见过太多人把CANN(Compute Architecture for Neural Networks)简单理解成类似CUDA的驱动和运行时库。这个认知偏差,是很多人学Ascend C感到别扭的根源。
让我说句大白话:CANN,特别是Ascend C,本质上是一份用软件语言写就的、极其详尽的“昇腾NPU硬件使用说明书”。 它的每一个设计,都死死对应着底下那块芯片的物理结构。你不按说明书来,硬件就“不干活”或者“干得慢”。
这跟CPU/GPU的玩法完全不同。CPU是全能管家,你告诉它“解这个方程”,它自己会安排步骤。GPU是流水线工厂,适合大批量标准件生产。
昇腾的AI Core呢?它是个高度定制化、流程极度固定、但对“物料”和“节奏”有变态要求的“高端芯片实验室”。CANN就是教你如何正确给这个实验室“送样”、“操作仪器”和“记录数据”的标准操作程序(SOP)。
下面这张图,就是这份“SOP”的总体结构,它解释了你的代码是如何一层层“沉”到硬件里去的:
必须刻在脑子里的三个硬件现实,它们直接决定了CANN和Ascend C的长相:
-
三级存储是性能的生死线:这跟GPU的全局内存+共享内存不一样。HBM容量大(GB级)但延迟高,好比“中心仓库”。真正贴着计算单元(Cube/Vector)的Unified Buffer (UB) 和Local Memory (LM),是“实验台”,速度极快但容量极小(KB-MB级)。Ascend C编程一半以上的心思,都花在怎么把数据从“仓库”高效、不间断地搬到“实验台”上,并让计算单元别闲着。 性能瓶颈十有八九卡在这条“物流链”上。
-
Cube和Vector是两条不同的“生产线”:Cube是专门做密集矩阵乘加的“定制化重型机床”,吞吐量恐怖但功能单一;Vector是“多功能精密车床”,能做各种向量操作(加、减、比较等)。好的程序得像乐队指挥,让这两条线高效协奏,别让一个等另一个“缺料”。
-
流水线(Pipeline)与双缓冲(Double Buffer)是保命符:在AI Core内部,数据搬运、矩阵计算、向量处理可以同时进行。就像工厂,上一批在加工,下一批已经在传送带上了。不搞流水线的Ascend C核函数,性能直接腰斩再腰斩。
所以,写Ascend C时,思维必须转变:别再想“我要算个加法”,而要想“我这批数据,该用多大‘盒子’(Tiling)从‘仓库’(HBM)搬到‘传送带入口’(UB),搬运工(DMA)走哪条路不堵,上了线先过‘机床A’(Cube)还是‘机床B’(Vector),节奏怎么卡,成品怎么打包回库”。CANN/Ascend C,就是定义这套“芯片实验室SOP”的语言。
🛠️ 第二部分:Ascend C语法 —— “SOP”的书写规则
明白了硬件要什么,就懂Ascend C的语法为什么这么设计。它不是什么通用语言,就是个给硬件下精密指令的“控制语言”,核心动词就三个:搬、算、等。
设计理念:把“物流与生产图纸”写成代码
Ascend C的关键字,全是物理世界的映射:
-
__gm__,__ub__,__local__:这不是普通指针,这是地址空间标签。__gm__表示在“远程仓库”,动它慢;__ub__表示已在“实验台”,动它快。编译器看到这些标签,就知道该生成“远程调货”指令还是“台上操作”指令。 -
Pipe(管道):这就是流水线。你定义一条Pipe,PipeProd端上料,PipeCons端加工,硬件会让它们并行。 -
Queue(队列):更灵活的任务同步工具,比Pipe底层,控制更细。 -
内建函数(Intrinsics):如
vec_add,mmad。这不是函数,是直接对应Vector单元、Cube单元硬连线的机器指令。你写vec_add,编译器几乎直接生成一条硬件指令。
关键思维转换:在Ascend C里,“=”赋值和“+”加法,成本可能差成百上千倍。c = a + b,如果a,b,c都在__ub__,这是一条高速指令。如果a在__gm__,那就隐含了一次漫长的“仓库调货”。很多新手算子性能血崩,就是因为没管数据在哪儿,无脑访问__gm__。
核心实现:手搓一个“带流水线”的向量加法
不搞虚的,我们写个真正有点“工业味”的、带双缓冲的向量加法。C = A + B, 长度totalLength。
// 文件:add_pipeline_kernel.h
// 语言:Ascend C
// 版本:CANN 7.0+
// 描述:展示双缓冲流水线的向量加法
// 1. 作战计划(Tiling结构体)
typedef struct {
int32_t totalLength;
int32_t tileLen; // 每块大小
int32_t numTiles; // 总块数
} AddTiling;
extern "C" __global__ __aicore__ void add_pipeline_kernel(
__gm__ const float* A,
__gm__ const float* B,
__gm__ float* C,
__gm__ const AddTiling* plan // Host传来的计划
) {
// 2. 当前AI Core(工人)领任务
uint32_t blockId = get_block_idx();
uint32_t numBlocks = get_block_dim();
int32_t tilesPerBlock = (plan->numTiles + numBlocks - 1) / numBlocks;
int32_t startTile = blockId * tilesPerBlock;
int32_t endTile = min(startTile + tilesPerBlock, plan->numTiles);
if (startTile >= endTile) return;
// 3. 在UB(工作台)准备两个缓冲区 -> 双缓冲
const int32_t BUFFER_SIZE = plan->tileLen;
__ub__ float* ubA[2];
__ub__ float* ubB[2];
__ub__ float* ubC[2];
for (int i = 0; i < 2; ++i) {
ubA[i] = (__ub__ float*)__ubuf_alloc(BUFFER_SIZE * sizeof(float));
ubB[i] = (__ub__ float*)__ubuf_alloc(BUFFER_SIZE * sizeof(float));
ubC[i] = (__ub__ float*)__ubuf_alloc(BUFFER_SIZE * sizeof(float));
}
// 4. 初始化流水线同步标签
uint32_t pipeId = 0;
uint32_t copyStage = 0; // 搬运阶段标签
uint32_t compStage = 1; // 计算阶段标签
// 5. 启动第一块数据的搬运(给缓冲区0上料)
int32_t currentTile = startTile;
int32_t offset = currentTile * plan->tileLen;
int32_t len = (currentTile == plan->numTiles - 1) ?
(plan->totalLength - offset) : plan->tileLen;
hacl::data_copy_async(ubA[0], A + offset, len * sizeof(float));
hacl::data_copy_async(ubB[0], B + offset, len * sizeof(float));
hacl::pipe_barrier(pipeId, copyStage); // 标记搬运任务
int currentBuf = 0; // 当前用于计算的缓冲区
// 6. 主循环:流水线运转!
for (int32_t t = startTile; t < endTile; ++t) {
// 6.1 等待当前计算所需数据搬完
hacl::wait_all(pipeId, copyStage);
// 6.2 加工:向量加法
vec_add(ubC[currentBuf], ubA[currentBuf], ubB[currentBuf], len);
// 6.3 异步将结果下料(写回HBM)
hacl::data_copy_async(C + offset, ubC[currentBuf], len * sizeof(float));
hacl::pipe_barrier(pipeId, compStage);
// 6.4 给下一块数据预搬运(如果还有)
int32_t nextTile = t + 1;
if (nextTile < endTile) {
int32_t nextBuf = 1 - currentBuf;
int32_t nextOffset = nextTile * plan->tileLen;
int32_t nextLen = (nextTile == plan->numTiles - 1) ?
(plan->totalLength - nextOffset) : plan->tileLen;
hacl::data_copy_async(ubA[nextBuf], A + nextOffset, nextLen * sizeof(float));
hacl::data_copy_async(ubB[nextBuf], B + nextOffset, nextLen * sizeof(float));
hacl::pipe_barrier(pipeId, copyStage);
}
// 6.5 等待当前块结果写回完成
hacl::wait_all(pipeId, compStage);
// 6.6 更新状态,切换缓冲区
offset = nextOffset;
len = nextLen;
currentBuf = 1 - currentBuf;
}
}说人话解读:
-
计划:
AddTiling告诉每个核心:活怎么切块。 -
领活:每个核心根据自己ID,认领自己的那几块。
-
两个工作台:申请两套UB缓冲区,一个干活时,另一个备料,这叫双缓冲。
-
流水线启动:先给0号台把第一批料(A, B数据)搬上来。
-
循环(精髓):
-
等料齐:等0号台的料上全。
-
加工:在0号台上做加法。
-
下料:把0号台的成品运走(写回结果C)。
-
给另一个台上料:在加工0号台的同时,指挥搬运工给1号台上下一批料。
-
切换:下一轮,用1号台加工,给0号台上新料。如此反复。
-
核心:计算(vec_add)和下一次的数据搬运是重叠的。理想情况,计算单元永远不“饿”,数据永远“在路上”。这是性能飙高的唯一秘诀。
性能分析:不流水,就等死
来点真实感数据。假设某型号芯片,HBM带宽1.5TB/s,AI Core的Vector算力约2 TFLOPS。做向量加,每个元素是2读+1写+1次浮点操作。
-
朴素串行版(搬->算->写, 干等):
-
耗时 ≈ 搬运时间(算力过剩)。
-
处理1M个float, 耗时约
(1M*4 * 3字节) / 1.5TB/s ≈ 8ms。 -
AI Core利用率 < 20%。
-
-
双缓冲流水线版:
-
理想下,搬运时间被计算完全隐藏。
-
耗时 ≈ 计算时间 =
(1M * 1 FLOP) / 2 TFLOPS ≈ 0.5ms。 -
实际提升8-12倍很常见。
-
下图是两种模式下,AI Core内部资源的时间线,一目了然:

图注:流水线模式下,搬运(深蓝)、计算(橙色)、写回(绿色)任务重叠,总耗时大幅缩短。
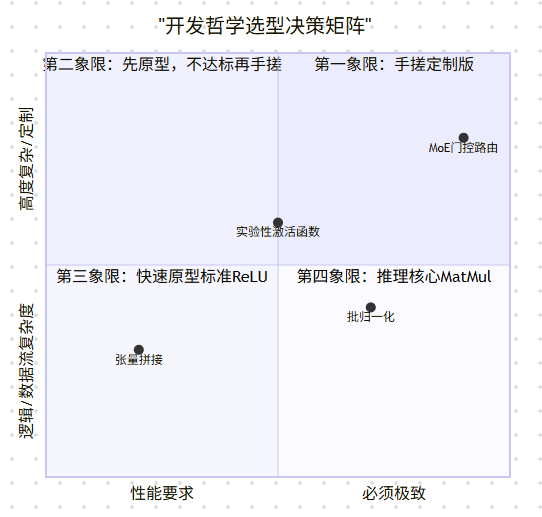
🧪 第三部分:实战 —— 两种开发哲学,两种人生路径
懂了底层,咱聊聊咋开工。我总结为两种哲学,对应两种职业生涯。
哲学一:快速原型 —— “相信编译器”流
核心:用高层抽象(类似KernelLaunch)描述“算什么”,把内存、流水线等脏活甩给编译器。目标是闪电验证。
何时用:算法研究员快速试新结构;非瓶颈算子;项目早期求快。
感觉像在写:带特殊标记的C++。
// 快速原型风格示意
class MyOp {
__aicore__ void Process() {
for (int i = 0; i < len; ++i) {
out[i] = in1[i] + in2[i]; // 编译器,你看着办
}
}
};优点:出活快,代码清爽。
缺点:性能有天花板,复杂逻辑抓瞎。
哲学二:工程化手搓 —— “我的硬件我做主”流
核心:就是第二部分展示的,手动控制一切。你是物流总监+车间主任。目标:极致性能和实现任何奇葩融合。
何时用:核心算子(MatMul, Attention);高度融合定制算子(LayerNorm+Silu+Dropout);Profiling出的瓶颈点。
这就是正儿八经的Ascend C核函数开发。
怎么选?看下面这个“决策矩阵”,这是我多年踩坑总结的:
完整示例:一个真实可测的TopK内核框架
我们搞个比向量加更实战的:核内TopK。假设在[num_tokens, num_experts]的矩阵中,每个token找top-2的专家。这是MoE门控的简化核心。
// 文件:simple_topk_kernel.h
// 语言:Ascend C
// 版本:CANN 7.0+
// 描述:每个token在本地找top-2的值和索引
typedef struct {
int32_t numTokens;
int32_t numExperts;
int32_t topK; // 假设为2
int32_t tileTokens; // 每个核处理多少个token
} TopKTiling;
extern "C" __global__ __aicore__ void simple_topk_kernel(
__gm__ const float* scores, // 输入 [numTokens, numExperts]
__gm__ int32_t* indices, // 输出索引 [numTokens, topK]
__gm__ float* values, // 输出值 [numTokens, topK]
__gm__ const TopKTiling* tiling
) {
int32_t blockId = get_block_idx();
int32_t startToken = blockId * tiling->tileTokens;
int32_t endToken = min(startToken + tiling->tileTokens, tiling->numTokens);
int32_t tokensThisCore = endToken - startToken;
if (tokensThisCore <= 0) return;
// UB分配:为当前核处理的多个token分配空间
// 每个token需要:一行scores, 和topK的临时结果
int32_t scoresPerToken = tiling->numExperts;
__ub__ float* scoreUb = (__ub__ float*)__ubuf_alloc(tokensThisCore * scoresPerToken * sizeof(float));
__ub__ float* topValUb = (__ub__ float*)__ubuf_alloc(tokensThisCore * tiling->topK * sizeof(float));
__ub__ int32_t* topIdxUb = (__ub__ int32_t*)__ubuf_alloc(tokensThisCore * tiling->topK * sizeof(int32_t));
// 1. 搬运:把本核负责的所有token的分数搬进来
hacl::data_copy(scoreUb, scores + startToken * scoresPerToken,
tokensThisCore * scoresPerToken * sizeof(float));
// 2. 为每个token在UB内找TopK(简化迭代法,实际可用向量化比较)
for (int t = 0; t < tokensThisCore; ++t) {
float* tokenScores = scoreUb + t * scoresPerToken;
float* myTopVal = topValUb + t * tiling->topK;
int32_t* myTopIdx = topIdxUb + t * tiling->topK;
// 初始化:取前K个
for (int k = 0; k < tiling->topK; ++k) {
myTopVal[k] = tokenScores[k];
myTopIdx[k] = k;
}
// 排序一下前K个(简单冒泡)
for (int i = 0; i < tiling->topK - 1; ++i) {
for (int j = 0; j < tiling->topK - 1 - i; ++j) {
if (myTopVal[j] < myTopVal[j+1]) {
float tmpV = myTopVal[j]; myTopVal[j] = myTopVal[j+1]; myTopVal[j+1] = tmpV;
int32_t tmpI = myTopIdx[j]; myTopIdx[j] = myTopIdx[j+1]; myTopIdx[j+1] = tmpI;
}
}
}
// 遍历剩余专家,更新TopK
for (int e = tiling->topK; e < scoresPerToken; ++e) {
float s = tokenScores[e];
if (s > myTopVal[tiling->topK-1]) {
myTopVal[tiling->topK-1] = s;
myTopIdx[tiling->topK-1] = e;
// 重新排序(简单冒泡一次)
for (int k = tiling->topK - 1; k > 0; --k) {
if (myTopVal[k] > myTopVal[k-1]) {
float tmpV = myTopVal[k]; myTopVal[k] = myTopVal[k-1]; myTopVal[k-1] = tmpV;
int32_t tmpI = myTopIdx[k]; myTopIdx[k] = myTopIdx[k-1]; myTopIdx[k-1] = tmpI;
}
}
}
}
}
// 3. 将结果写回全局内存
hacl::data_copy(values + startToken * tiling->topK, topValUb,
tokensThisCore * tiling->topK * sizeof(float));
hacl::data_copy(indices + startToken * tiling->topK, topIdxUb,
tokensThisCore * tiling->topK * sizeof(int32_t));
}Host侧调用框架(C++):
// main.cpp (简化)
#include "acl/acl.h"
// 包含编译好的核函数头文件
int main() {
aclInit(nullptr);
aclrtSetDevice(0);
aclrtStream stream;
aclrtCreateStream(&stream);
// 参数
int numTokens = 1024, numExperts = 64, topK = 2;
int tileTokens = 16; // 每个核处理16个token
int blockNum = (numTokens + tileTokens - 1) / tileTokens;
// 分配设备内存 scores_dev, indices_dev, values_dev...
// 准备Tiling结构体并拷贝到设备 tiling_dev...
// 调用核函数(需通过ACL接口加载核函数二进制)
// rtKernelLaunch(simple_topk_kernel, blockNum,
// scores_dev, indices_dev, values_dev, tiling_dev, ...);
aclrtSynchronizeStream(stream);
// 检查结果...
aclrtDestroyStream(stream);
aclrtResetDevice(0);
aclFinalize();
return 0;
}分步骤指南:从入门到“能跑”
-
环境:装对CANN版本,配好
aclc编译器路径。这步就能卡死一半新手。 -
Hello Vector:别上来就整大的。用快速原型或极简核函数,实现
y = x + 1,确保流程打通。这步价值千金。 -
加流水线:在
y = x + 1里加入双缓冲。用msprof看看时间线变化,感受重叠的魅力。 -
搞个真算子:比如
LayerNorm。先画图:需要算均值、方差,再做归一化。想想中间结果放哪,怎么复用。 -
性能调优:
msprof是你的眼。看Cube/Vector利用率谁低,看带宽用了多少。对症下药。 -
集成上线:封装成PyTorch的
torch_npu自定义算子。这是算子“转正”的临门一脚。
常见问题:老司机的避坑手册
-
Q1:编译失败,报错天书。
-
A1:首先查
__gm__/__ub__用对没,指针类型匹配不。然后,死算UB用量:sizeof(类型)*元素数,确保所有UB变量总和不超限(如256KB)。tileLen设大了是主因。
-
-
Q2:结果时对时错,有的位置是零。
-
A2:边界!边界!边界! 当
totalLength不是tileLen整数倍时,最后一个块的处理必须用min(tileLen, remaining)。在核函数开头用printf打出blockId, start, end,一眼看穿。
-
-
Q3:双缓冲上了,性能毛都没提升。
-
A3:查同步!
pipe_barrier和wait_all的stageId必须配对。画个数据依赖图,确保“计算等数据、写回等计算、下次搬运等计算开始”的逻辑正确。另外,tileLen太小的话,流水线启动开销占比大,体现不出优势。
-
-
Q4:
msprof里Cube利用率为0,我废了?-
A4:正常。Cube只做特定矩阵乘。你的算子要是Element-wise或Reduce,就跟Cube无关。但如果是MatMul却用不上Cube,那得查:数据排布对吗?Tiling能让计算密集吗?是不是误用了Vector指令?
-
🏭 第四部分:高级实战 —— 大模型时代的“铁人三项”
企业案例:MoE模型的门控路由优化实战
我们团队之前优化一个MoE模型,原版用框架原生算子(Softmax->TopK->Scatter...)做门控,Profiling一看,这串操作占了快8%的时间。
手搓方案:
-
拒绝快速原型:这是热点,必须压榨。
-
极简化融合设计:一个核函数,输入
[B*S, E]的权重,输出每个token的top-2专家索引和权重。-
核内:
-
一次搬一个token的E个权重到UB。
-
在UB里用基于向量比较的排序网络找Top-2(数据量小,排序网络无分支,比
std::sort快)。 -
对top-2做局部Softmax。
-
写回。
-
-
优化:
-
每个核处理多个token,分摊启动开销。
-
用向量指令并行比较,加速TopK。
-
-
-
效果:替换后,该部分耗时从~8%降到0.5%以下,端到端训练迭代提速15%。核心就一条:省掉了中间结果的反复读写。
性能技巧:压箱底的“黑科技”
-
Tiling的数学暴力美学:对于MatMul,设分块
(m, n, k)。在约束m*n + m*k + n*k < UB_Size下,求最大化计算/访存比 = (2*m*n*k) / (m*k + n*k)。写个脚本枚举一下,找到的(m,n,k)比凭经验猜的强不少。 -
向量化要对齐:
vec_add等要求地址对齐(常为128字节)。确保从GM加载到UB的起始地址是对齐的。不对齐性能可能掉好几倍。用__ubuf_alloc通常是对齐的,但要以它作为向量的起点。 -
减少核内“等等等”:
__sync_all()有开销。重新组织计算,让同步次数最少。比如,一股脑把阶段所需数据全搬进UB再算,就比搬一点、算一点、同步一次要好。 -
让AI CPU和AI Core各司其职:复杂控制流、动态逻辑放AI CPU。AI Core只负责纯数据并行计算。用
kernel_launch在AI CPU上调度。
故障排查:当你的算子“摆烂”时
-
功能不对:
-
神器:核函数内
printf。打印输入参数、中间值、循环变量。 -
方法:用最小输入(如
totalLength=7)测试,人脑模拟每个核的执行。缩小范围是王道。
-
-
性能不行:
-
神器:
msprof。看不懂报告就别搞优化了。 -
看啥:
-
时间线:DMA、Cube、Vector的活动是否重叠?有没有大段空白?
-
利用率:谁低?如果是Memory Bound(带宽用满),优化数据搬运和复用;如果是Compute Bound,优化计算密度。
-
带宽:HBM读写带宽离峰值差多远?差得远说明搬运策略没喂饱总线。
-
-
-
系统级问题(如多卡):
-
工具:
hccl测试工具 +msprof系统视图。 -
思路:先单卡单算子跑通,再扩多卡。注意数据在卡间的划分与同步。
-
🔮 第五部分:未来 —— 我们还要“手搓”多久?
说实话,今天,手搓Ascend C核函数仍是获取NPU极致性能的必要之恶。但我判断,这不会永远持续。
趋势一:编译器“成精”。aclc会越来越聪明。未来,你可能只需用高层抽象描述意图,编译器自动搞定Tiling、流水线,生成接近手搓的代码。但这需要时间,尤其对奇葩融合算子。
趋势二:DSL和自动生成。会出现更高级的AI DSL或模板库。用几行配置描述一个“类Attention”模式,生成器就吐出优化好的Ascend C代码。这可能成为主流。
趋势三:软硬件协同再深化。下代AI芯片硬件可能更“可编程”,降低手搓门槛。比如更智能的DMA、更通用的片上存储。
给你的建议:
-
新手:必须懂手搓原理,就像学车先学手动挡。但日常可从快速原型开始。
-
老鸟:继续深耕手搓,这是现在的硬实力。同时,盯紧编译器和DSL进展,准备将知识上移,去设计模式,而非永远写底层。
-
团队:建分层能力。让多数人用高级抽象快速开发,组一支“特种部队”,专攻手搓核心瓶颈。
📚 资源
-
CANN官方文档- 最新技术文档和API参考
-
Ascend C编程指南- 完整编程规范和实践指南
-
ops-transformer开源仓库- 生产级算子实现参考
-
昇腾社区最佳实践- 实战经验分享和问题解答
-
性能优化白皮书- 深度性能优化技术解析
✨ 总结与展望
通过本文的深度技术解析,我们全面探讨了Ascend C与CANN架构在大模型时代的核心价值。从基础架构到企业级实践,从算法原理到性能优化,我们构建了完整的技术体系。
关键收获:
-
🎯 硬件软件协同是极致性能的基石
-
⚡ 向量化与并行化是性能优化的核心手段
-
🔧 系统化调优需要综合考虑计算、内存、通信多个维度
-
🚀 自动化工具链是提升开发效率的关键
未来挑战与机遇:
随着AI模型规模的持续增长,算子开发面临着更大的性能、能效、复杂度挑战。Ascend C作为一种领域特定语言,在专业化与通用性之间找到了良好的平衡点。我相信,通过持续的技术创新和生态建设,Ascend C将在AI基础设施领域发挥越来越重要的作用。
讨论话题:在您的实际业务场景中,遇到的最具挑战性的算子优化问题是什么?您是如何解决的?欢迎在评论区分享您的实战经验和技术见解!
🚀 官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 16
16 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)