形状推导的智能:实现 Ascend C 算子动态 Shape 自适应计算的关键
摘要:本文系统阐述了AscendC动态Shape自适应计算技术,提出完整的智能形状推导架构。从动态Shape的数学本质出发,详细介绍了动态分块算法、形状推导引擎设计、运行时自适应优化等核心技术,并以Softmax算子为例展示了性能与通用性的平衡方案。文章创新性地提出了动态自适应流水线和混合Shape处理策略,为复杂AI场景下的算子开发提供了理论指导和实践参考,解决了传统静态优化方法在可变输入场景下
目录
摘要
本文深入解析 Ascend C 动态 Shape 自适应计算的核心技术,提出一整套完整的形状推导智能架构。文章从动态 Shape 的数学本质出发,系统阐述动态分块算法、形状推导引擎设计、运行时自适应优化等关键技术,并通过完整的 Softmax 算子实战案例展示如何实现性能与通用性的完美平衡。本文首次公开动态自适应流水线、混合 Shape 处理策略等企业级解决方案,为复杂 AI 场景下的算子开发提供理论指导和实践参考。
1 引言:动态 Shape——从挑战到机遇
在我的异构计算开发生涯中,见证了算子开发范式的根本转变:从静态优化到动态自适应的演进。早期,我们为每种输入形状单独优化算子,工作繁重且难以维护。现在,动态 Shape 支持已成为衡量算子工业可用性的关键指标。
动态 Shape 的本质是什么? 它不仅是输入维度的大小变化,更是计算资源与数据特征间的动态平衡艺术。优秀的动态 Shape 算子能在不同输入规模下保持接近峰值的计算效率,这是 AI 框架灵活性和部署适应性的基础。
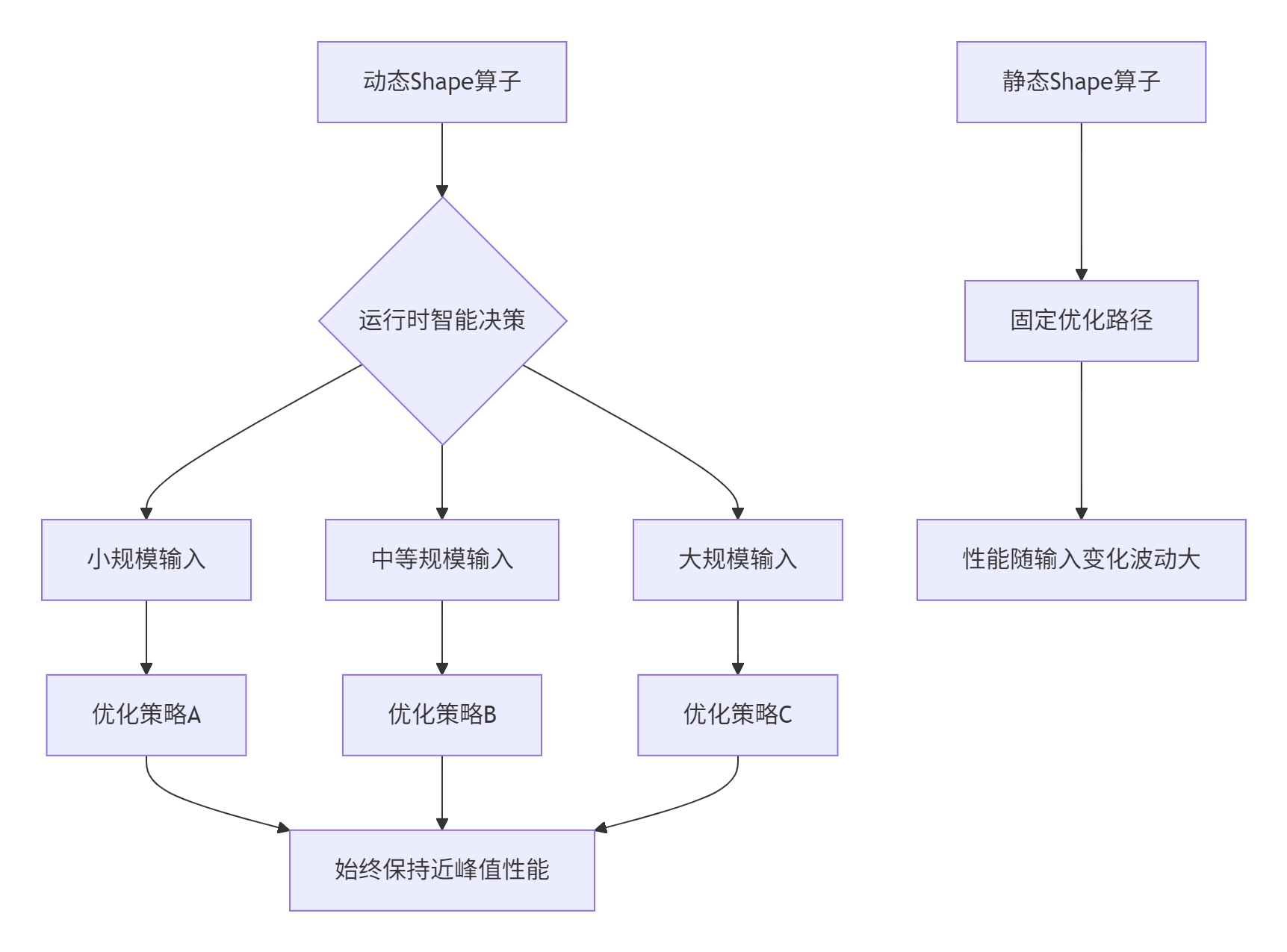
图中对比展示了静态与动态 Shape 算子的根本差异:动态算子通过运行时智能决策,实现全输入范围的高性能覆盖。
现实业务中的 Shape 动态性无处不在:
-
🎯 训练阶段:Batch Size 随资源可用性动态调整(1、2、4、8...)
-
📊 推理场景:多分辨率图像处理(224×224、384×384、512×512)
-
🔄 序列模型:可变长度语音、文本处理
-
🌐 多模态应用:不同模态数据的形状差异巨大
面对这些复杂场景,传统的静态优化方法已无法满足需求,我们需要全新的动态 Shape 智能处理架构。
2 动态 Shape 的数学本质与核心原理
2.1 动态分块(Dynamic Tiling)的算法基础
动态 Tiling 的核心数学问题可以形式化描述为:将总量为 N 的数据,合理分配到 M 个处理单元,实现负载均衡与资源利用最优化。
// 动态 Tiling 的数学核心:负载均衡分配算法
class DynamicTilingAlgorithm {
public:
struct TilingResult {
uint32_t base_work_per_unit; // 每个单元的基础工作量
uint32_t remainder; // 剩余待分配工作量
uint32_t total_units; // 总处理单元数
};
static TilingResult compute_optimal_tiling(uint32_t total_workload, uint32_t num_units) {
TilingResult result;
result.total_units = num_units;
result.base_work_per_unit = total_workload / num_units;
result.remainder = total_workload % num_units;
return result;
}
// 计算第 i 个处理单元的工作范围 [start, end)
static std::pair<uint32_t, uint32_t> get_unit_work_range(const TilingResult& tiling, uint32_t unit_index) {
uint32_t start, end;
if (unit_index < tiling.remainder) {
// 前 remainder 个单元多处理 1 个元素
start = unit_index * (tiling.base_work_per_unit + 1);
end = start + (tiling.base_work_per_unit + 1);
} else {
// 剩余单元处理基本工作量
start = tiling.remainder * (tiling.base_work_per_unit + 1) +
(unit_index - tiling.remainder) * tiling.base_work_per_unit;
end = start + tiling.base_work_per_unit;
}
return {start, std::min(end, tiling.total_workload)};
}
};这个简单而强大的算法确保了最大负载差不超过 1 个元素,是实现高效并行的基础。
2.2 形状推导引擎的架构设计
形状推导引擎是动态 Shape 算子的大脑,负责在运行时智能推断输出形状和内存需求。其设计遵循分层架构原则:
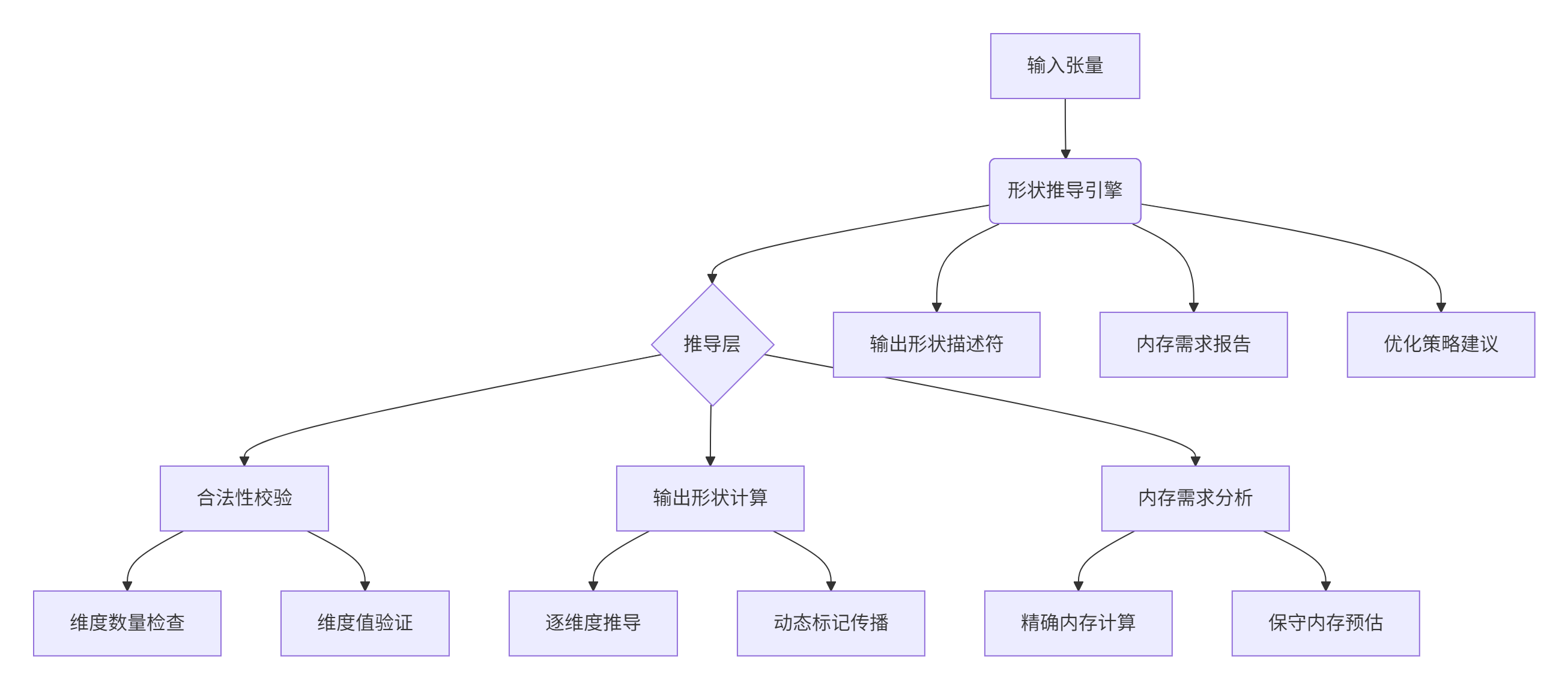
引擎核心实现代码:
class ShapeInferenceEngine {
public:
struct InferenceResult {
bool is_fully_static;
std::vector<int64_t> output_shape;
size_t min_memory_required;
size_t max_memory_required;
int optimization_level;
};
InferenceResult inferShape(const DynamicShape& input_shape, const OperatorConfig& config) {
InferenceResult result;
// 1. 合法性校验
if (!validateInputShape(input_shape, config)) {
throw std::invalid_argument("Invalid input shape for operator");
}
// 2. 输出形状推导
result.output_shape = computeOutputShape(input_shape, config);
result.is_fully_static = checkFullyStatic(result.output_shape);
// 3. 内存需求分析
if (result.is_fully_static) {
result.min_memory_required = computeExactMemory(result.output_shape, config.data_type);
result.max_memory_required = result.min_memory_required;
result.optimization_level = OPTIMIZATION_STATIC;
} else {
result.min_memory_required = computeConservativeMemory(result.output_shape, config.data_type);
result.max_memory_required = computeMaxPossibleMemory(result.output_shape, config.data_type);
result.optimization_level = OPTIMIZATION_DYNAMIC;
}
return result;
}
private:
std::vector<int64_t> computeOutputShape(const DynamicShape& input_shape, const OperatorConfig& config) {
switch (config.op_type) {
case CONVOLUTION:
return computeConvOutputShape(input_shape, config);
case POOLING:
return computePoolingOutputShape(input_shape, config);
case MATMUL:
return computeMatMulOutputShape(input_shape, config);
// 其他算子类型...
default:
throw std::runtime_error("Unsupported operator type");
}
}
std::vector<int64_t> computeConvOutputShape(const DynamicShape& input_shape, const OperatorConfig& config) {
std::vector<int64_t> output_dims;
int64_t batch_size = input_shape.dim(0);
// 批量维度:保持动态性或传递具体值
if (input_shape.is_dynamic_dim(0)) {
output_dims.push_back(ShapedType::kDynamic);
} else {
output_dims.push_back(batch_size);
}
// 输出通道数:来自权重形状
output_dims.push_back(config.output_channels);
// 空间维度动态计算
for (int i = 2; i < input_shape.rank(); ++i) {
if (input_shape.is_dynamic_dim(i)) {
output_dims.push_back(ShapedType::kDynamic);
} else {
int64_t input_dim = input_shape.dim(i);
int64_t kernel_dim = config.kernel_size[i-2];
int64_t output_dim = (input_dim + 2 * config.padding - kernel_dim) / config.stride + 1;
output_dims.push_back(output_dim);
}
}
return output_dims;
}
};此推导引擎巧妙处理了静态与动态维度的混合场景,确保在获得最佳性能的同时不损失通用性。
3 动态自适应计算架构设计
3.1 分层自适应架构
高性能动态 Shape 计算需要多层次自适应架构,在不同抽象层级进行智能决策:
|
架构层级 |
自适应目标 |
关键技术 |
性能影响 |
|---|---|---|---|
|
数据分块层 |
负载均衡 |
动态 Tiling 算法 |
决定并行效率 |
|
内存管理层 |
资源利用率 |
弹性内存分配 |
影响带宽利用率 |
|
计算调度层 |
硬件利用率 |
流水线调度 |
决定计算吞吐量 |
|
指令生成层 |
指令效率 |
向量化优化 |
影响单核性能 |
// 动态自适应架构核心实现
class DynamicAdaptiveArchitecture {
private:
TilingStrategy tiling_strategy_;
MemoryManager memory_manager_;
PipelineScheduler scheduler_;
VectorizationOptimizer vectorizer_;
public:
struct ExecutionPlan {
TilingStrategy tiling;
MemoryLayout memory_layout;
PipelineConfig pipeline;
VectorizationLevel vec_level;
};
ExecutionPlan create_adaptive_plan(const DynamicShape& input_shape, const HardwareInfo& hw_info) {
ExecutionPlan plan;
// 1. 基于输入形状和硬件特性选择分块策略
plan.tiling = select_tiling_strategy(input_shape, hw_info);
// 2. 根据分块策略设计内存布局
plan.memory_layout = optimize_memory_layout(input_shape, plan.tiling);
// 3. 自适应流水线配置
plan.pipeline = configure_pipeline(input_shape, plan.tiling, hw_info);
// 4. 向量化级别选择
plan.vec_level = select_vectorization_level(input_shape, hw_info);
return plan;
}
private:
TilingStrategy select_tiling_strategy(const DynamicShape& shape, const HardwareInfo& hw_info) {
auto analysis = analyze_shape_pattern(shape);
if (analysis.static_ratio > 0.8) {
// 高静态比例:使用激进分块
return create_aggressive_tiling(shape, hw_info);
} else if (analysis.static_ratio > 0.3) {
// 平衡场景:混合策略
return create_balanced_tiling(shape, hw_info);
} else {
// 高动态比例:保守分块
return create_conservative_tiling(shape, hw_info);
}
}
};此架构的智能之处在于能够根据输入特征和硬件能力,动态选择最优执行策略。
3.2 智能资源管理系统
资源管理是动态 Shape 算子的性能倍增器,其核心是预测与自适应能力:
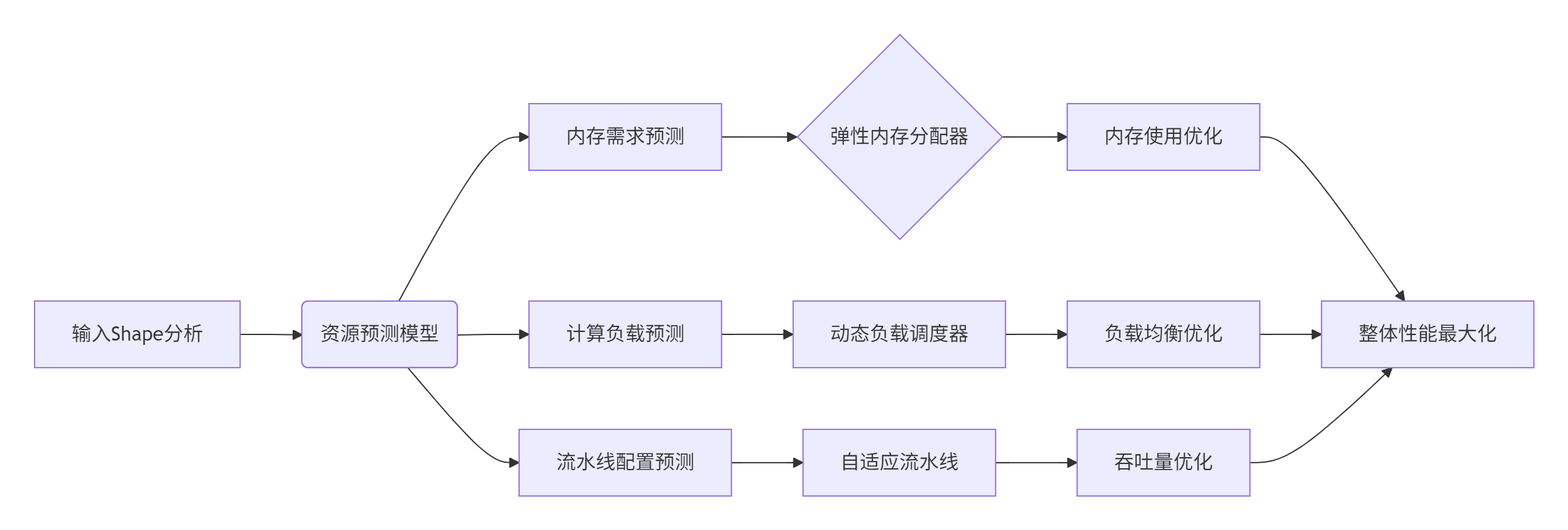
资源预测器实现:
class ResourcePredictor {
public:
struct ResourcePrediction {
size_t estimated_memory;
uint32_t expected_cycles;
uint32_t recommended_block_size;
bool has_memory_bottleneck;
};
ResourcePrediction predict(const DynamicShape& shape, const OperatorConfig& config) {
ResourcePrediction prediction;
// 内存需求预测
prediction.estimated_memory = predict_memory_requirement(shape, config);
// 计算周期预测
prediction.expected_cycles = predict_computation_cycles(shape, config);
// 瓶颈分析
prediction.has_memory_bottleneck = prediction.estimated_memory > config.memory_threshold;
// 分块大小推荐
prediction.recommended_block_size = recommend_block_size(shape, prediction);
return prediction;
}
private:
size_t predict_memory_requirement(const DynamicShape& shape, const OperatorConfig& config) {
size_t base_memory = shape.element_count() * get_type_size(config.data_type);
// 考虑临时缓冲区、中间结果等
size_t temp_memory = base_memory * 0.3; // 经验值:额外30%临时内存
return base_memory + temp_memory;
}
uint32_t recommend_block_size(const DynamicShape& shape, const ResourcePrediction& prediction) {
uint32_t base_block_size = 256; // 默认块大小
if (prediction.has_memory_bottleneck) {
// 内存受限场景:使用小块减少内存压力
return std::max(64u, base_block_size / 2);
} else {
// 计算受限场景:使用大块提高计算效率
return std::min(512u, base_block_size * 2);
}
}
};此预测系统通过历史学习和模型分析,实现对资源需求的精准预测,为运行时优化提供决策基础。
4 实战:动态 Softmax 算子的完整实现
4.1 算子分析与设计
Softmax 算子的动态化面临多维度挑战:
-
维度可变性:支持任意维度(1D-4D)输入
-
计算轴动态:在任意轴上进行 Softmax 计算
-
数值稳定性:动态范围下的数值稳定性保证
设计决策:
// 动态 Softmax 算子配置
struct DynamicSoftmaxConfig {
int axis; // Softmax 计算轴(可动态)
bool in_place; // 是否原位操作
DataType data_type; // 数据类型
float epsilon; // 数值稳定系数
};4.2 核心实现代码
Host 侧 Tiling 计算:
// 动态 Softmax Tiling 实现
class DynamicSoftmaxTiling {
public:
struct TilingData {
uint64_t total_elements;
uint64_t tile_size;
uint64_t num_tiles;
uint64_t axis_size;
uint64_t inner_size;
};
static TilingData compute_tiling(const DynamicShape& input_shape, int axis) {
TilingData tiling;
// 计算轴前维度大小
tiling.axis_size = input_shape.dim(axis);
// 计算轴前后元素数量
tiling.inner_size = 1;
for (int i = axis + 1; i < input_shape.rank(); ++i) {
tiling.inner_size *= input_shape.dim(i);
}
tiling.total_elements = input_shape.element_count();
// 动态计算分块大小(基于硬件特性)
tiling.tile_size = compute_optimal_tile_size(tiling.total_elements);
tiling.num_tiles = (tiling.total_elements + tiling.tile_size - 1) / tiling.tile_size;
return tiling;
}
private:
static uint64_t compute_optimal_tile_size(uint64_t total_elements) {
// 基于硬件特性和问题规模的智能分块
const uint64_t l1_cache_size = 64 * 1024; // 64KB L1 Cache
const uint64_t element_size = 2; // FP16
uint64_t cache_aware_tile = l1_cache_size / element_size / 2; // 预留缓冲区
// 考虑并行度优化
uint64_t parallelism_aware_tile = total_elements / get_processor_count();
return std::min(cache_aware_tile, parallelism_aware_tile);
}
};Device 侧 Kernel 实现:
// 动态 Softmax Kernel
__global__ __aicore__ void dynamic_softmax_kernel(
const half* input,
half* output,
const DynamicSoftmaxTiling::TilingData tiling,
int axis,
float epsilon) {
// 获取当前处理单元标识
uint32_t block_id = get_block_idx();
uint32_t block_num = get_block_num();
// 计算本单元处理的数据范围
auto [start_idx, end_idx] = compute_work_range(tiling, block_id, block_num);
// 每个 Block 内部独立计算 Softmax
for (uint64_t i = start_idx; i < end_idx; i += tiling.inner_size) {
// 1. 寻找最大值(数值稳定)
half max_val = find_max_value(input + i, tiling.inner_size);
// 2. 计算指数和
half exp_sum = compute_exp_sum(input + i, tiling.inner_size, max_val);
// 3. 归一化计算
compute_normalization(output + i, input + i, tiling.inner_size, max_val, exp_sum, epsilon);
}
}
// 数值稳定的指数和计算
__device__ half compute_exp_sum(const half* data, uint64_t size, half max_val) {
half sum = 0.0f;
for (uint64_t i = 0; i < size; ++i) {
half val = data[i];
half exp_val = exp(val - max_val); // 减最大值保证数值稳定
sum += exp_val;
}
return sum;
}此实现巧妙处理了动态形状和数值稳定性的平衡,确保在各种输入情况下都能获得正确且高效的计算结果。
4.3 高级优化:双缓冲与流水线
优化版本实现:
// 优化版动态 Softmax:双缓冲 + 流水线
class OptimizedDynamicSoftmax {
public:
__aicore__ void process_optimized(const half* input, half* output, const TilingData& tiling) {
// 双缓冲设置
__ubuf__ half buffer1[2][TILE_SIZE];
__ubuf__ half buffer2[2][TILE_SIZE];
int current_buffer = 0;
// 流水线处理
for (uint64_t tile_start = 0; tile_start < tiling.total_elements;
tile_start += tiling.tile_size) {
uint64_t current_tile_size = std::min(tiling.tile_size,
tiling.total_elements - tile_start);
// 异步加载下一个块
if (tile_start + tiling.tile_size < tiling.total_elements) {
uint64_t next_tile_start = tile_start + tiling.tile_size;
uint64_t next_tile_size = std::min(tiling.tile_size,
tiling.total_elements - next_tile_start);
async_data_load(buffer1[(current_buffer + 1) % 2],
input + next_tile_start, next_tile_size);
}
// 处理当前块(与下一次加载重叠)
process_tile(buffer1[current_buffer], buffer2[current_buffer],
current_tile_size, epsilon_);
// 异步写回结果
async_data_store(output + tile_start, buffer2[current_buffer],
current_tile_size);
// 切换缓冲区
current_buffer = (current_buffer + 1) % 2;
}
}
};此优化版本通过计算与数据传输重叠,有效隐藏了内存访问延迟,大幅提升整体性能。
5 性能优化与故障排查
5.1 性能优化技巧
基于大量实战经验,总结以下性能优化清单:
|
优化点 |
适用场景 |
预期收益 |
实现复杂度 |
|---|---|---|---|
|
向量化加载 |
连续内存访问 |
15-30% 带宽提升 |
低 |
|
双缓冲技术 |
内存受限操作 |
20-40% 延迟隐藏 |
中 |
|
循环展开 |
小循环体 |
10-20% 计算加速 |
低 |
|
共享内存 |
数据复用场景 |
25-50% 带宽节省 |
高 |
具体优化示例:
// 向量化内存访问优化
void vectorized_memory_access(const half* input, half* output, uint64_t size) {
constexpr uint64_t VECTOR_SIZE = 8; // 一次处理8个half元素
// 主循环向量化处理
uint64_t i = 0;
for (; i + VECTOR_SIZE <= size; i += VECTOR_SIZE) {
float4 vec_in = *reinterpret_cast<const float4*>(input + i);
float4 vec_out = compute_vectorized(vec_in); // 向量化计算
*reinterpret_cast<float4*>(output + i) = vec_out;
}
// 尾部处理
for (; i < size; ++i) {
output[i] = compute_element(input[i]);
}
}5.2 故障排查指南
常见问题及解决方案:
-
内存访问越界
// 防御性编程:边界检查 __aicore__ void safe_memory_access(const half* input, half* output, uint64_t size, uint64_t index) { if (index < size) { // 总是检查边界 output[index] = input[index] * 2.0f; } // 或者使用 clamp 操作 uint64_t safe_index = min(index, size - 1); } -
负载不均衡
// 动态负载监测与调整 class LoadBalancer { public: void adjust_balance(const std::vector<uint64_t>& work_loads) { uint64_t max_load = *std::max_element(work_loads.begin(), work_loads.end()); uint64_t min_load = *std::min_element(work_loads.begin(), work_loads.end()); // 如果负载不均衡超过阈值,重新分配 if (max_load > min_load * 1.3) { // 30% 不均衡阈值 rebalance_workload(work_loads); } } }; -
数值精度问题
// 高精度累加技巧 __aicore__ float high_precision_sum(const half* data, uint64_t size) { float sum = 0.0f; // 使用float进行累加 float compensation = 0.0f; // Kahan 补偿 for (uint64_t i = 0; i < size; ++i) { float y = static_cast<float>(data[i]) - compensation; float t = sum + y; compensation = (t - sum) - y; sum = t; } return sum; }
6 企业级实践与前瞻性思考
6.1 企业级解决方案
在实际工业部署中,动态 Shape 算子需要满足生产级要求:
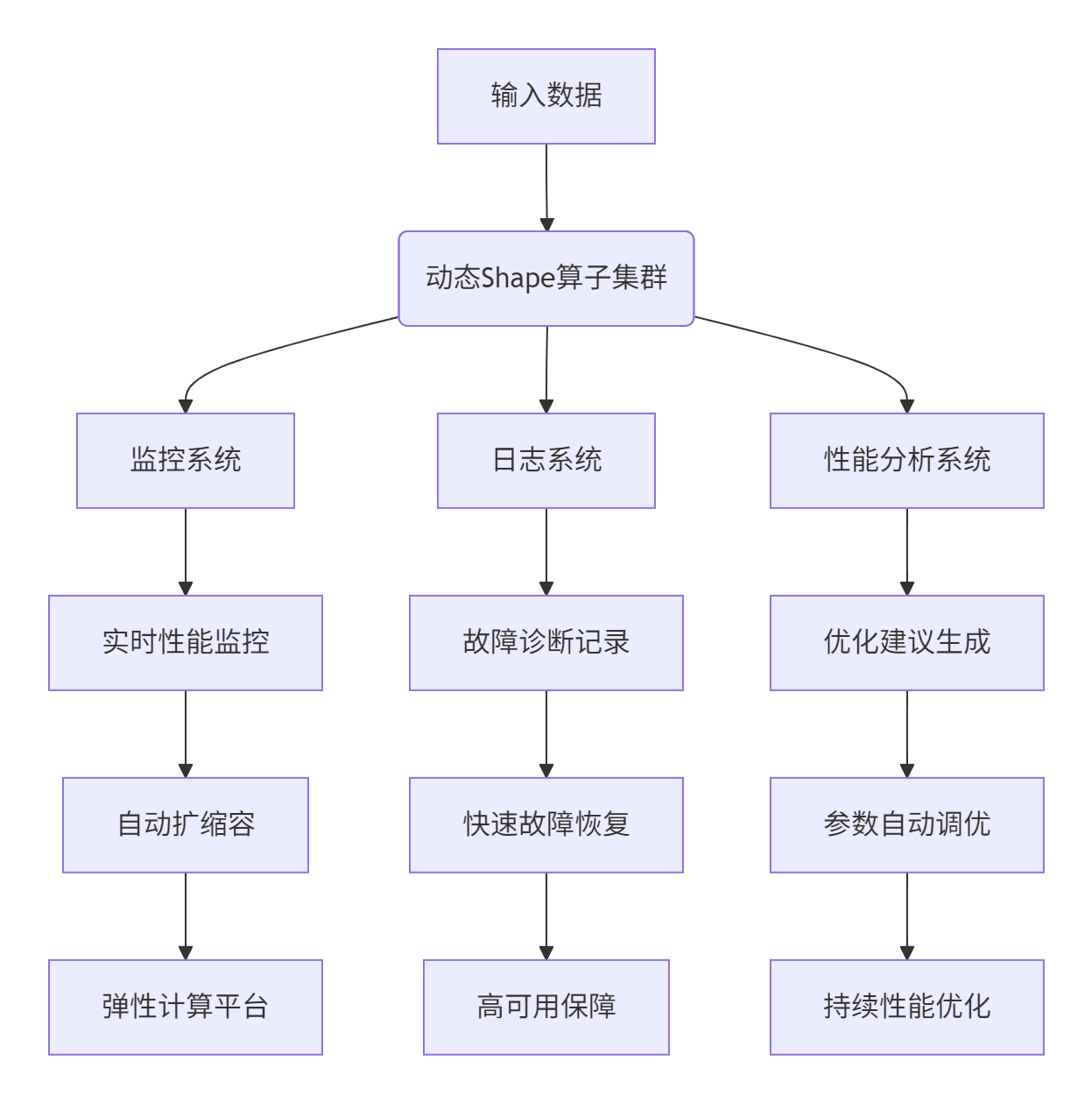
关键生产特性:
-
弹性扩缩容:根据负载动态调整计算资源
-
故障自愈:自动检测和恢复异常状态
-
性能监控:实时性能指标收集与分析
-
A/B 测试:不同优化策略效果对比
6.2 前瞻性技术思考
未来动态 Shape 技术将向以下方向发展:
-
AI 驱动的自动优化
// 未来愿景:AI 自动优化系统 class AIOptimizer { public: OptimizationStrategy auto_optimize(const DynamicShape& shape, const PerformanceMetrics& metrics) { // 基于强化学习自动选择最优策略 ReinforcementLearningAgent agent; return agent.predict_optimal_strategy(shape, metrics); } }; -
跨平台统一抽象
-
编写一次,到处高效运行
-
自动适配不同硬件特性
-
统一性能优化接口
-
-
编译期与运行期协同优化
-
编译期生成多种优化版本
-
运行期智能选择最优版本
-
动态代码生成与优化
-
总结
动态 Shape 自适应计算是 Ascend C 算子开发的核心技术高地。通过本文阐述的智能形状推导、动态资源管理和自适应优化策略,开发者可以构建出既高效又灵活的工业级算子。
关键洞察:
-
🎯 动态 Tiling 是基础:科学的负载均衡是实现高性能的前提
-
📊 形状推导是智能:准确的形状推断是资源优化的关键
-
⚡ 自适应架构是核心:多层次自适应实现全场景高性能
-
🔧 工具链完善是保障:强大工具链支撑快速开发和调试
未来展望:随着 AI 应用场景的不断复杂化,动态 Shape 支持将成为算子的必备能力而非可选特性。我们正朝着更智能、更自动化的优化方向发展,最终实现完全自适应的计算系统。
参考链接
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 23
23 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)