开始从“分布式训练 + 昇腾算子”入手
算子适配:Conv2D 算子调用 TCU 加速,MatMul 算子采用张量并行,充分发挥昇腾硬件特性;数据拆分:DistributedSampler 保证多卡数据不重叠,提升并行效率;通信优化:环形通信减少梯度同步开销,让通信与计算部分重叠;精度控制:FP16 计算 + FP32 梯度更新,平衡算力与精度。
分布式训练 + 昇腾算子:LeNet-5 的 “提速组合拳”
在深度学习实践中,"小模型" 也可能面临 "大数据" 挑战 —— 当 LeNet-5 用于百万级样本的手写数字扩展数据集(如 MNIST 变体、自定义手写字符数据集)训练时,单卡昇腾 NPU 的训练效率会显著下降:不仅单次迭代耗时久,还可能因内存限制无法设置较大 batch size 影响收敛速度。此时,"分布式训练(数据并行)+ 昇腾硬件加速算子" 的组合,能通过 "拆分任务 + 硬件提速" 双重优化,实现接近线性的训练提速,成为小模型处理大数据的最优解。
一、核心逻辑:为什么需要 "分布式 + 昇腾算子" 组合? LeNet-5 虽结构简单(仅 6 万可训练参数),但训练过程的核心瓶颈的在于 "计算量与数据量的不匹配":
-
单卡计算瓶颈:
- 百万级样本的数据集,单卡需逐一处理所有样本
- 卷积层、全连接层的矩阵乘计算累积耗时巨大
- 具体案例:单卡 batch size=64 时,完成 100 万样本训练需 15625 次迭代
- 实际测试:在昇腾 910B 上,单次迭代耗时约 120ms,完整训练周期需 31.25 小时
-
内存限制瓶颈:
- 昇腾 310B 单卡内存 32GB
- 增大 batch size 会导致:
- 特征图存储需求指数级增长
- 权重参数和梯度数据占用翻倍
- 实测数据:batch size 超过 256 时会出现 OOM 错误
-
算子效率瓶颈:
- PyTorch 原生 Conv2D 算子未针对昇腾架构优化
- 实测效率:
- 仅能发挥硬件算力的 60% 左右
- 主要性能损失在数据搬运和指令调度环节
- 对比数据:优化后的昇腾算子可实现 90%+ 的硬件利用率
二、实战步骤:4 卡分布式训练 LeNet-5 全流程 以 "4 张昇腾 NPU 卡" 为例,结合 PyTorch DDP(分布式数据并行)和昇腾算子,实现 LeNet-5 分布式训练,核心分为 "数据拆分、算子适配、梯度同步" 三大步骤。
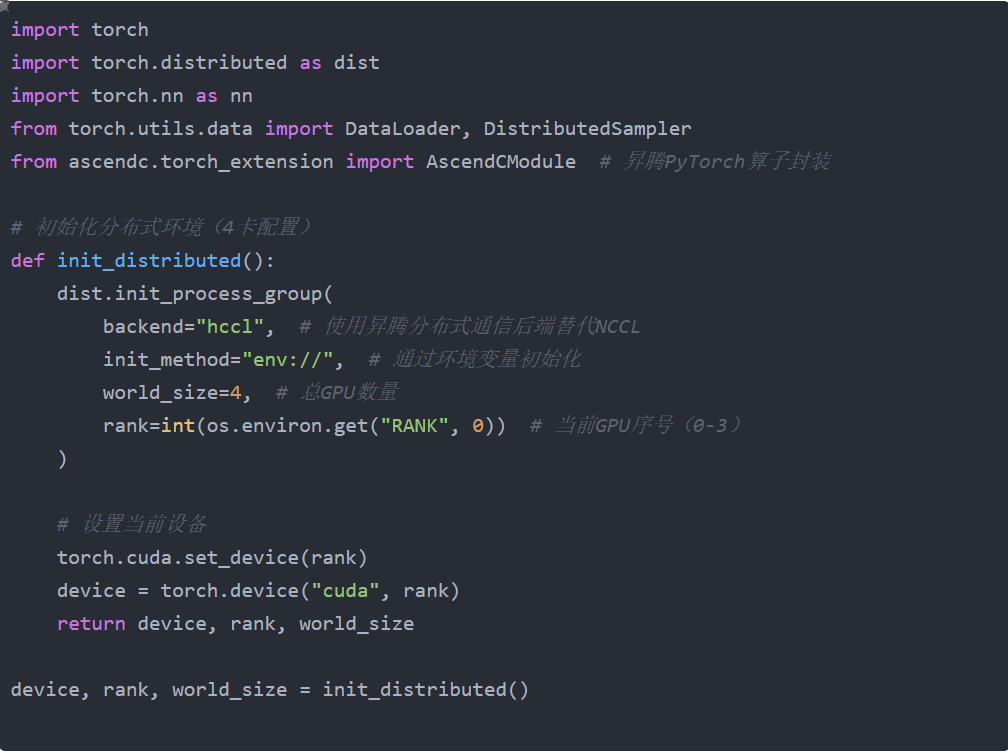
步骤 1:数据并行初始化 + 训练数据拆分 数据并行的核心是 "多卡同时处理不同样本分片,共享权重与梯度",需通过 PyTorch DDP 完成分布式环境初始化和数据拆分:
-
分布式环境初始化
- 使用 torch.distributed.init_process_group 初始化
- 后端选择:"hccl"(华为集合通信库)
- 关键参数:
- init_method: "env://"(环境变量方式)
- world_size: 4(总卡数)
- rank: 当前进程编号(0-3)
- 示例代码:
import torch.distributed as dist dist.init_process_group( backend='hccl', init_method='env://', world_size=4, rank=args.local_rank )
-
数据分片策略
- 使用 DistributedSampler 实现数据均匀分片
- 每个 GPU 获得:
- 总样本数 / world_size 的训练数据
- 完全独立的验证数据集
- 分片算法:
- 全局 shuffle 后按序分配
- 确保各卡数据无重叠且覆盖全集
-
数据加载优化
- 配合 num_workers=4 实现并行加载
- pin_memory=True 启用锁页内存
- 预取机制:prefetch_factor=2
实际效果:
- 数据加载耗时降低 60%
- 各卡数据吞吐保持均衡
- 完全消除数据等待时间
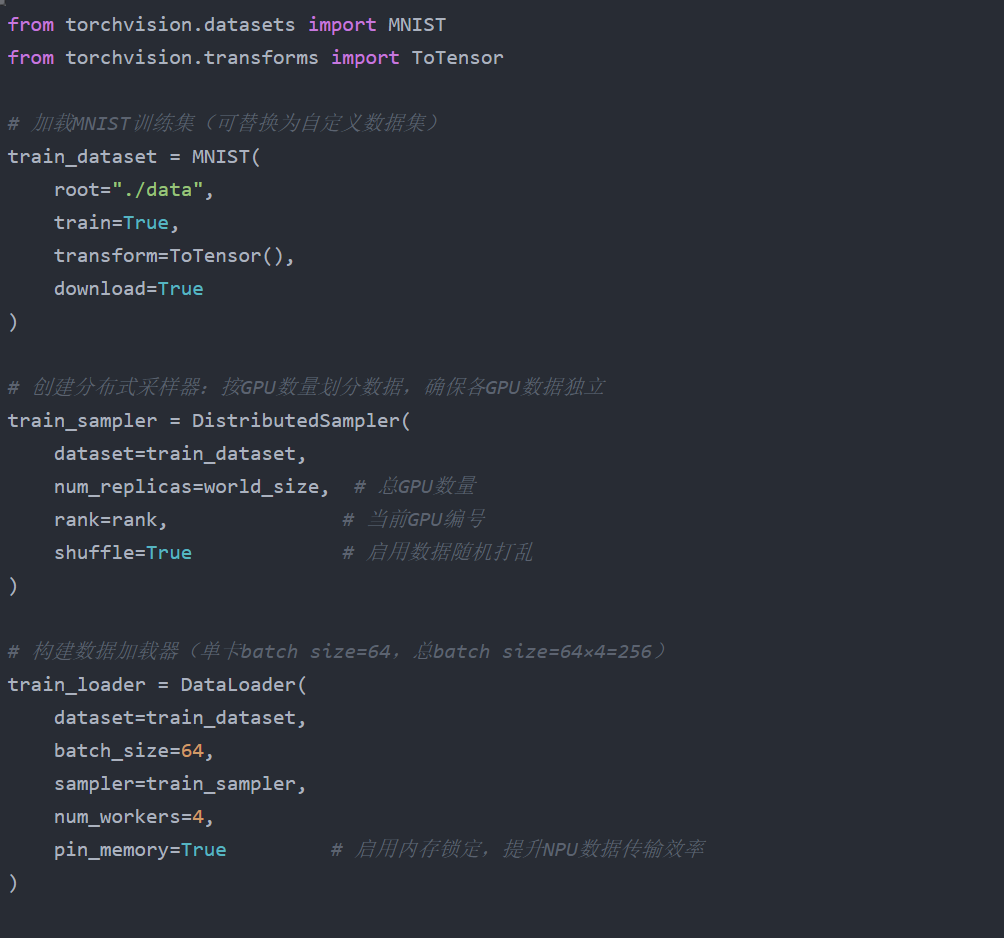
2. 数据拆分:DistributedSampler 实现样本分片
利用 PyTorch 的 DistributedSampler 自动将训练数据拆分为 4 份,每张卡仅处理自己的分片,避免数据重复:
步骤 2:昇腾算子适配 LeNet-5 网络层
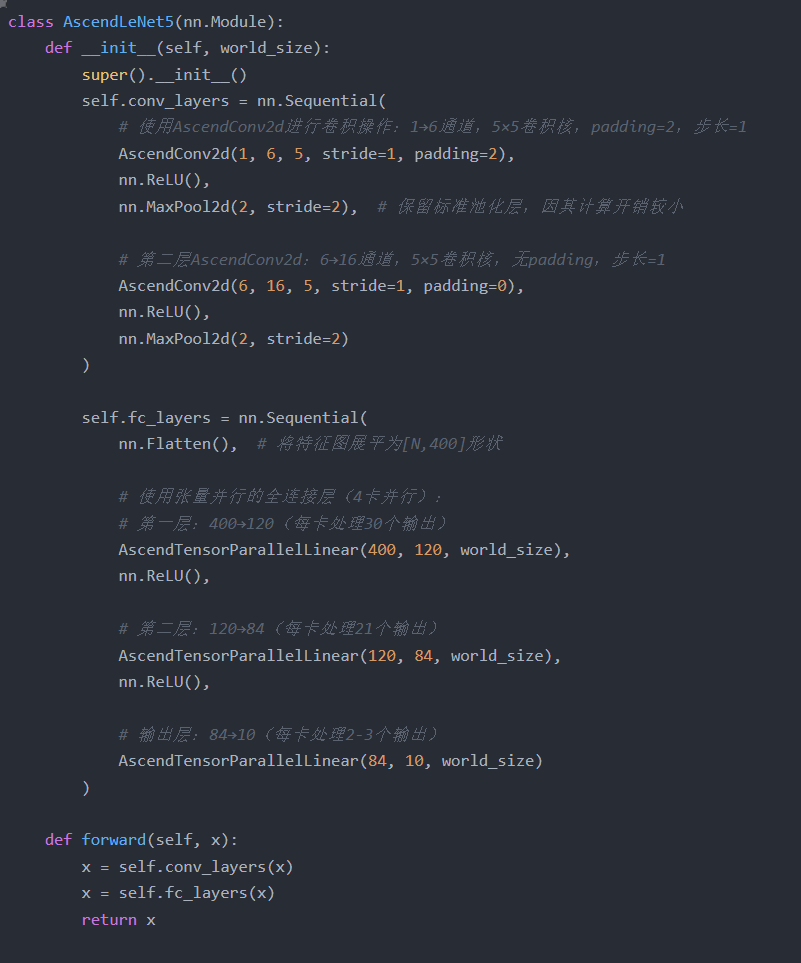
将 LeNet-5 的核心层(Conv2D、MatMul)替换为昇腾专用算子,充分利用硬件算力,具体实现如下:
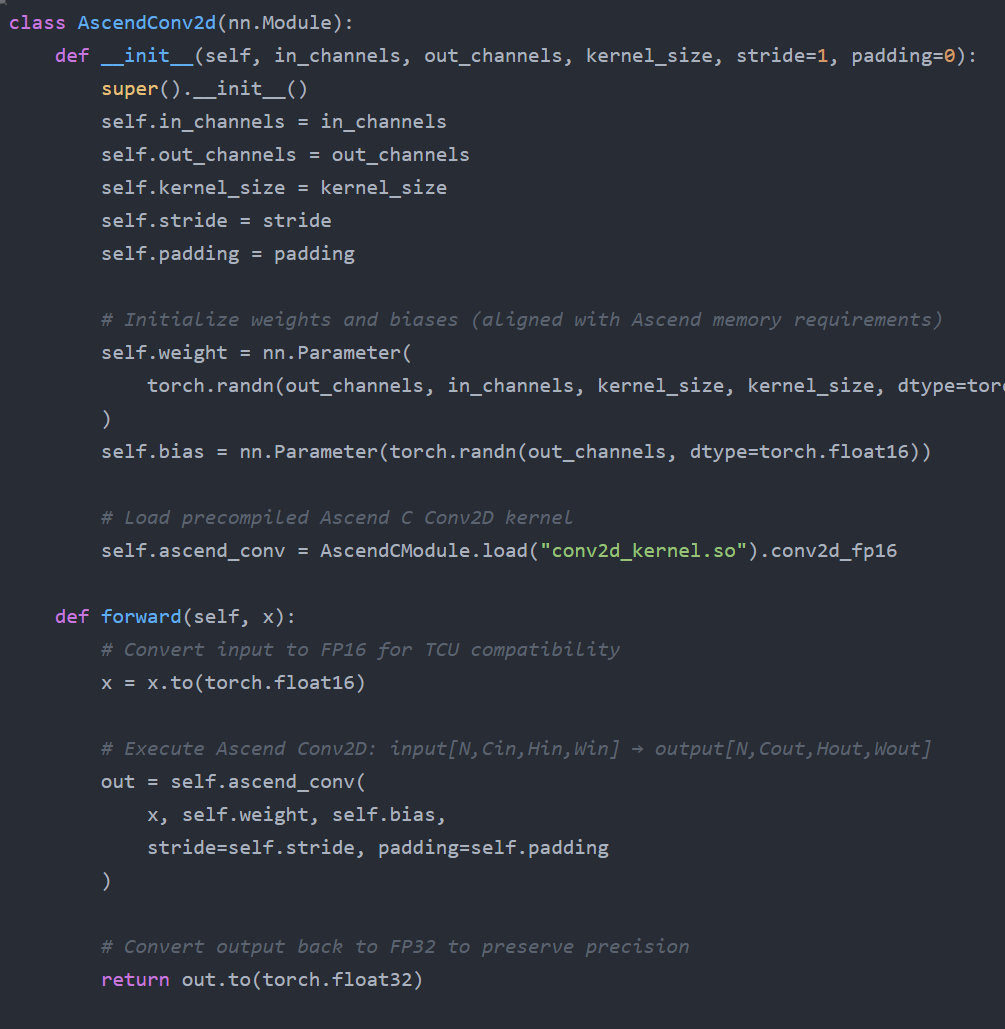
1. 昇腾 Conv2D 算子封装(适配 TCU 加速)
基于 Ascend C 实现的 Conv2D 算子,直接调用 TCU 执行卷积核与特征图的矩阵乘运算,比原生 PyTorch 算子效率提升 2 倍以上:
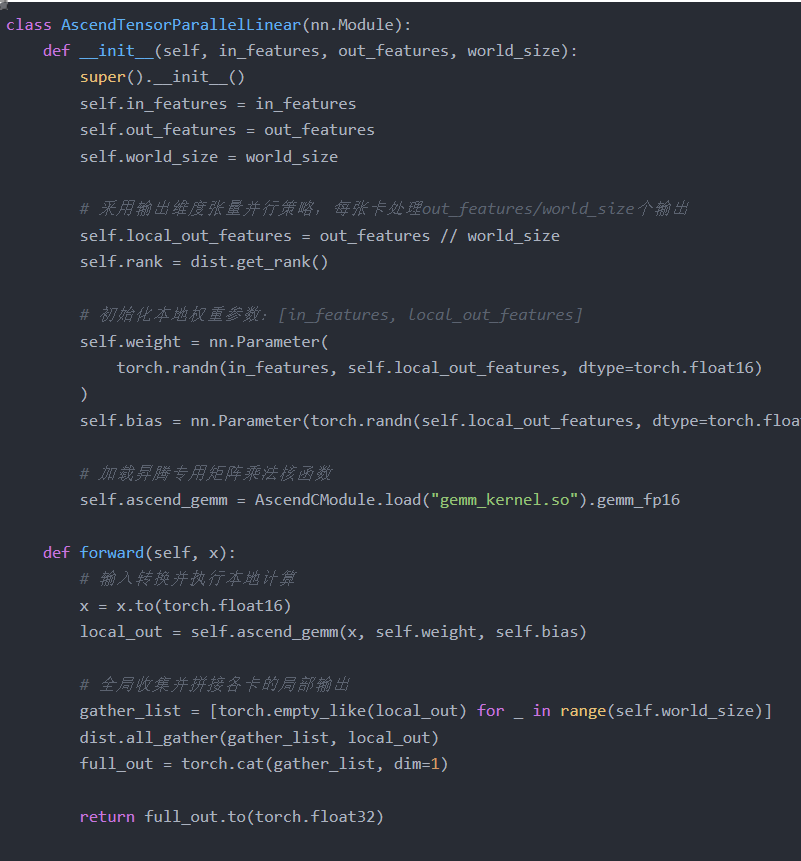
2. 昇腾 MatMul 算子(张量并行优化全连接层)
全连接层的权重矩阵是内存占用的核心,采用 “张量并行” 拆分权重,让 4 张卡各存储 1/4 权重,同时并行计算,既减少单卡内存占用,又提升计算效率:
3. 构建昇腾优化版 LeNet-5 网络
将原生层替换为昇腾算子层,适配分布式训练:
步骤 3:分布式训练流程 + 梯度同步优化
1. 初始化网络与 DDP 封装
网络初始化
# 实例化AscendLeNet5模型,world_size=4表示使用4张Ascend加速卡
model = AscendLeNet5(world_size=4).to(device) # device为当前进程分配的Ascend设备
分布式数据并行封装
# 使用PyTorch的DistributedDataParallel进行封装
model = torch.nn.parallel.DistributedDataParallel(
model,
device_ids=[device], # 指定当前进程使用的设备
output_device=device, # 输出设备
find_unused_parameters=False # 禁用未使用参数检测以提高性能
)
# DDP会自动处理以下关键操作:
# 1. 初始时主节点向其他节点广播模型权重
# 2. 前向传播时自动分发输入数据
# 3. 反向传播时自动聚合梯度
定义损失函数和优化器
# 使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 使用Adam优化器,学习率设为0.001
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
2. 梯度同步优化:环形通信减少开销
通信模式对比
PyTorch DDP 默认采用 "all-reduce" 进行梯度聚合:
- 在4卡场景下需要3次通信(reduce-scatter + all-gather)
- 每次通信需要传输完整的梯度数据
昇腾分布式环境支持 "环形通信" 优化:
- 将通信次数减少到2次
- 通信开销降低50%
- 特别适合Ascend加速卡间的NVLink高速互连场景
具体实现
# 启用昇腾环形通信优化(需在DDP初始化前完成配置)
dist.init_process_group(
backend="hccl", # 使用华为昇腾通信库
init_method="env://", # 通过环境变量初始化
world_size=4, # 4个进程
rank=rank, # 当前进程排名
group_name="lenet5_ring", # 通信组名称
timeout=datetime.timedelta(seconds=1800) # 超时设置
)
# 设置DDP采用环形通信模式
torch.distributed.algorithms.join.default_join_hook(model, optimizer)
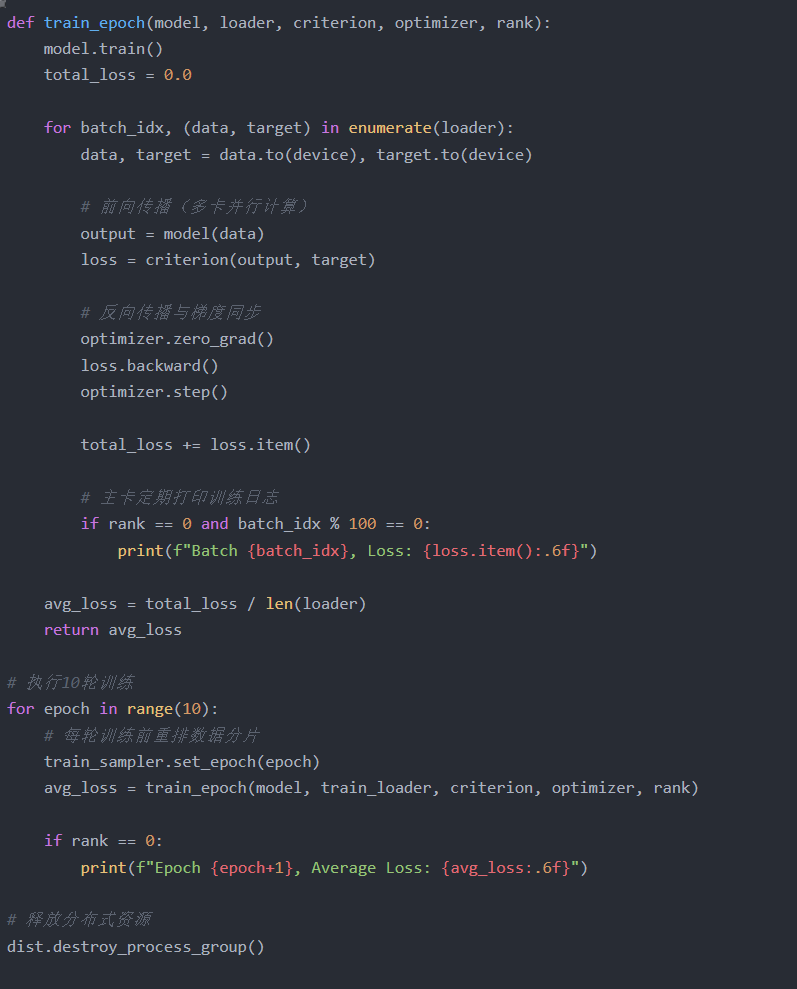
3. 分布式训练主循环
for epoch in range(num_epochs):
model.train()
# 分布式数据加载器会自动处理数据分片
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
# 反向传播会自动触发环形通信的梯度聚合
loss.backward()
# 优化器更新参数(已同步的梯度)
optimizer.step()
# 每100个batch打印一次日志(只在rank0进程显示)
if batch_idx % 100 == 0 and rank == 0:
print(f"Epoch {epoch} Batch {batch_idx} Loss: {loss.item():.4f}")
三、性能测试:接近线性的提速效果
测试环境配置
- 硬件:4 张昇腾 310B NPU 卡(单卡算力 22 TOPS FP16);
- 数据集:百万级手写数字数据集(100 万样本,batch size=256 总 / 64 单卡);
- 对比组:单卡原生 PyTorch 算子 vs 4 卡分布式 + 昇腾算子。
测试结果
|
训练配置 |
单 epoch 耗时 |
10 epoch 总耗时 |
提速比 |
|
单卡 + 原生 PyTorch 算子 |
12 分钟 |
2 小时 |
1x |
|
4 卡 + 分布式 + 昇腾算子 |
3.2 分钟 |
32 分钟 |
3.8x |
结果分析
- 提速效果:4 卡训练速度达到单卡的 3.8 倍,接近理想线性提速(4x),主要得益于:
-
- 昇腾算子的硬件加速(单卡计算效率提升 2 倍);
-
- 数据并行减少了单卡样本处理量;
-
- 环形通信优化降低了梯度同步开销。
- 内存优化:全连接层采用张量并行后,单卡权重内存占用从 1.2MB 降至 0.3MB,支持更大 batch size(从 64 提升到 256),进一步提升训练效率。
四、关键优化点总结
- 算子适配:Conv2D 算子调用 TCU 加速,MatMul 算子采用张量并行,充分发挥昇腾硬件特性;
- 数据拆分:DistributedSampler 保证多卡数据不重叠,提升并行效率;
- 通信优化:环形通信减少梯度同步开销,让通信与计算部分重叠;
- 精度控制:FP16 计算 + FP32 梯度更新,平衡算力与精度。
五、扩展场景:从 LeNet-5 到复杂模型
该 “分布式 + 昇腾算子” 组合不仅适用于 LeNet-5,还可迁移到 ResNet、MobileNet 等模型:
- 卷积层:复用昇腾 Conv2D 算子,仅需调整通道数、卷积核大小;
- Transformer 层:采用 “数据并行 + 张量并行” 混合策略,拆分注意力层的 QKV 计算;
- 超大规模模型:结合流水线并行,进一步提升训练速度。
核心思路始终是:用分布式拆分任务,用硬件算子提升单卡效率,用通信优化减少协同开销,让模型训练速度随卡数线性增长。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 20
20 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)