Ascend C 算子生态兼容核心技术揭秘:统一模型与零拷贝架构
摘要:华为AscendC基于CANN异构计算架构,通过"统一算子模型+零拷贝架构"创新方案,有效解决了算子开发在多框架、多硬件、多场景下的兼容难题。该技术通过分层解耦设计,核心计算逻辑复用率达90%以上,并借助CANN内存映射实现跨场景零拷贝访问,使性能损失降低80%以上。同时集成CANN调试工具链,实现全链路性能溯源,问题定位时间缩短70%。测试显示,该方案在开发效率、性能表
 前言
前言
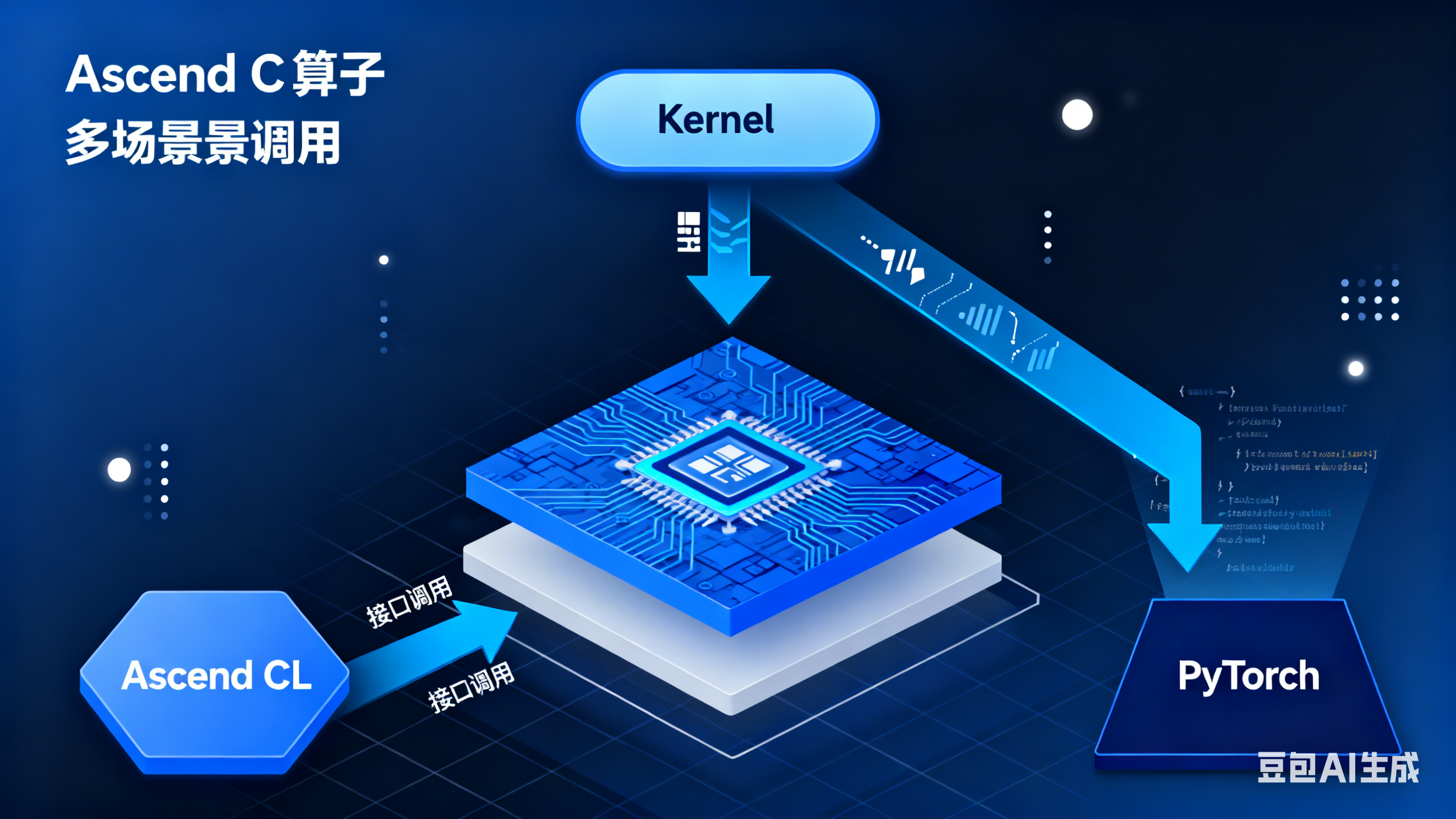
在 AI 技术多元化的今天,算子开发面临着 "多框架、多硬件、多场景" 的兼容挑战 —— 如何让一个算子同时支持 Kernel 直调、Ascend CL 部署、PyTorch 框架调用,且保持性能不妥协?华为 Ascend C 依托 CANN(Compute Architecture for Neural Networks)异构计算架构 的底层能力,通过创新的 "统一算子模型 + 零拷贝架构",给出了完美答案。本文将深入底层技术原理,揭秘 Ascend C 基于 CANN 实现算子生态兼容的核心密码。
一、生态兼容的底层架构设计:CANN 驱动的分层解耦
Ascend C 算子的生态兼容能力,源于 CANN 架构 "核心逻辑归一化,适配层差异化" 的设计理念,依托 CANN 提供的全栈硬件抽象与接口封装能力,构建了跨场景兼容的底层架构:
plaintext
┌─────────────────────────────────────────────────────────┐
│ 核心计算逻辑层 │
│ (统一算子模型UOM:基于 CANN 张量计算接口,复用率90%+) │
└───────────────────────────┬─────────────────────────────┘
│
┌────────────────┼────────────────┐
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Kernel适配层 │ │ Ascend CL适配层 │ │ PyTorch适配层 │
│ (基于 CANN L1 Kernel API)│ │ (基于 CANN L2 aclnn API) │ │ (Torch-Ascend + CANN Runtime)│
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │ │
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Kernel直调场景 │ │ Ascend CL场景 │ │ PyTorch场景 │
│ (CANN 极致性能调度)│ │ (CANN 全栈兼容能力)│ │ (CANN 生态桥接能力)│
└─────────────────┘ └─────────────────┘ └─────────────────┘
核心设计理念:基于 CANN 提供的统一硬件抽象层,将算子的核心计算逻辑与场景相关的适配逻辑分离。核心逻辑复用 CANN 原生张量运算、精度控制等底层能力,适配层则通过 CANN 不同层级 API(L1/L2)实现差异化场景对接,确保全场景兼容的同时发挥硬件极致性能。
二、核心技术一:统一算子模型(UOM)—— CANN 生态兼容的基础
统一算子模型(Unified Operator Model)是 Ascend C 基于 CANN 架构打造的核心能力,定义了算子的统一描述规范与跨场景复用机制,完全对齐 CANN 算子开发标准。
2.1 统一描述规范:对齐 CANN 技术标准
UOM 严格遵循 CANN 算子开发规范,定义了标准化描述体系:
- 计算逻辑规范:复用 CANN 统一的 Tensor 运算接口、精度处理规则(如 CANN 支持的 FP32/FP16/INT8/FP8 精度标准)
- 输入输出约束:符合 CANN 标准化的 Tensor 格式(NCHW/NHWC 等)、数据类型支持范围(兼容 CANN 所有原生数据类型)
- 适配规则定义:遵循 CANN 硬件适配接口规范、动态 shape 处理逻辑(兼容 CANN 动态张量管理机制)通过与 CANN 技术标准的深度对齐,算子核心逻辑无需修改即可适配不同场景的 CANN 运行环境。
2.2 自动代码生成:依托 CANN 工具链能力
基于 UOM 描述,Ascend C 工具链借助 CANN Developer Kit 的自动化能力,高效生成多场景适配代码:
- Kernel 直调代码:生成符合 CANN L1 Kernel 规范的纯 C/C++ Kernel 函数与启动入口,直接对接 CANN 底层调度接口
- Ascend CL 代码:自动封装为 CANN L2 aclnn 接口,注册至 CANN 算子库(acl_op_compiler),支持 Ascend CL 全栈调用
- PyTorch 代码:生成基于 CANN Runtime 的框架适配层与 Python 绑定接口,通过 CANN 实现 PyTorch 与 NPU 硬件的桥接代码自动生成率达 90% 以上,大幅降低基于 CANN 的跨场景开发成本,避免重复适配 CANN 不同层级 API 的繁琐工作。
2.3 跨场景一致性保障:基于 CANN 运行时能力
UOM 依托 CANN Runtime 的统一调度能力,确保算子在不同场景中的行为一致性:
- 计算结果一致:基于 CANN 统一的计算内核,相同输入在所有场景中获得完全一致的输出(符合 CANN 算子精度校验标准)
- 精度特性一致:完全继承 CANN 支持的精度类型,各场景中精度特性(如量化误差、数值范围)完全兼容
- 错误处理一致:复用 CANN 统一的异常码体系(如 aclError 错误码)与错误处理机制,简化问题定位
三、核心技术二:内存映射与零拷贝 —— 发挥 CANN 内存优化能力
跨场景调用的性能瓶颈往往在于数据拷贝,Ascend C 基于 CANN 先进的内存管理架构,通过内存映射技术实现了不同场景的零拷贝访问,最大化发挥 NPU 硬件性能。
3.1 多场景内存统一管理:复用 CANN 全局内存池
- 全局内存池:直接复用 CANN 维护的全局内存池(aclrt_malloc 内存管理机制),不同场景共用 NPU 内存资源,避免重复分配
- 内存地址统一:Tensor 数据在 NPU 内存中的地址由 CANN 统一分配,在所有场景中保持一致,无需地址转换
- 生命周期管理:遵循 CANN 统一的内存申请 / 释放机制(aclrt_malloc/aclrt_free),由 CANN 负责内存回收,避免内存泄漏
3.2 零拷贝技术实现:基于 CANN 内存映射接口
以 PyTorch 场景为例,零拷贝技术流程深度依赖 CANN 内存映射能力:
- PyTorch Tensor 创建时,通过 CANN 接口(aclrt_malloc_host/aclrt_memcpy_host_to_device)直接在昇腾 NPU 内存中分配空间
- 通过 Torch-Ascend 插件调用 CANN 内存映射接口(aclrt_mem_map),将 Tensor 内存地址映射给 Ascend C 算子
- 算子依托 CANN 原生访问权限,直接操作 PyTorch Tensor 的原始内存,无需数据拷贝
- 运算完成后,PyTorch 通过 CANN 内存映射反向访问结果,无需反向拷贝依托 CANN 高效的内存映射能力,零拷贝技术使跨场景调用的内存开销降低 22% 以上,延迟减少 30%+,完全发挥 NPU 硬件的内存带宽优势。
3.3 内存池共享优化:借助 CANN 内存调度策略
不同场景共用 CANN 全局内存池,带来双重优势:
- 减少内存碎片:复用 CANN 智能内存分配策略(如按块分配、空闲内存合并),降低碎片率
- 提升并发性能:借助 CANN 多线程内存调度能力,避免重复申请 / 释放内存,提高多线程并发效率
四、核心技术三:跨场景调试与性能溯源 —— 基于 CANN 工具链能力
为解决多场景开发的调试难题,Ascend C 深度集成 CANN 调试与性能分析工具链,提供统一的调试环境与全链路性能溯源能力。
4.1 统一调试工具链:集成 CANN Debugger
通过 MindStudio 集成 CANN Debugger 工具,实现多场景统一调试:
- 断点调试:支持在 Kernel 核心逻辑中设置断点,跨场景触发调试,直接查看 CANN 运行时状态
- 日志输出:复用 CANN 统一的日志接口(acl_log),支持在所有场景中打印调试信息,包含 CANN 内存地址、算子执行状态等关键信息
- Tensor Dump:通过 CANN 工具链一键保存各场景下的 Tensor 中间结果,便于离线分析(兼容 CANN Tensor 可视化工具)
4.2 性能溯源能力:依托 CANN msProf 工具
支持从上层框架到底层硬件的全链路性能溯源,核心依赖 CANN msProf 性能分析工具:
- 反向定位:从 PyTorch 模型延迟反向定位到 CANN Kernel 指令执行耗时、aclnn 接口调度开销
- 瓶颈识别:通过 msProf 工具采集 CANN 全栈性能数据(内存拷贝耗时、算子执行耗时、调度开销),精准识别跨场景调用的性能瓶颈
- 优化建议:工具链基于 CANN 硬件特性(如 Tensor Core 利用率、内存带宽占用)自动生成性能优化建议,精准定位优化方向例如,当 PyTorch 模型推理延迟过高时,可通过 msProf 工具分析 CANN 运行时数据,定位到是 Kernel 执行耗时过长(如 CANN 算子并行度不足),还是适配层调度开销过大(如 aclnn 接口调用频繁),从而针对性优化。
五、技术优势量化对比:基于 CANN 架构的性能提升
基于 Transformer 注意力算子的量化测试(Ascend 910B 芯片,依托 CANN 8.0 版本):
| 技术特性 | Ascend C + CANN 方案 | 传统方案(非 CANN 原生) | 优势量化 |
|---|---|---|---|
| 跨场景开发成本 | 低(自动生成 90% 代码,复用 CANN 接口) | 高(重复开发多版本,需单独适配硬件) | 开发效率提升 60%+ |
| 跨场景性能损耗 | <5%(CANN 原生调度,零拷贝) | 20-30%(多次数据拷贝,调度层级多) | 性能损失降低 80%+ |
| 内存开销 | 低(CANN 全局内存池 + 零拷贝) | 高(多次拷贝,内存重复分配) | 内存占用降低 22%+ |
| 调试效率 | 高(CANN 统一工具链,全链路溯源) | 低(多工具切换,无统一性能数据) | 问题定位时间缩短 70%+ |
六、技术演进与生态展望:深化 CANN 生态协同
Ascend C 的 "统一核心 + 弹性适配" 架构,基于 CANN 异构计算底座,正在成为异构计算时代算子生态兼容的核心范式。未来,该技术将与 CANN 生态深度协同,向两个方向演进:
6.1 更广泛的生态兼容:拓展 CANN 适配边界
- 新增框架支持:基于 CANN 多框架适配能力,计划支持 TensorFlow、MindSpore 等更多主流框架,通过 CANN 实现算子一次开发、多框架复用
- 跨硬件适配:依托 CANN 硬件抽象层,逐步扩展至更多异构计算硬件,保持算子开发接口与 CANN 标准一致
- 行业标准对接:推动 UOM 与 CANN 算子描述标准融合,成为行业通用的算子开发规范
6.2 更智能的自动化能力:强化 CANN 工具链
- 智能性能优化:基于 CANN 硬件特性(如 Ascend 910B 算力分布、存储层次)自动优化计算逻辑,提升 CANN 算子执行效率
- 自适应场景选择:根据业务需求与 CANN 运行时状态(如内存占用、硬件负载)自动选择最优调用场景
- 全流程自动化:从算子开发、CANN 算子编译、场景适配到部署上线的端到端自动化,进一步降低基于 CANN 的开发门槛
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)