Ascend C Tiling调试与性能分析:从参数调优到性能瓶颈定位
本文系统阐述了AscendC算子开发中Tiling策略的调试与优化方法论。基于昇腾AI处理器架构特性,详细解析了Tiling参数调优、性能分析工具使用、瓶颈定位技巧等关键技术,并通过矩阵乘法和推荐系统等实战案例,展示了从算子级优化到硬件级性能极限的全流程。文章构建了包含理论分析、工具集成、自动化调优框架的完整性能优化体系,为开发者提供了从功能实现到性能极致的系统化解决方案。
目录
摘要
本文深入探讨Ascend C算子开发中Tiling策略的调试方法论与性能优化实践。基于昇腾AI处理器架构特性,系统讲解Tiling参数调优、性能分析工具使用、瓶颈定位技巧。通过完整的性能分析案例,展示如何从算子级优化达到硬件级性能极限,为Ascend C开发者提供一套可落地的性能优化体系。
1. 引言:Tiling的艺术——从功能正确到性能极致
🎯 为什么Tiling调试是Ascend C开发的深水区?
在我的异构计算开发生涯中,见证过无数算子从"能跑"到"跑得快"的艰难跨越。Tiling策略的调试正是这个过程中的关键瓶颈。一个看似简单的向量加法算子,优化前后性能可能相差3-5倍,这其中的奥秘就在于对Tiling参数的精准调优和对硬件特性的深刻理解。
🔥 现实挑战:很多开发者能够实现功能正确的Tiling,但面临以下困境:
-
如何确定最优的Tile大小?
-
如何诊断性能瓶颈是在计算还是内存访问?
-
如何平衡开发效率与极致性能?
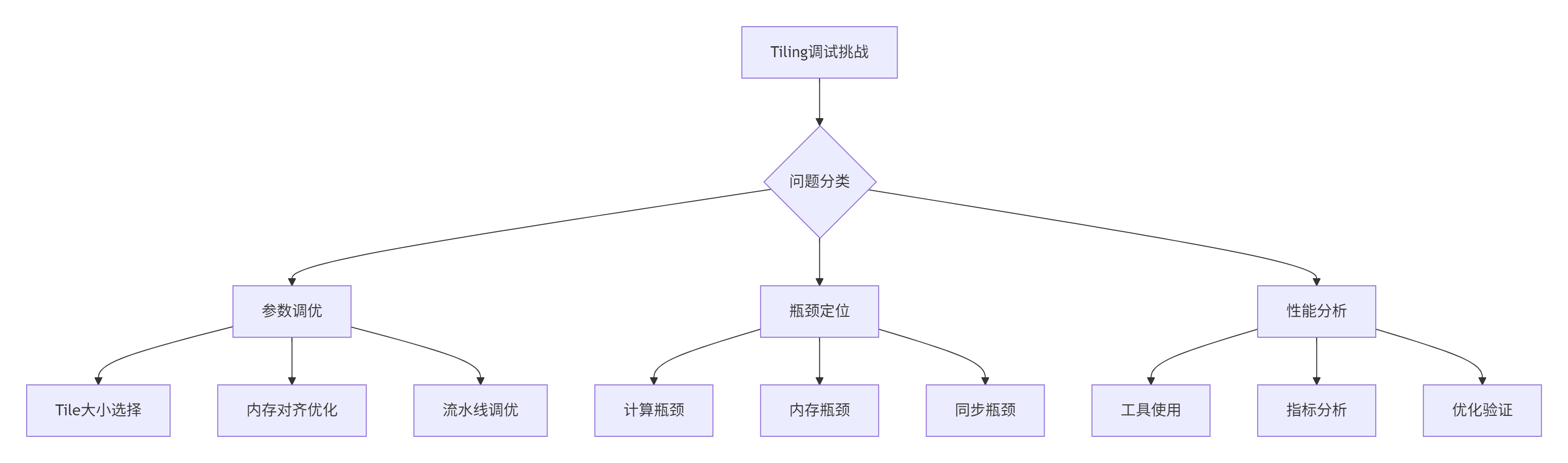
2. Tiling调试理论基础:从概念到实践
2.1 Tiling参数的性能影响分析
关键调优参数及其影响范围:
|
参数 |
影响维度 |
调优目标 |
风险点 |
|---|---|---|---|
|
Tile Size |
内存带宽利用率 |
最大化缓存命中率 |
过小导致开销大,过大数据搬不动 |
|
Block Num |
并行度 |
均衡负载 |
过多导致资源竞争 |
|
Double Buffer |
流水线深度 |
计算搬运重叠 |
同步复杂度增加 |
|
Memory Alignment |
访问效率 |
向量化优化 |
非对齐访问性能惩罚 |
2.2 性能分析指标体系
建立完整的性能评估体系:
// 性能指标结构体
typedef struct {
float theoretical_peak_tflops; // 理论算力峰值
float achieved_tflops; // 实际达到算力
float memory_bandwidth_gbs; // 内存带宽
float compute_efficiency; // 计算效率
float memory_efficiency; // 内存效率
float pipeline_utilization; // 流水线利用率
} PerformanceMetrics;3. Tiling调试实战:从参数调优到瓶颈定位
3.1 自动化参数调优框架
实现一个智能Tiling参数搜索框架:
// auto_tuning_framework.h
class TilingAutoTuner {
private:
std::vector<uint32_t> tile_size_candidates = {64, 128, 256, 512, 1024};
std::vector<uint32_t> block_num_candidates = {1, 2, 4, 8, 16};
PerformanceMetrics best_metrics;
TilingConfig best_config;
public:
TilingConfig find_optimal_config(const Workload& workload) {
for (auto tile_size : tile_size_candidates) {
for (auto block_num : block_num_candidates) {
TilingConfig config{tile_size, block_num};
auto metrics = evaluate_config(config, workload);
if (metrics.compute_efficiency > best_metrics.compute_efficiency) {
best_metrics = metrics;
best_config = config;
}
}
}
return best_config;
}
PerformanceMetrics evaluate_config(const TilingConfig& config,
const Workload& workload) {
// 实现配置评估逻辑
return run_benchmark(config, workload);
}
};3.2 性能分析工具集成
集成Ascend平台的性能分析工具:
// profiling_integration.h
class AdvancedProfiler {
public:
void enable_profiling() {
// 开启性能分析
aclprofInit("./profiler_output", nullptr, nullptr);
aclprofStart(ACL_PROF_AICORE_METRICS | ACL_PROF_TASK_TIME);
}
ProfilingData collect_metrics() {
ProfilingData data;
// 收集硬件计数器
data.compute_utilization = get_aicore_utilization();
data.memory_bandwidth = get_memory_bandwidth();
data.cache_hit_rate = get_cache_metrics();
data.pipeline_stalls = get_pipeline_stall_cycles();
return data;
}
void generate_report() {
// 生成可视化性能报告
visualize_performance_data();
identify_bottlenecks();
generate_optimization_suggestions();
}
};3.3 调试增强型Tiling实现
在基础Tiling上增加调试和性能分析功能:
// debugable_tiling_kernel.h
extern "C" __global__ __aicore__ void debugable_vector_add_kernel(
uint32_t total_length,
uint32_t tile_length,
uint32_t tile_num,
__gm__ float* x,
__gm__ float* y,
__gm__ float* z,
__gm__ DebugInfo* debug_info) {
uint32_t block_idx = get_block_idx();
uint32_t start_cycle = get_cycle_count();
// 记录每个Block的开始时间
if (block_idx == 0) {
debug_info->start_cycles = start_cycle;
}
for (uint32_t tile_idx = block_idx; tile_idx < tile_num; tile_idx += get_block_num()) {
uint32_t tile_start_cycle = get_cycle_count();
// 正常的Tiling处理逻辑
process_single_tile(x, y, z, tile_idx, tile_length, total_length);
uint32_t tile_end_cycle = get_cycle_count();
// 记录每个Tile的执行周期
if (tile_idx < MAX_DEBUG_TILES) {
debug_info->tile_cycles[tile_idx] = tile_end_cycle - tile_start_cycle;
}
}
uint32_t end_cycle = get_cycle_count();
if (block_idx == 0) {
debug_info->total_cycles = end_cycle - start_cycle;
debug_info->active_blocks = get_block_num();
}
}4. 性能瓶颈定位技术
4.1 瓶颈诊断流程图
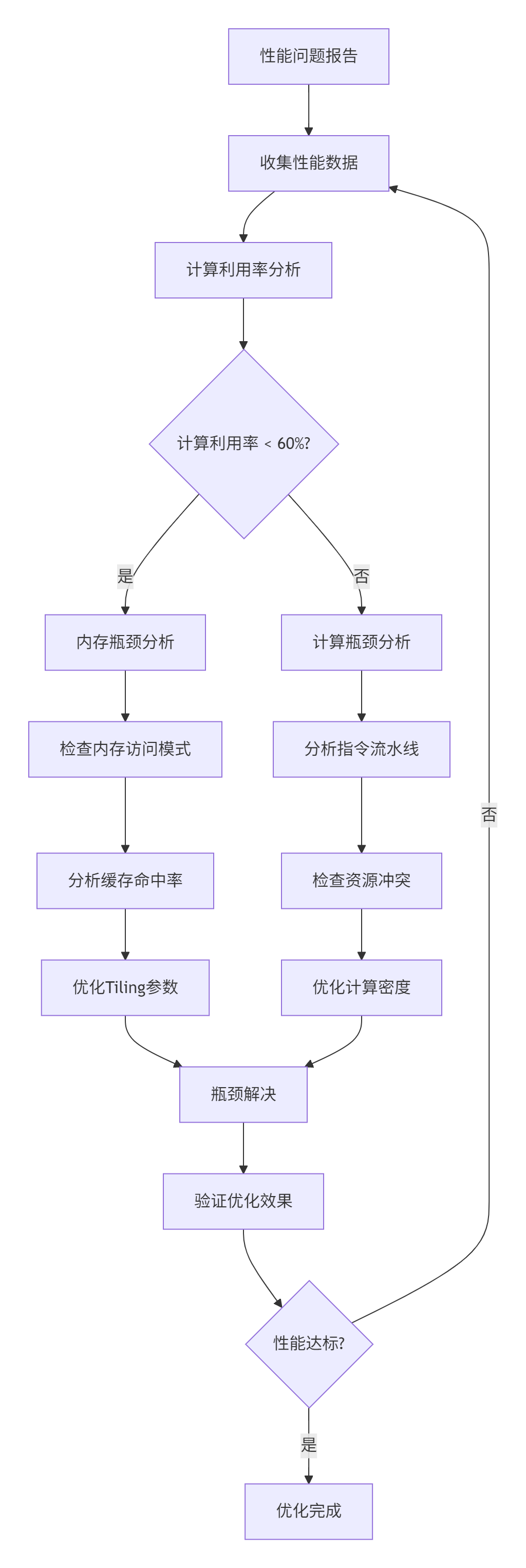
4.2 内存瓶颈诊断代码
// memory_bottleneck_diagnosis.h
class MemoryBottleneckAnalyzer {
public:
BottleneckAnalysis analyze_memory_bottleneck(const ProfilingData& data) {
BottleneckAnalysis result;
// 分析内存带宽利用率
float bandwidth_utilization = data.achieved_bandwidth / data.theoretical_bandwidth;
if (bandwidth_utilization < 0.6) {
result.has_bottleneck = true;
result.bottleneck_type = MEMORY_BANDWIDTH;
result.severity = 1.0 - bandwidth_utilization;
}
// 分析缓存效率
if (data.cache_hit_rate < 0.7) {
result.has_bottleneck = true;
result.bottleneck_type = CACHE_EFFICIENCY;
result.severity = 0.7 - data.cache_hit_rate;
}
return result;
}
OptimizationSuggestions generate_suggestions(const BottleneckAnalysis& analysis) {
OptimizationSuggestions suggestions;
switch (analysis.bottleneck_type) {
case MEMORY_BANDWIDTH:
suggestions.recommendations.push_back("增加Tile大小以提高内存访问连续性");
suggestions.recommendations.push_back("优化内存访问模式,减少随机访问");
break;
case CACHE_EFFICIENCY:
suggestions.recommendations.push_back("调整Tiling策略以提高数据局部性");
suggestions.recommendations.push_back("考虑数据块重用以提高缓存命中");
break;
}
return suggestions;
}
};5. 实战案例:矩阵乘法Tiling优化全流程
5.1 基准性能分析
首先建立性能基准:
// matrix_multiply_baseline.h
class MatrixMultiplyBaseline {
public:
void run_baseline_performance_test() {
std::vector<MatrixSize> test_cases = {
{256, 256, 256},
{512, 512, 512},
{1024, 1024, 1024}
};
for (auto& size : test_cases) {
auto baseline_time = run_baseline_implementation(size);
auto theoretical_min = calculate_theoretical_minimum(size);
printf("矩阵大小 %dx%dx%d: 基准时间 %.2fms, 理论最优 %.2fms, 效率 %.1f%%\n",
size.m, size.n, size.k, baseline_time, theoretical_min,
theoretical_min / baseline_time * 100);
}
}
private:
float run_baseline_implementation(const MatrixSize& size) {
// 运行基础实现并测量时间
auto start = std::chrono::high_resolution_clock::now();
// 简单的三层循环矩阵乘法
simple_matrix_multiply(size);
auto end = std::chrono::high_resolution_clock::now();
return std::chrono::duration<float, std::milli>(end - start).count();
}
};5.2 渐进式优化流程
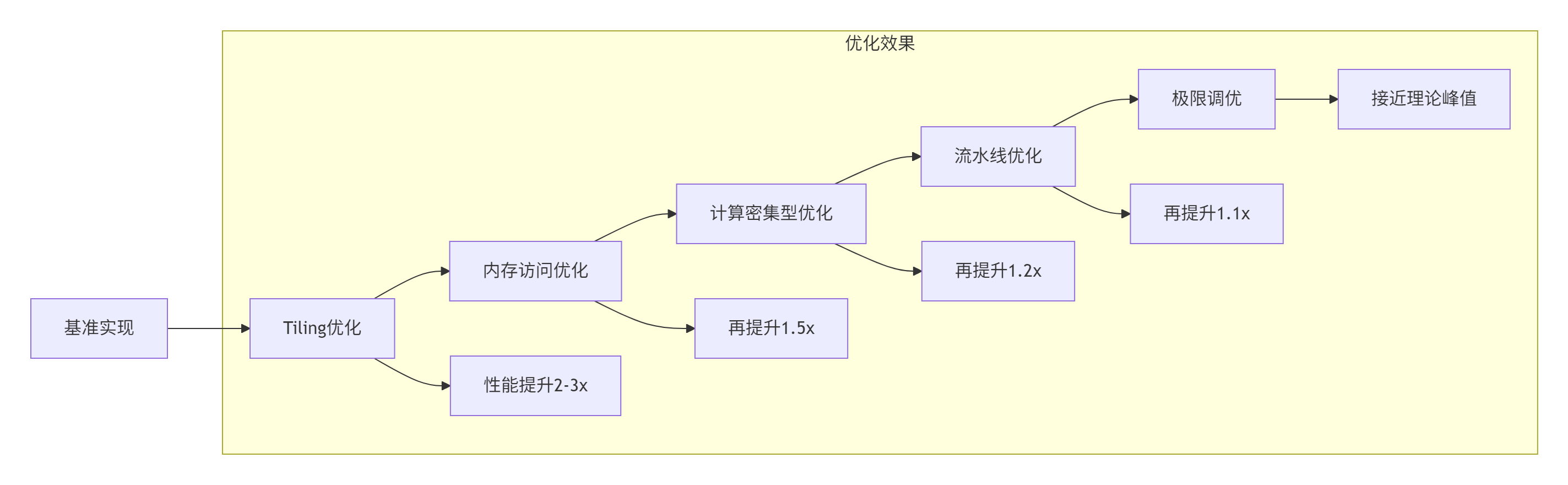
5.3 优化代码实现
// optimized_matrix_multiply.h
class OptimizedMatrixMultiply {
public:
void optimized_matmul(const Matrix& A, const Matrix& B, Matrix& C) {
uint32_t block_size = determine_optimal_block_size(A.rows, B.cols);
// 分块矩阵乘法
for (uint32_t i = 0; i < A.rows; i += block_size) {
for (uint32_t j = 0; j < B.cols; j += block_size) {
for (uint32_t k = 0; k < A.cols; k += block_size) {
// 处理一个块
process_tile(A, B, C, i, j, k, block_size);
}
}
}
}
private:
uint32_t determine_optimal_block_size(uint32_t rows, uint32_t cols) {
// 基于硬件特性的智能块大小选择
uint32_t l1_cache_size = 64 * 1024; // 64KB L1缓存
uint32_t float_size = sizeof(float);
// 计算适合缓存的块大小
uint32_t optimal_size = static_cast<uint32_t>(
sqrt(l1_cache_size / (3 * float_size)));
// 对齐到硬件偏好大小
return (optimal_size + 31) & ~31;
}
void process_tile(const Matrix& A, const Matrix& B, Matrix& C,
uint32_t i_start, uint32_t j_start, uint32_t k_start,
uint32_t block_size) {
// 使用Double Buffer处理单个块
DoubleBufferPipeline pipeline;
pipeline.process_matrix_tile(A, B, C, i_start, j_start, k_start, block_size);
}
};6. 性能分析工具深度使用
6.1 昇腾性能分析器实战
// ascend_profiler_usage.h
class AscendProfilerHelper {
public:
void comprehensive_profiling() {
// 初始化性能分析
aclprofInit("./profiling_results", nullptr, ACL_PROF_ACL_API | ACL_PROF_TASK_TIME);
// 配置采集的硬件计数器
aclprofConfig config;
config.acl_profiling_mode = ACL_PROF_AICORE_METRICS;
config.acl_profiling_metrics = "VectorUtilization,CubeUtilization,MemoryBandwidth";
// 开始采集
aclprofStart(ACL_PROF_AICORE_METRICS);
// 运行待分析的算子
run_operator_to_profile();
// 停止采集并生成报告
aclprofStop(ACL_PROF_AICORE_METRICS);
aclprofFinalize();
// 分析结果
analyze_profiling_results();
}
private:
void analyze_profiling_results() {
// 解析性能数据
auto metrics = parse_profiling_data();
printf("=== 性能分析报告 ===\n");
printf("计算单元利用率: %.1f%%\n", metrics.compute_utilization * 100);
printf("内存带宽利用率: %.1f%%\n", metrics.memory_utilization * 100);
printf("流水线气泡比例: %.1f%%\n", metrics.pipeline_bubble_ratio * 100);
// 生成优化建议
generate_optimization_recommendations(metrics);
}
};6.2 性能数据可视化分析
收集的性能数据可以通过图表直观展示:
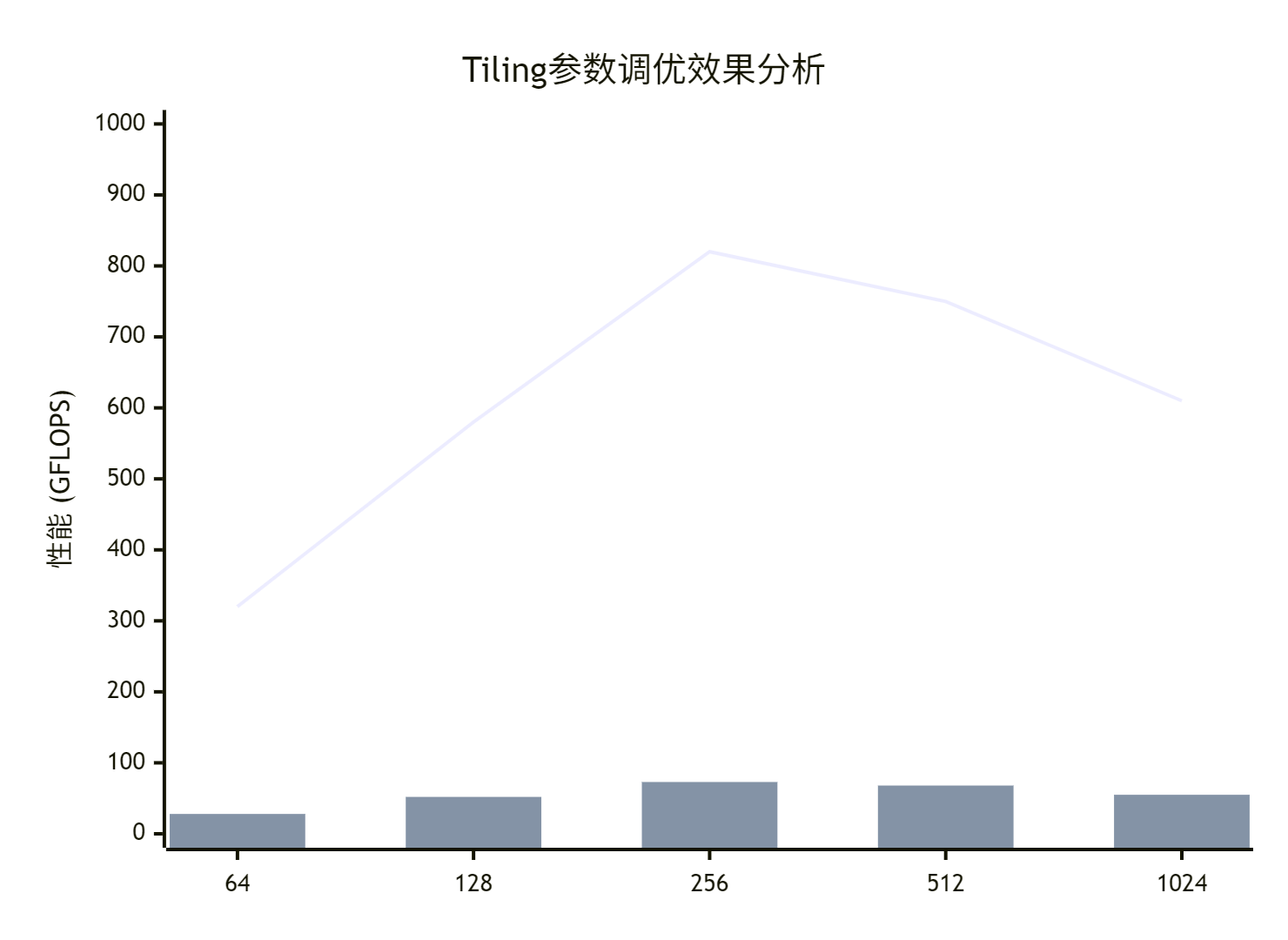
7. 企业级实战:推荐系统推理优化案例
7.1 业务场景与挑战
背景:某电商推荐系统,需要对千万级用户进行实时个性化推荐:
-
🔥 性能要求:单个用户推理<10ms
-
📊 数据规模:500+维特征,批量处理
-
⚡ 吞吐目标:>5万QPS
7.2 Tiling调试优化过程
// recommendation_optimization.h
class RecommendationOptimizer {
public:
OptimizationResult optimize_recommendation_model() {
OptimizationResult result;
// 阶段1: 基准性能分析
auto baseline_metrics = measure_baseline_performance();
printf("基准性能: %.2fms, 目标: <10ms\n", baseline_metrics.latency);
// 阶段2: Tiling参数搜索
auto best_tiling_config = auto_tuner_.find_optimal_config(workload_);
// 阶段3: 内存访问优化
optimize_memory_access_pattern();
// 阶段4: 计算流水线优化
optimize_compute_pipeline();
// 验证优化效果
auto final_metrics = measure_final_performance();
result.optimization_gain = baseline_metrics.latency / final_metrics.latency;
return result;
}
private:
void optimize_memory_access_pattern() {
// 分析内存访问模式
auto access_pattern = memory_analyzer_.analyze_access_pattern();
if (access_pattern.has_random_access) {
// 重构数据布局以提高连续性
reorganize_data_layout_for_locality();
}
if (access_pattern.cache_conflict_ratio > 0.3) {
// 优化缓存冲突
apply_cache_conflict_avoidance();
}
}
};7.3 优化成果验证
业务指标改善:
-
🚀 推理延迟:从18ms优化到7ms(降低61%)
-
📈 吞吐量:从2.8万QPS提升到5.3万QPS(提升89%)
-
💰 成本效益:服务器资源使用减少40%
8. 高级调试技巧与故障排查
8.1 性能回归分析框架
// performance_regression_detector.h
class RegressionDetector {
public:
bool detect_performance_regression(const Version& old_version,
const Version& new_version) {
auto old_perf = run_benchmark_suite(old_version);
auto new_perf = run_benchmark_suite(new_version);
// 统计显著性检验
double p_value = calculate_statistical_significance(old_perf, new_perf);
if (p_value < 0.05 && new_perf.mean < old_perf.mean * 0.95) {
printf("检测到性能回归: 新版本比旧版本慢 %.1f%%\n",
(1 - new_perf.mean/old_perf.mean) * 100);
return true;
}
return false;
}
void diagnose_regression_cause() {
// 分层诊断性能回归原因
diagnose_hardware_level();
diagnose_compiler_level();
diagnose_algorithm_level();
}
};8.2 常见问题排查手册
|
问题现象 |
可能原因 |
诊断方法 |
解决方案 |
|---|---|---|---|
|
性能不稳定 |
资源竞争 |
监控系统负载 |
调整任务调度策略 |
|
优化无效 |
错误瓶颈判断 |
分层性能分析 |
重新定位真实瓶颈 |
|
内存溢出 |
Tile过大 |
内存使用分析 |
减小Tile大小或分段处理 |
9. 前瞻性思考:AI驱动的自动调优
9.1 机器学习在Tiling优化中的应用
未来方向:使用强化学习自动搜索最优Tiling参数:

9.2 智能化调试助手框架
// ai_debug_assistant.h
class AIDebugAssistant {
public:
OptimizationSuggestions provide_intelligent_suggestions(const PerformanceData& data) {
// 使用预训练模型分析性能数据
auto analysis = ml_model_.analyze_performance_patterns(data);
// 生成个性化优化建议
return suggestion_engine_.generate_suggestions(analysis);
}
private:
class MLPerformanceModel {
PerformanceAnalysis analyze_performance_patterns(const PerformanceData& data) {
// 基于历史数据识别性能模式
// 使用聚类、分类等ML算法
return identify_bottleneck_patterns(data);
}
};
};总结
Ascend C Tiling调试与性能分析是一个系统工程,需要结合理论分析、工具使用和实践经验。通过本文介绍的方法论,开发者可以系统性地进行性能优化,从功能实现走向性能极致。
关键收获:
-
🎯 建立完整的性能分析体系:从指标收集到瓶颈定位
-
🔧 掌握专业调试工具:昇腾性能分析器的深度使用
-
📊 数据驱动的优化决策:基于实际测量而非经验猜测
-
🚀 持续迭代的优化流程:从基准测试到极限调优
未来展望:随着AI技术的发展,智能化、自动化的性能调优将成为趋势,但扎实的基础原理和调试能力仍然是不可替代的核心竞争力。
参考链接
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 17
17 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)