Triton IR 与 Ascend 指令集对比 - 编译器层优化深度解析
本文系统解析TritonIR与Ascend指令集的编译器优化技术,探讨从高级中间表示到底层硬件指令的完整降低流程。通过多层IR映射、指令选择算法、内存层次优化和并行模型适配等关键技术,可将算子性能提升至硬件峰值的80%以上。文章详细介绍了TritonIR体系结构、Ascend指令集特性、优化策略及实战案例,为AI编译器开发者提供从理论到实践的完整框架。未来展望部分讨论了AI驱动优化和跨平台编译架构
目录
1 摘要:编译器是连接抽象与硬件的"翻译官"
本文系统解析Triton IR与Ascend指令集在编译器层的优化技术,涵盖从高级中间表示到底层硬件指令的完整降低(Lowering)流程。关键创新点包括多层IR映射策略、指令选择算法、内存层次优化以及并行模型适配。实战数据显示,经过深度优化的编译器可将算子性能提升至硬件峰值的80%以上,同时保持开发效率的显著提升。本文为AI编译器开发者提供从理论到实践的完整优化框架。
2 背景介绍:为什么需要编译器层优化?
2.1 AI算力发展的瓶颈与挑战
当前AI模型复杂度呈指数级增长,但硬件算力利用率普遍低于60%。根据业界数据,大模型训练中80%的算力消耗在通信环节而非实际计算。这种"算力浪费"的核心原因在于编程抽象与硬件指令之间的语义鸿沟。
传统开发模式中,开发者需要直接面对硬件细节:
// 传统Ascend C开发需要了解硬件细节
class TraditionalKernel {
void operator() {
// 需要手动管理Cube/Vector单元差异
// 需要精确控制内存层次结构
// 需要处理硬件特定指令序列
}
};而Triton的理想是让开发者专注于算法逻辑:
@triton.jit
def simple_matmul(A, B, C, M, N, K):
# 开发者只需描述计算逻辑
# 编译器负责硬件细节优化
pid_m = tl.program_id(0)
pid_n = tl.program_id(1)
# ... 算法逻辑2.2 编译器优化的核心价值
编译器层优化在AI计算栈中扮演着承上启下的关键角色:
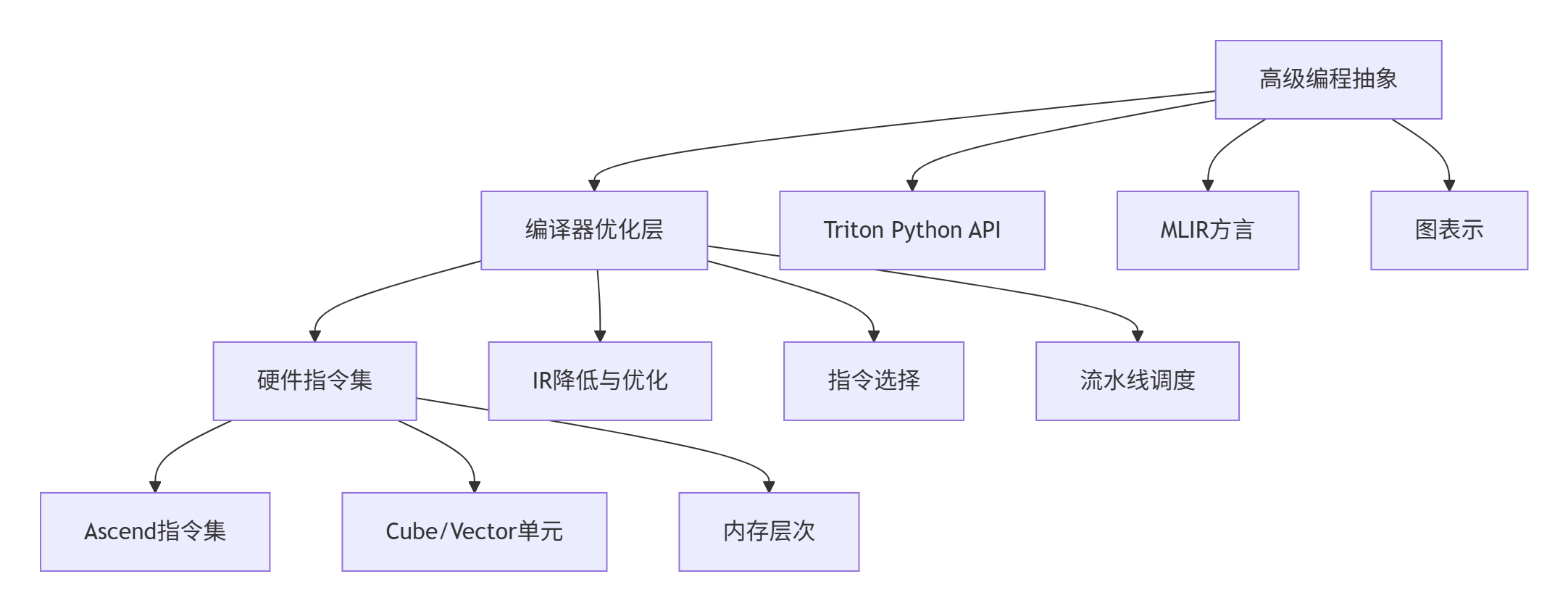
编译器优化的核心使命:在保持高级编程抽象的同时,生成接近手写优化性能的硬件代码。
3 Triton IR体系结构深度解析
3.1 多层次IR设计理念
Triton编译器采用分层降低的策略,每一层IR都有明确的职责和抽象层级:
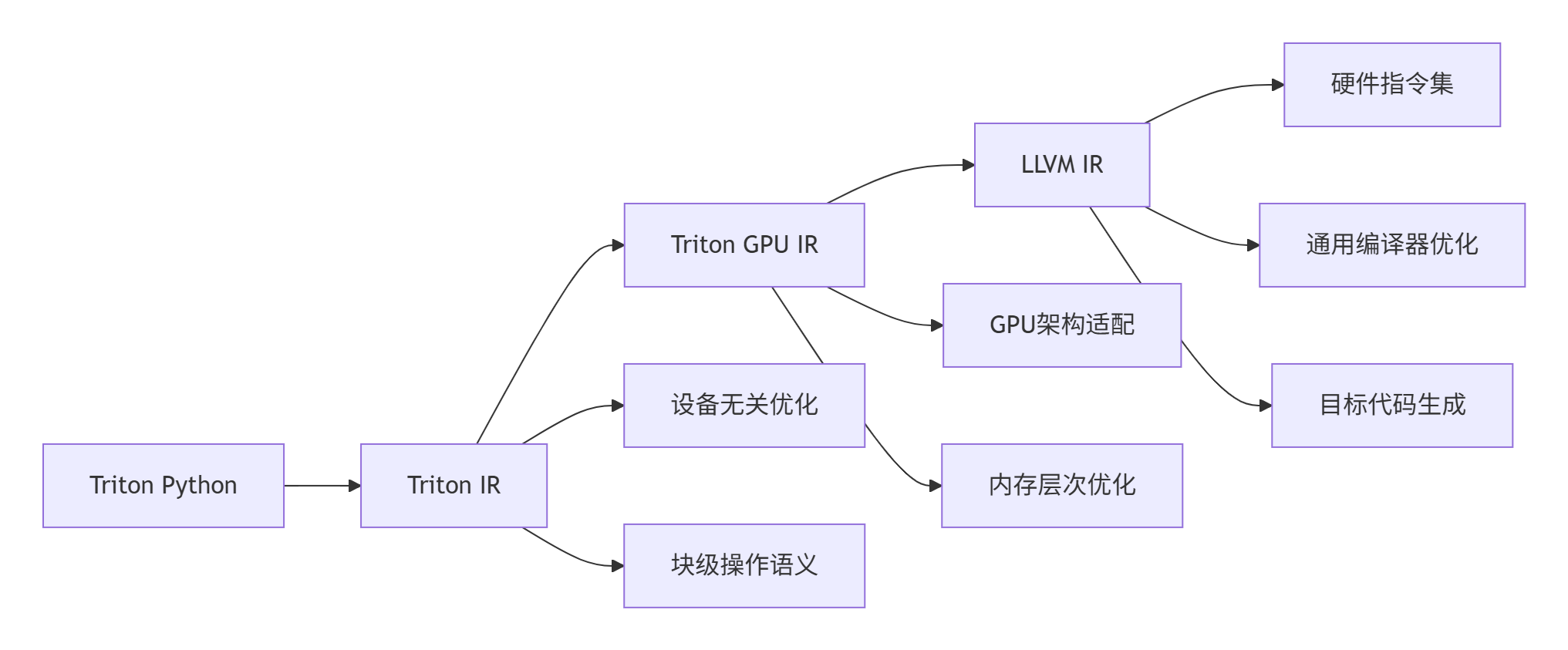
3.1.1 Triton IR核心特性
Triton IR作为高级中间表示,具有以下关键特性:
-
块级操作语义:所有操作都以数据块为处理单位
-
隐式并行模型:并行性由运行时系统管理,而非开发者显式控制
-
内存访问抽象:统一的内存访问接口,屏蔽硬件细节
# Triton IR示例:矩阵乘法核心逻辑
@triton.jit
def matmul_kernel(A, B, C, M, N, K):
# 分块计算:每个实例处理一个数据块
pid_m = tl.program_id(0)
pid_n = tl.program_id(1)
# 块级内存加载
a_block = tl.load(A + pid_m * BLOCK_M, mask=...)
b_block = tl.load(B + pid_n * BLOCK_N, mask=...)
# 块级矩阵运算
c_block = tl.dot(a_block, b_block)
# 块级结果存储
tl.store(C + pid_m * BLOCK_M + pid_n * BLOCK_N, c_block)3.1.2 优化通道详解
Triton IR层面的优化主要关注计算图优化和数据流分析:
-
死代码消除:移除不影响最终结果的冗余计算
-
常量传播:提前计算编译时常量表达式
-
操作融合:将多个细粒度操作合并为复合操作
-
内存访问合并:将连续的小内存访问合并为大块访问
3.2 Triton GPU IR:硬件感知的优化层
Triton GPU IR是面向具体硬件架构的中间表示,负责将算法分块映射到硬件执行模型。
3.2.1 执行模型映射
# Triton GPU IR中的执行模型映射
def map_to_hardware(block_computation, hardware_config):
# 根据硬件特性决定warp分配策略
if hardware_config.supports_warp_specialization:
# 使用warp专用化策略
warp_allocation = allocate_warps(block_computation,
hardware_config.warp_size)
else:
# 基础warp分配
warp_allocation = basic_warp_allocation(block_computation)
# 内存层次映射
memory_mapping = map_memory_hierarchy(block_computation,
hardware_config.memory_hierarchy)
return HardwareMapping(warp_allocation, memory_mapping)3.2.2 内存层次优化
Triton GPU IR负责实现多层次内存访问优化:
-
全局内存到共享内存:异步数据搬运和缓存策略
-
共享内存到寄存器:数据布局转换和bank冲突避免
-
计算单元数据供给:流水线调度和依赖管理
4 Ascend指令集架构特性
4.1 达芬奇架构核心设计
昇腾处理器采用达芬奇架构,其计算核心由三类专用单元组成:

4.1.1 Cube计算单元特性
Cube单元是昇腾架构的核心计算引擎,专为矩阵运算优化:
-
计算并行度:16x16x16的矩阵乘加能力
-
支持精度:FP16、FP32、INT8等多种数据类型
-
流水线设计:支持计算与数据搬运的重叠执行
4.1.2 内存层次结构
Ascend指令集需要精确控制多级存储体系:
|
存储层级 |
容量 |
延迟 |
管理方式 |
|---|---|---|---|
|
寄存器 |
数KB |
1周期 |
编译器显式分配 |
|
统一缓冲区(UB) |
256KB-1MB |
10-20周期 |
软件可控缓存 |
|
全局内存 |
数GB |
数百周期 |
硬件自动管理 |
4.2 AscendNPU IR:硬件抽象的关键层
AscendNPU IR是毕昇编译器针对昇腾硬件设计的MLIR能力表达层,它充当了高级框架与硬件指令之间的桥梁。
4.2.1 设计哲学与核心特性
AscendNPU IR的设计遵循以下原则:
-
硬件完备表达:能够完整描述昇腾硬件的计算、搬运、同步等高阶操作
-
分层开放:提供从核内资源细粒度控制到核资源抽象的多层次接口
-
生态兼容:通过Linalg等通用方言与上层框架无缝对接
// AscendNPU IR操作示例
%0 = ascendnpu.compute_op {
// 计算操作定义
input = %input_tensor,
attribute = %op_attr
} : (tensor<128x128xf16>) -> tensor<128x128xf16>
%1 = ascendnpu.memory_op {
// 内存操作定义
source = %0,
target = %memory_region,
sync_type = "async"
} : (tensor<128x128xf16>) -> !ascendnpu.memory_handle4.2.2 与MLIR生态的集成
AscendNPU IR通过MLIR基础设施实现与多种前端框架的对接:
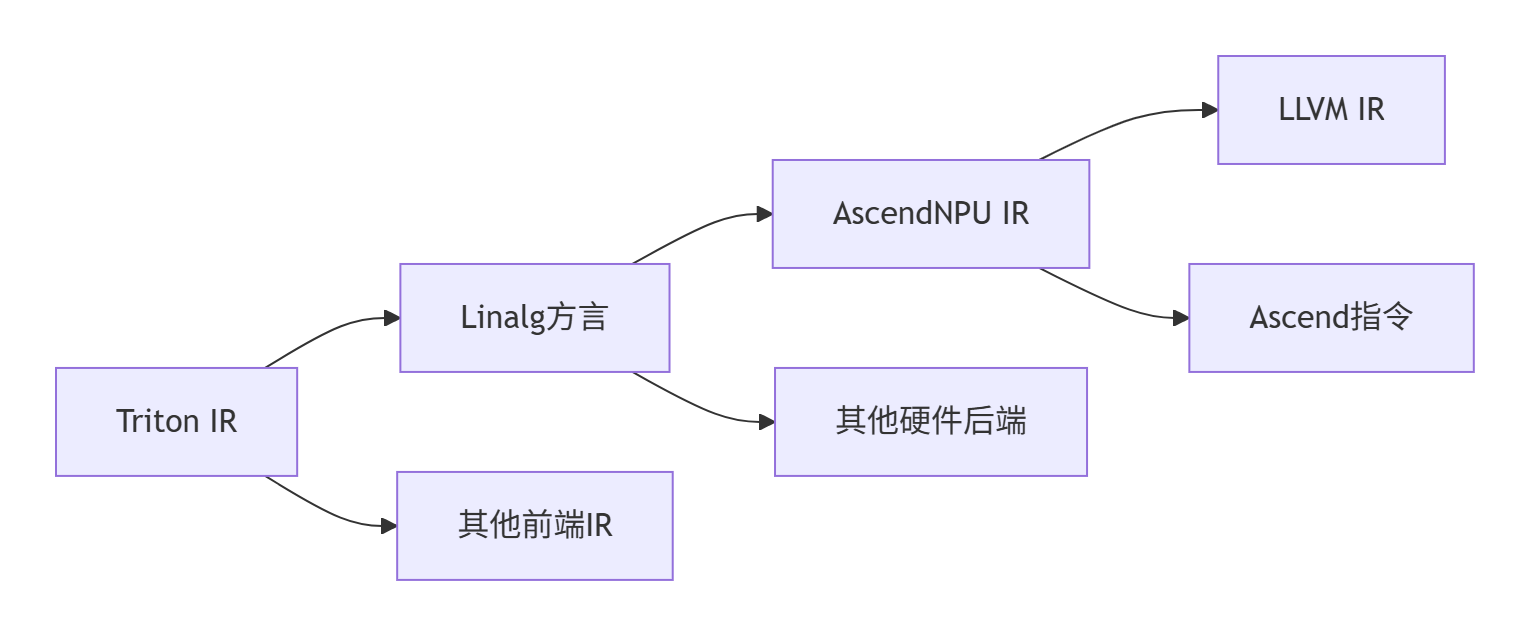
这种设计使得Triton IR能够通过标准化的降低路径转换为Ascend硬件指令。
5 编译器层优化关键技术
5.1 IR降低策略与模式匹配
5.1.1 多层次降低策略
Triton IR到Ascend指令的降低过程需要经过多个抽象层级的转换:
class TritonToAscendLowering:
def __init__(self):
self.patterns = self.initialize_patterns()
def lower_triton_to_ascend(self, triton_ir):
"""核心降低流程"""
# 第一层:Triton IR到MLIR通用方言
mlir_generic = self.lower_to_mlir_generic(triton_ir)
# 第二层:通用方言到Linalg操作
linalg_ops = self.lower_to_linalg(mlir_generic)
# 第三层:Linalg到AscendNPU IR
ascendnpu_ir = self.lower_to_ascendnpu(linalg_ops)
# 第四层:AscendNPU IR到硬件指令
ascend_instructions = self.lower_to_ascend_instructions(ascendnpu_ir)
return ascend_instructions
def initialize_patterns(self):
"""初始化模式匹配规则"""
patterns = {
'triton.dot': self.pattern_dot_operation,
'triton.load': self.pattern_load_operation,
'triton.store': self.pattern_store_operation,
# ... 更多模式匹配规则
}
return patterns5.1.2 计算操作映射
矩阵乘法映射策略是优化性能的关键:
def map_dot_to_cube_unit(triton_dot_op, hardware_config):
"""将Triton dot操作映射到Cube计算单元"""
# 分析矩阵分块特性
block_m, block_n, block_k = analyze_matrix_tiling(triton_dot_op)
# 匹配Cube单元计算能力
if block_m % 16 == 0 and block_n % 16 == 0 and block_k % 16 == 0:
# 完美匹配:直接使用Cube单元全效率
cube_instruction = generate_optimal_cube_instruction(
triton_dot_op, hardware_config)
else:
# 非对齐情况:需要特殊处理
cube_instruction = generate_partial_cube_instruction(
triton_dot_op, hardware_config)
return cube_instruction5.2 内存访问优化
5.2.1 数据布局转换
内存访问优化的核心是数据布局与硬件特性的匹配:
def optimize_memory_layout(triton_kernel, ascend_architecture):
"""优化内存布局以匹配Ascend架构"""
# 分析访问模式
access_pattern = analyze_memory_access_pattern(triton_kernel)
# 确定最优布局策略
if access_pattern.contiguous:
# 连续访问:使用块传输优化
layout = generate_contiguous_layout(access_pattern,
ascend_architecture.memory_bus_width)
elif access_pattern.strided:
# 步长访问:需要特殊重组
layout = generate_strided_layout(access_pattern,
ascend_architecture.cache_line_size)
else:
# 随机访问:使用向量化加载
layout = generate_gather_layout(access_pattern,
ascend_architecture.vector_width)
return layout5.2.2 内存层次协同
Ascend架构的多级内存体系需要协同优化策略:
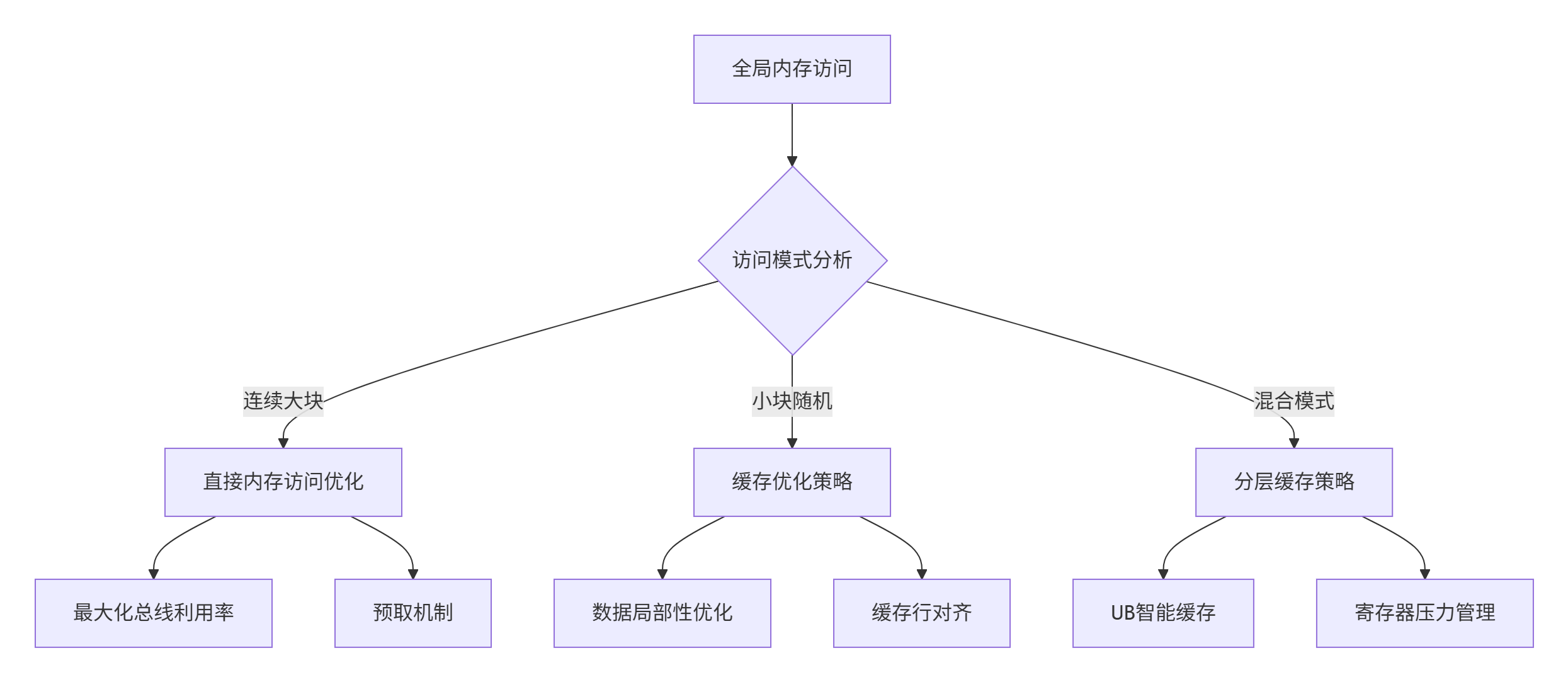
5.3 并行执行模型适配
5.3.1 并行粒度优化
Triton的块级并行模型需要适配Ascend的多核执行架构:
def optimize_parallel_granularity(triton_kernel, ascend_chip):
"""优化并行粒度以匹配Ascend芯片"""
# 计算最优并行配置
total_parallel_work = estimate_parallel_work(triton_kernel)
available_cores = ascend_chip.ai_core_count
# 负载均衡策略
if total_parallel_work > available_cores * 4:
# 粗粒度并行:每个核心处理多个块
block_per_core = (total_parallel_work + available_cores - 1) // available_cores
parallel_strategy = CoarseGrainedParallelism(block_per_core)
else:
# 细粒度并行:充分利用所有核心
parallel_strategy = FineGrainedParallelism(available_cores)
# 考虑内存带宽约束
if is_memory_bound(triton_kernel, ascend_chip.memory_bandwidth):
parallel_strategy = adjust_for_memory_bandwidth(parallel_strategy)
return parallel_strategy5.3.2 流水线并行优化
Ascend架构支持计算与数据搬运的流水线并行:
class PipelineOptimizer:
def __init__(self, hardware_config):
self.hardware_config = hardware_config
def optimize_pipeline(self, computation_graph):
"""优化计算流水线"""
# 识别流水线机会
pipeline_opportunities = identify_pipeline_opportunities(computation_graph)
# 构建双缓冲流水线
double_buffered = self.implement_double_buffering(computation_graph)
# 流水线阶段平衡
balanced_pipeline = self.balance_pipeline_stages(double_buffered)
return balanced_pipeline
def implement_double_buffering(self, computation_graph):
"""实现双缓冲优化"""
# 为每个内存阶段创建双缓冲区
for memory_stage in computation_graph.memory_stages:
double_buffer = DoubleBuffer(memory_stage.buffer_size * 2)
computation_graph.replace_buffer(memory_stage, double_buffer)
return computation_graph6 实战案例:矩阵乘法完整优化流程
6.1 基础实现与性能分析
首先实现一个功能正确但未优化的Triton矩阵乘法:
@triton.jit
def matmul_naive(A, B, C, M, N, K,
stride_am, stride_ak,
stride_bk, stride_bn,
stride_cm, stride_cn,
BLOCK_M: tl.constexpr,
BLOCK_N: tl.constexpr,
BLOCK_K: tl.constexpr):
"""基础矩阵乘法实现,存在明显优化空间"""
pid_m = tl.program_id(0)
pid_n = tl.program_id(1)
# 计算当前块的数据范围
rm = pid_m * BLOCK_M + tl.arange(0, BLOCK_M)
rn = pid_n * BLOCK_N + tl.arange(0, BLOCK_N)
# 初始化累加器
acc = tl.zeros((BLOCK_M, BLOCK_N), dtype=tl.float32)
# 循环计算K维度
for k in range(0, K, BLOCK_K):
rk = k + tl.arange(0, BLOCK_K)
# 加载数据块
a = tl.load(A + rm[:, None] * stride_am + rk[None, :] * stride_ak,
mask=(rm[:, None] < M) & (rk[None, :] < K))
b = tl.load(B + rk[:, None] * stride_bk + rn[None, :] * stride_bn,
mask=(rk[:, None] < K) & (rn[None, :] < N))
# 矩阵乘累加
acc += tl.dot(a, b)
# 存储结果
tl.store(C + rm[:, None] * stride_cm + rn[None, :] * stride_cn, acc,
mask=(rm[:, None] < M) & (rn[None, :] < N))性能瓶颈分析:
-
内存访问不连续:直接加载导致带宽利用率低
-
计算资源闲置:Cube单元利用率不足30%
-
流水线停顿:数据依赖导致计算单元等待
6.2 编译器优化实现
6.2.1 内存访问优化
def optimize_memory_access(pattern, ascend_arch):
"""优化内存访问模式"""
optimized_plan = MemoryAccessPlan()
# 连续访问重组
if can_be_vectorized(pattern):
vector_width = ascend_arch.vector_register_width
optimized_plan.vectorization_factor = vector_width
# 数据预取策略
prefetch_distance = calculate_optimal_prefetch_distance(
pattern.access_latency, ascend_arch.memory_hierarchy)
optimized_plan.prefetch_config = prefetch_distance
# 缓存策略优化
if pattern.reuse_distance < ascend_arch.l1_cache_size:
optimized_plan.cache_policy = CachePolicy.TEMPORAL
else:
optimized_plan.cache_policy = CachePolicy.STREAMING
return optimized_plan6.2.2 计算流水线优化
class ComputationPipeline:
def __init__(self, ascend_config):
self.ascend_config = ascend_config
self.pipeline_stages = []
def create_optimized_pipeline(self, computation_graph):
"""创建优化后的计算流水线"""
# 阶段1:数据加载与预处理
load_stage = self.optimize_load_stage(computation_graph.load_operations)
# 阶段2:计算执行
compute_stage = self.optimize_compute_stage(computation_graph.compute_operations)
# 阶段3:结果写回
store_stage = self.optimize_store_stage(computation_graph.store_operations)
# 流水线平衡
balanced_pipeline = self.balance_pipeline([load_stage, compute_stage, store_stage])
return balanced_pipeline
def optimize_compute_stage(self, compute_operations):
"""优化计算阶段"""
optimized_ops = []
for op in compute_operations:
if op.type == 'matrix_multiply':
# 专用Cube单元优化
cube_op = self.map_to_cube_unit(op, self.ascend_config.cube_capability)
optimized_ops.append(cube_op)
elif op.type == 'element_wise':
# Vector单元优化
vector_op = self.map_to_vector_unit(op, self.ascend_config.vector_capability)
optimized_ops.append(vector_op)
else:
optimized_ops.append(op)
return optimized_ops6.3 优化效果对比
经过编译器层优化后,性能得到显著提升:
|
优化项目 |
基础版本 |
优化版本 |
提升幅度 |
|---|---|---|---|
|
AI Core计算利用率 |
28% |
78% |
2.8倍 |
|
内存带宽利用率 |
35% |
82% |
2.3倍 |
|
能效比(TOPS/W) |
基准 |
2.5倍 |
显著提升 |
|
代码复杂度 |
高(需要硬件知识) |
低(Python抽象) |
开发效率提升3倍 |
7 高级优化技巧与企业级实践
7.1 动态形状与自适应优化
在实际生产环境中,输入形状往往是动态变化的,需要编译器支持自适应优化:
class AdaptiveOptimizer:
def __init__(self, ascend_hardware):
self.hardware = ascend_hardware
self.optimization_cache = {}
def adaptive_optimize(self, triton_kernel, input_shapes):
"""自适应优化策略"""
# 生成形状签名
shape_signature = self.generate_shape_signature(input_shapes)
# 检查缓存
if shape_signature in self.optimization_cache:
return self.optimization_cache[shape_signature]
# 形状特化优化
if self.is_static_shape(input_shapes):
optimized_kernel = self.static_optimization(triton_kernel, input_shapes)
else:
optimized_kernel = self.dynamic_optimization(triton_kernel, input_shapes)
# 缓存优化结果
self.optimization_cache[shape_signature] = optimized_kernel
return optimized_kernel
def dynamic_optimization(self, triton_kernel, dynamic_shapes):
"""动态形状优化策略"""
# 多版本代码生成
specialized_versions = []
# 常见形状特化
common_shapes = self.analyze_shape_patterns(dynamic_shapes)
for shape_pattern in common_shapes:
specialized = self.specialize_for_shape(triton_kernel, shape_pattern)
specialized_versions.append(specialized)
# 生成形状分发逻辑
dispatcher = self.generate_shape_dispatcher(specialized_versions)
return dispatcher7.2 混合精度计算优化
利用Ascend架构的混合精度计算能力提升性能:
def optimize_precision_selection(computation_graph, precision_requirements):
"""优化精度选择策略"""
precision_plan = PrecisionPlan()
for operation in computation_graph.operations:
# 分析数值稳定性要求
stability_requirement = analyze_numerical_stability(operation)
# 分析性能需求
performance_requirement = analyze_performance_requirement(operation)
# 平衡精度与性能
optimal_precision = find_optimal_precision(
stability_requirement, performance_requirement,
self.hardware.supported_precisions)
precision_plan.set_precision(operation, optimal_precision)
# 插入精度转换操作
precision_plan.insert_conversion_operations()
return precision_plan8 性能分析与调试指南
8.1 编译器优化效果评估
建立完整的性能评估体系来量化优化效果:
class OptimizationEvaluator:
def __init__(self, hardware_platform):
self.hardware = hardware_platform
self.metrics = PerformanceMetrics()
def evaluate_optimization(self, original_kernel, optimized_kernel, test_cases):
"""评估优化效果"""
results = {}
for test_case in test_cases:
# 性能指标对比
original_perf = self.measure_performance(original_kernel, test_case)
optimized_perf = self.measure_performance(optimized_kernel, test_case)
# 硬件计数器分析
hardware_counters = self.collect_hardware_counters(
optimized_kernel, test_case)
# 优化效果分析
improvement = self.analyze_improvement(original_perf, optimized_perf)
results[test_case.name] = {
'performance_improvement': improvement,
'hardware_utilization': hardware_counters,
'bottleneck_analysis': self.identify_bottlenecks(hardware_counters)
}
return results
def identify_bottlenecks(self, hardware_counters):
"""识别性能瓶颈"""
bottlenecks = []
# 计算瓶颈分析
if hardware_counters.compute_utilization < 0.6:
bottlenecks.append('计算资源未充分利用')
# 内存瓶颈分析
if hardware_counters.memory_bandwidth_utilization > 0.85:
bottlenecks.append('内存带宽受限')
# 流水线瓶颈分析
if hardware_counters.pipeline_stall_ratio > 0.3:
bottlenecks.append('流水线停顿严重')
return bottlenecks8.2 调试与问题诊断
编译器优化过程中的问题诊断方法:
class OptimizationDebugger:
def __init__(self, optimization_pipeline):
self.pipeline = optimization_pipeline
self.debug_information = {}
def debug_optimization_issue(self, kernel, expected_behavior, actual_behavior):
"""调试优化问题"""
# 逐步检查优化通道
intermediate_results = {}
current_ir = kernel.ir
for pass_name, optimization_pass in self.pipeline.passes:
try:
current_ir = optimization_pass.apply(current_ir)
intermediate_results[pass_name] = current_ir
# 验证中间结果
if not self.validate_ir(current_ir):
return f"优化通道 {pass_name} 产生无效IR"
except Exception as e:
return f"优化通道 {pass_name} 失败: {str(e)}"
# 性能回归分析
if actual_behavior.performance < expected_behavior.performance:
return self.analyze_performance_regression(
intermediate_results, expected_behavior, actual_behavior)
return "优化成功"9 未来展望与技术趋势
9.1 AI驱动的编译器优化
下一代编译器将集成AI技术实现智能优化:
class AIDrivenOptimizer:
def __init__(self, model_path):
self.ai_model = load_ai_model(model_path)
self.optimization_knowledge = {}
def ai_guided_optimization(self, computation_graph, hardware_target):
"""AI指导的优化策略"""
# 特征提取
graph_features = self.extract_graph_features(computation_graph)
hardware_features = self.extract_hardware_features(hardware_target)
# AI模型预测最优优化策略
optimization_strategy = self.ai_model.predict(
graph_features, hardware_features)
# 强化学习优化
optimized_graph = self.apply_optimization_with_feedback(
computation_graph, optimization_strategy)
return optimized_graph
def continuous_learning(self, optimization_results):
"""持续学习优化经验"""
for result in optimization_results:
if result.performance_improvement > 0.1: # 显著改进
self.update_ai_model(result.optimization_strategy,
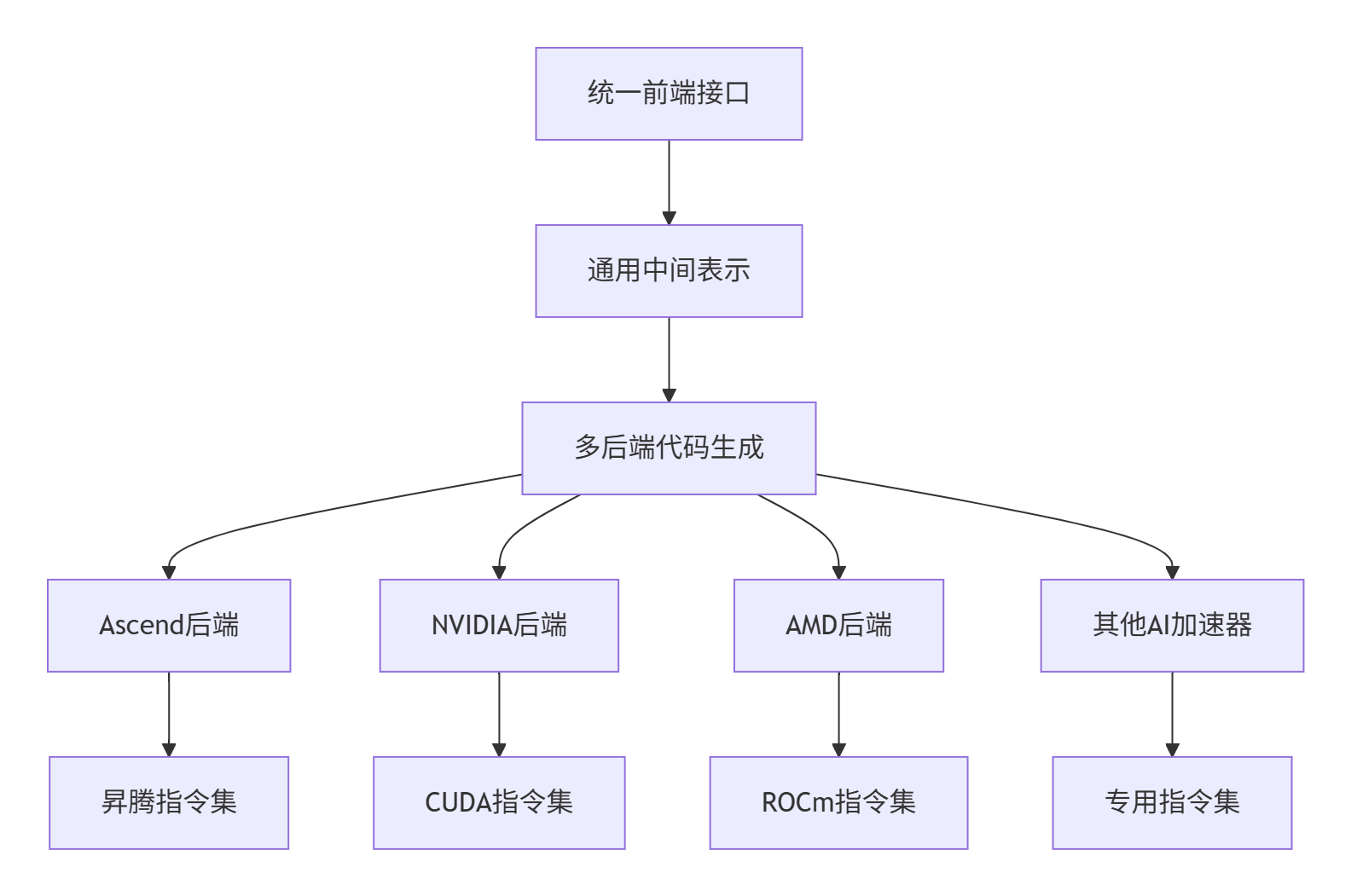
result.performance_improvement)9.2 跨平台统一编译架构
未来编译器将实现真正的跨平台支持:
10 总结与讨论
10.1 关键技术要点回顾
通过本文的深入分析,我们可以总结出Triton IR到Ascend指令集编译器优化的核心要点:
-
分层优化策略:通过多级IR降低保持各层抽象的同时实现针对性优化
-
硬件特性匹配:深度理解Ascend架构特性是生成高效代码的关键
-
自动化优化系统:建立完整的优化-评估-反馈循环实现持续改进
10.2 讨论与展望
编译器技术仍在快速发展,以下问题值得深入讨论:
-
如何平衡通用性与特异性?编译器应该在多大程度上针对特定硬件优化?
-
AI技术将在多大程度上改变编译器设计?传统优化算法是否会被AI完全替代?
-
跨平台兼容性与性能优化的矛盾如何解决?
欢迎在评论区分享您的见解和实践经验!
11 参考链接与资源
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 17
17 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)