从计算逻辑到可执行算子:基于华为 TBE DSL 的实战指南
本文面向工程实践者,系统讲解如何用华为昇腾(CANN)提供的 TBE DSL(Domain-Specific Language)快速实现自定义算子。文章从 DSL 的设计理念与工作流切入,逐步覆盖算子分析、计算实现、自动调度(Auto Schedule)原理、编译与验证、以及在精度/性能维度的优化技巧与常见陷阱。文中穿插端到端的 Add 算子示例,并给出工程化注意点与排错思路,帮助你把算子从“数学
从计算逻辑到可执行算子:基于华为 TBE DSL 的实战指南
本文面向工程实践者,系统讲解如何用华为昇腾(CANN)提供的 TBE DSL(Domain-Specific Language)快速实现自定义算子。文章从 DSL 的设计理念与工作流切入,逐步覆盖算子分析、计算实现、自动调度(Auto Schedule)原理、编译与验证、以及在精度/性能维度的优化技巧与常见陷阱。文中穿插端到端的 Add 算子示例,并给出工程化注意点与排错思路,帮助你把算子从“数学表达”可靠地落地到可被网络加载的二进制模块。
一、为什么使用 DSL?设计理念与优势
在深度学习硬件加速的实践中,计算描述和执行调度通常是两条互相耦合但又需要分别优化的主线。TBE DSL 的核心设计就是把“我们想要做什么(计算逻辑)”和“如何高效执行(调度)”在工程上进行解耦:
- 开发者只需用 DSL 描述算子的数学计算过程(如逐元素运算、reduce、卷积等),专注算法正确性与数值精度;
- TBE 提供的 Auto Schedule 会基于算子的计算语法树(AST)自动选择合适的调度模板、完成 tiling、数据流管理与指令映射,从而将计算映射到昇腾硬件上并尽量利用底层资源(向量单元、矩阵单元、双缓冲、流水线等)。
这种模式的优势包括:降低调度复杂度、缩短开发周期、在常见模式下取得接近人工调度的性能、并且保持算子实现的一致性与可维护性。但也带来一个限制:当 DSL 无法覆盖某些底层需求或需要特殊指令级优化时,开发者需要退到更底层的 TIK(或其他方式)进行精细化控制。
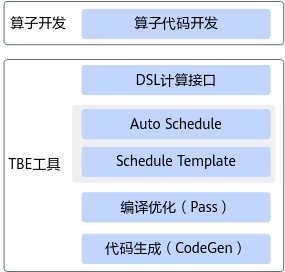
二、TBE DSL 的功能框架(从输入到可执行的流水线)
把 DSL 算子的实现看成一条流水线,可以分为几个清晰阶段:
-
计算逻辑描述(Compute)
使用tbe.dsl系列接口(如vadd,vexp,sum,conv等)组装算子的计算步骤,形成 TVM 风格的 compute 语法树(AST)。
开发者负责确定计算顺序、必要的数据变换(如广播、转置)以及数值类型检查。 -
Auto Schedule(自动调度)
将生成的 compute AST 传入tbe.dsl.auto_schedule()。内部会对每个 compute 语句加上tag_scope,识别子图 pattern(例如 elewise、reduce、conv、pooling 等),按 pattern 切分子图并为每个子图选择调度模板,完成 tiling、数据流安排与指令映射。 -
中间表示(IR)与编译优化(Pass)
Auto Schedule 后会生成类似 TVM 的 IR。随后若干编译 Pass(双缓冲、流水线同步、内存分配优化、矩阵单元分块等)对 IR 做逐步优化。 -
CodeGen 与二进制生成
最终 CodeGen 将 IR 转换为类 C 的临时代码,经过编译产出算子目标文件(.o)和算子描述文件(.json),由框架运行时加载调用。
整个流程对于开发者来说简化成:写 compute -> auto_schedule -> build。下面以 Add 算子为示例展示具体实现与工程细节。
三、入门示例:Add 算子的设计与实现(端到端)
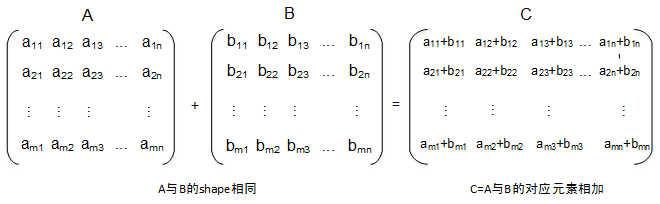
3.1 功能与规格
- 功能:
y = x1 + x2(逐元素相加,支持广播) - 支持数据类型:
float16, float32, int32 - 支持格式:
NCHW, NC1HWC0, NHWC, ND - 输出与输入 shape 保持一致(按广播规则)
3.2 设计要点
- 广播处理:DSL 的
vadd要求两个输入 tensor shape 一致,需在接口层面做广播(tbe.dsl.broadcast); - 类型/shape 校验:在算子接口函数中校验 dtype 与 shape 的合理性,尽早抛出错误;
- 效率技巧:对于最后一维为 1 的情况,可选择裁减为更小维度以提升调度效率(内存排布优势)。
3.3 关键代码结构(示例片段)
下列代码为简化示例,真实工程请参考完整验证与异常处理流程。
import tbe
from tbe import tvm
from tbe import dsl
from tbe.common.utils import shape_util
@tbe.common.register.register_op_compute("add", op_mode="static")
def add_compute(x1, x2, output, kernel_name="add"):
# 1. 计算广播后的shape
shape_x1 = shape_util.shape_to_list(x1.shape)
shape_x2 = shape_util.shape_to_list(x2.shape)
shape_x1, shape_x2, shape_max = shape_util.broadcast_shapes(shape_x1, shape_x2,
param_name_input1="x1",
param_name_input2="x2")
# 2. 做广播
x1_b = dsl.broadcast(x1, shape_max)
x2_b = dsl.broadcast(x2, shape_max)
# 3. 执行逐元素相加
res = dsl.vadd(x1_b, x2_b)
return res
def add(input_x, input_y, output_z, kernel_name="add"):
# placeholder 创建
dtype = input_x.get("dtype").lower()
shape_x = input_x.get("shape")
shape_y = input_y.get("shape")
data_x = tvm.placeholder(shape_x, name="data_1", dtype=dtype)
data_y = tvm.placeholder(shape_y, name="data_2", dtype=dtype)
res = add_compute(data_x, data_y, output_z, kernel_name)
with tvm.target.cce():
sch = dsl.auto_schedule(res)
config = {"name": kernel_name, "tensor_list": (data_x, data_y, res)}
dsl.build(sch, config)
if __name__ == "__main__":
sample = {"shape": (5,6,7), "format": "ND", "dtype":"float16"}
add(sample, sample, sample, kernel_name="add")
3.4 编译与验证
- 在算子文件末尾添加主函数后运行
python3 add.py进行语法与编译检查; - 编译成功后会在当前目录下生成
kernel_meta文件夹,包含add.o与add.json,说明算子已正确生成并可被上层模型加载。
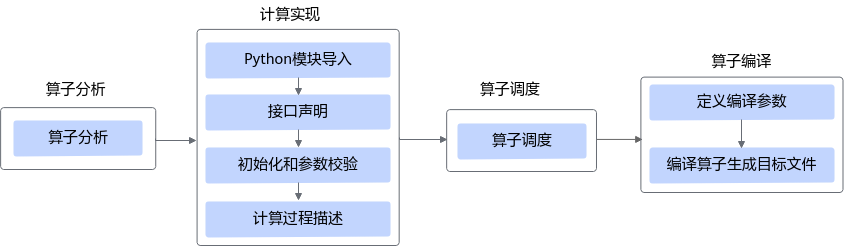
四、Auto Schedule 的原理与可视化理解
Auto Schedule 的核心工作流程可以抽象为:
- AST 标注(tag_scope):每个 compute 语句在编译时加上 tag,便于识别子图类型;
- Pattern 识别与子图切分:将整个 AST 切分成若干子图(pattern),例如 elewise、reduce、conv 等。不同 pattern 的组合规则有限制(例如 reduce 不能和 concat 在同一个子图内);
- 调度模板选择:对每个子图根据 pattern 选择合适的 schedule 模板(包含 tiling 策略、并行方式、缓存策略等);
- 调度生成 IR 并走后续优化 Pass:完成数据切块、数据流安排与指令映射。
对于开发者,这意味着:
- 如果你的算子属于常见 pattern(如 elementwise、reduce、conv),Auto Schedule 很可能给出高质量调度;
- 若算子属于非常规或复合 pattern,自动调度可能无法完全覆盖,你需要考虑重写算子为更易调度的子图或改用 TIK 进行手工优化。
五、性能与精度的工程化考量(实践技巧)
虽然 DSL + AutoSchedule 大幅简化流程,但在工程化场景中仍需关注下列点以保证性能与数值稳定性:
5.1 数据类型与数值稳定性
- 对于累加型 reduce 操作,优先考虑
float32或混合精度策略以避免float16下的溢出/精度损失; - 在需要精确数值的场景(归一化、指数等),可在 compute 层做分段计算或引入 safe guards(例如先做精度扩展,再做降低存储)。
5.2 减少冗余广播与数据拷贝
- 在接口层做形状规范化(尽量裁掉末尾为 1 的维度),避免在调度层产生不必要的 memory copy;
- 合理使用
broadcast只在必要时调用,尽量复用输入 tensor 的内存布局。
5.3 利用 pattern 编写“友好” compute
- Auto Schedule 对 pattern 识别敏感,按常见 pattern 组织 compute(把可并入的 elementwise 操作写成串联而非散乱的 compute)能提高调度质量;
- 对于可拆分为多个子图的复杂算子,设计良好的子图边界有助于模版匹配与性能提升。
5.4 控制内存占用
- 在算子接口中检查广播后整体元素数(shape_size)是否超过硬件限制,尽早错误提示;
- 在可能的情况下,采用 inplace 或累计写入减少峰值内存占用(需要保证计算语义正确)。
5.5 测试与基准
- 单元测试:对每个 dtype/format/shape 组合做覆盖的单元测试,包括边界 case(空维度、单维为1、巨大维度等);
- 性能基准:在目标硬件上使用代表性输入做基准测试(人脸识别、推荐排序中常见 BatchSize/shape),与已有实现比较,定位瓶颈(内存带宽、算力利用率、指令映射不佳等)。
六、常见问题与排错策略
6.1 编译失败或找不到 kernel_meta 文件
- 检查 Python 语法与导入路径;
- 确认
tbe环境与 TVM 目标tvm.target.cce()是否可用; - 观察编译日志中是否有未支持的 DSL 接口或类型不匹配的错误。
6.2 运行结果数值不对
- 先做纯 numpy 参考实现对比,排查广播或维度变换是否错误;
- 检查 dtype(特别是 float16 下的精度下降)是否是问题原因;
- 对 reduce/累加类算子,尝试用更高精度(float32)跑一遍看是否收敛或差异消失。
6.3 性能不如预期
- 查看 Auto Schedule 生成的 IR 或调度日志(若可得),判断是否生成了低效的 tile 或大量的内存拷贝;
- 检验数据布局(NCHW vs NC1HWC0 等)是否与硬件最优布局对齐;
- 若 Auto Schedule 无法满足,评估是否需要用 TIK 做关键 kernel 的手工优化。
七、什么时候应当放弃 DSL,转向更底层的 TIK?
TBE DSL 以易用性为导向,但并非万能。当出现以下场景,应考虑转用 TIK 或更底层实现:
- 需要对指令级或寄存器级的控制(例如手工映射特殊矩阵单元);
- 算子 pattern 极其特殊,Auto Schedule 无法给出有效的调度模板;
- 对 latency/throughput 有极端苛刻的 SLA,需做超越自动调度的手工优化;
- 需要实现硬件特殊特性(某些专用指令或原语),DSL 无访问路径。
在做决定前,建议先用 DSL 实现原型并基准,若性能差距超过可接受阈值再转 TIK,这样能节约开发成本并获得快速验证。
八、工程化清单:开发一个可维护的 DSL 算子需完成的事项
- 明确算子数学定义、输入输出规范(dtype、format、shape);
- 设计 input validation 与 shape broadcast 策略(把潜在错误早检测);
- 在 compute 函数中使用 DSL 接口实现计算逻辑(尽量组织成常见 pattern);
- 在接口函数中创建
tvm.placeholder,调用auto_schedule并dsl.build; - 实现单元测试与端到端验证(与 numpy/TF/PyTorch reference 对齐);
- 在目标硬件上做性能基准,记录结果与预期差距;
- 若必要,写 TIK 或 C++ 内核做关键路径优化,并与 DSL 版本做对比;
- 编写使用文档(参数说明、限制、示例)并纳入 CI 编译检查。
九、总结与实践建议
TBE DSL 为昇腾平台上的自定义算子开发提供了一条低成本、快速迭代的路径:开发者把精力放在计算逻辑与数值正确性上,Auto Schedule 负责把计算映射到硬件执行。对于大多数通用算子,DSL + Auto Schedule 能在短时间内交付功能完整且性能可接受的实现。
实战建议:
- 先用 DSL 快速原型并进行完整测试;只有在性能或特殊硬件需求明确时,才考虑迁移到更复杂的 TIK 实现;
- 在算子实现时,按照常见 pattern 组织 compute,这会显著提升自动调度的效果;
- 始终保持严格的 dtype 与 shape 校验,提前捕捉边界条件以减少运行时错误;
- 建立一套标准化的单元测试与性能基准流程,帮助在不同硬件/固件版本上追踪算子行为变化。
附录:实用片段 / 常用 DSL 接口速查
tbe.dsl.vadd(lhs, rhs)— 逐元素加(要求 shape 一致)tbe.dsl.broadcast(var, shape, output_dtype=None)— 广播 tensor 到指定 shapetbe.dsl.vexp(x)— 逐元素指数tbe.dsl.sum(x, axis=...)— reduce sumtbe.dsl.vrec(x)— 逐元素取倒数tbe.dsl.auto_schedule(res)— 触发自动调度,传入 compute 的输出 tensor(或 tensor tuple)tbe.dsl.build(schedule, config)— 根据 schedule 与配置生成算子目标文件与描述文件
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 14
14 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)