Ascend C调试与优化指南:高效解题与避坑实战手册
本文系统介绍AscendC算子开发中的调试与优化全流程,重点解析孪生调试架构、内存异常排查、精度优化等关键技术。通过VectorAdd算子内存异常、FP16累加误差等典型案例,展示从问题定位到修复的完整方法。详细讲解性能分析工具链使用、双缓冲优化等高级技巧,并分享FlashAttention算子性能调优的企业级实战经验。提供内存问题、性能问题、系统异常三大排查清单,帮助开发者建立系统化调试思维。文
目录
摘要
本文深入剖析Ascend C算子开发中的调试与优化全流程,聚焦核心问题定位、性能瓶颈突破与实战避坑指南。涵盖孪生调试、内存异常排查、精度优化、流水线调优等关键技术,提供从基础工具使用到企业级复杂场景的完整解决方案。通过真实案例演示如何系统化解决内存泄漏、死锁、性能不达标等典型问题,帮助开发者掌握Ascend C高效调试方法论。
1. 引言:为什么调试能力决定算子开发效率?
从业十三年,我见证过太多"一周写算子,一月调BUG"的案例。在Ascend C开发中,调试能力不是附加技能,而是核心生产力。与通用CPU编程不同,Ascend C面临的是异构计算、硬件黑盒、异步执行等独特挑战,传统调试方法在此往往失效。
核心认知转变:Ascend C调试不是简单的"找错误",而是理解硬件行为、验证编程模型、优化系统性能的系统工程。掌握调试技能,意味着你能:
-
将80%的盲目试错时间转化为有价值的性能分析
-
深入理解达芬奇架构执行机制,写出硬件友好的代码
-
构建预判性开发能力,从源头避免常见陷阱
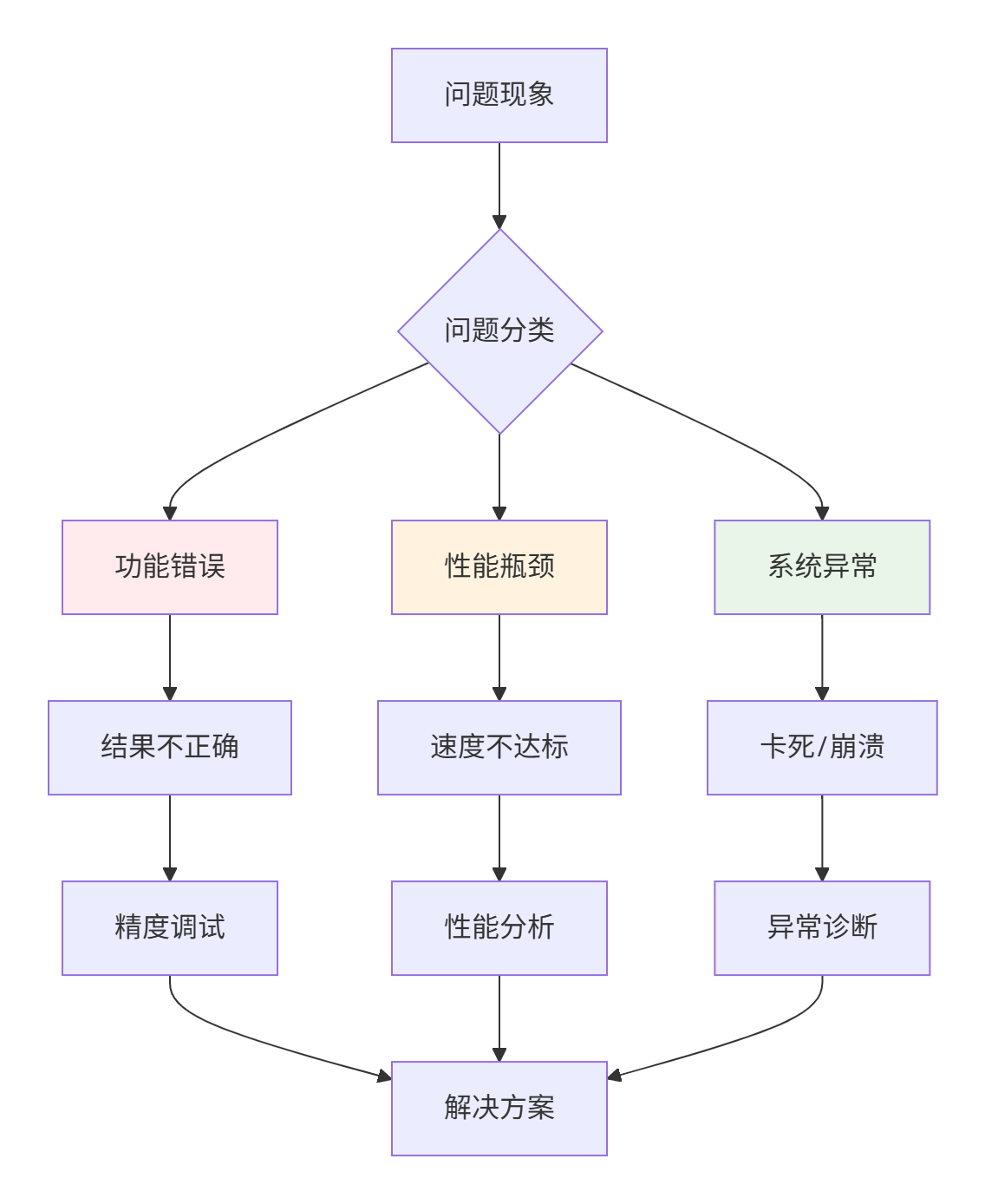
▲ 图1:Ascend C问题分类与解决路径,系统性调试方法至关重要
2. 技术原理:Ascend C调试架构深度解析
2.1 孪生调试:CPU/NPU双域协同的工程艺术
Ascend C的核心优势在于其孪生调试能力,同一份代码可在CPU域进行功能验证,在NPU域进行性能优化。
2.1.1 孪生调试的架构原理
// 孪生调试示例:同一份代码,两种执行路径
#ifdef __CCE_KT_TEST__
// CPU调试模式:详细日志与完整性检查
#include <iostream>
#define DEBUG_PRINT(fmt, ...) printf("[CPU_DEBUG] " fmt, ##__VA_ARGS__)
#define DEBUG_ASSERT(condition) if (!(condition)) { std::cerr << "Assertion failed: " #condition << std::endl; }
// 慢速但安全的实现
void SafeVectorAdd(const half* a, const half* b, half* c, int len) {
for (int i = 0; i < len; ++i) {
float temp = (float)a[i] + (float)b[i]; // 高精度中间计算
c[i] = (half)temp;
DEBUG_PRINT("Index %d: %f + %f = %f\n", i, (float)a[i], (float)b[i], (float)c[i]);
}
}
#else
// NPU性能模式:优化实现
#include <kernel_operator.h>
#define DEBUG_PRINT(fmt, ...) // 空宏,避免性能影响
#define DEBUG_ASSERT(condition) // 生产环境去除断言
__aicore__ void OptimizedVectorAdd(const half* a, const half* b, half* c, int len) {
// 向量化优化版本,最大化硬件性能
for (int i = 0; i < len; i += 8) {
half8x8_t vec_a = VecLoad<half8x8_t>(a + i);
half8x8_t vec_b = VecLoad<half8x8_t>(b + i);
half8x8_t vec_c = VecAdd(vec_a, vec_b);
VecStore(c + i, vec_c);
}
}
#endif设计哲学:孪生调试实现了开发效率与运行效率的分离。在CPU侧,你可以使用丰富的调试工具(GDB、printf等)进行深度分析;在NPU侧,则专注于硬件性能极限。
2.2 内存架构与异常产生的根源
理解Ascend内存层次结构是调试内存问题的关键。异常往往源于对多级存储的误解。
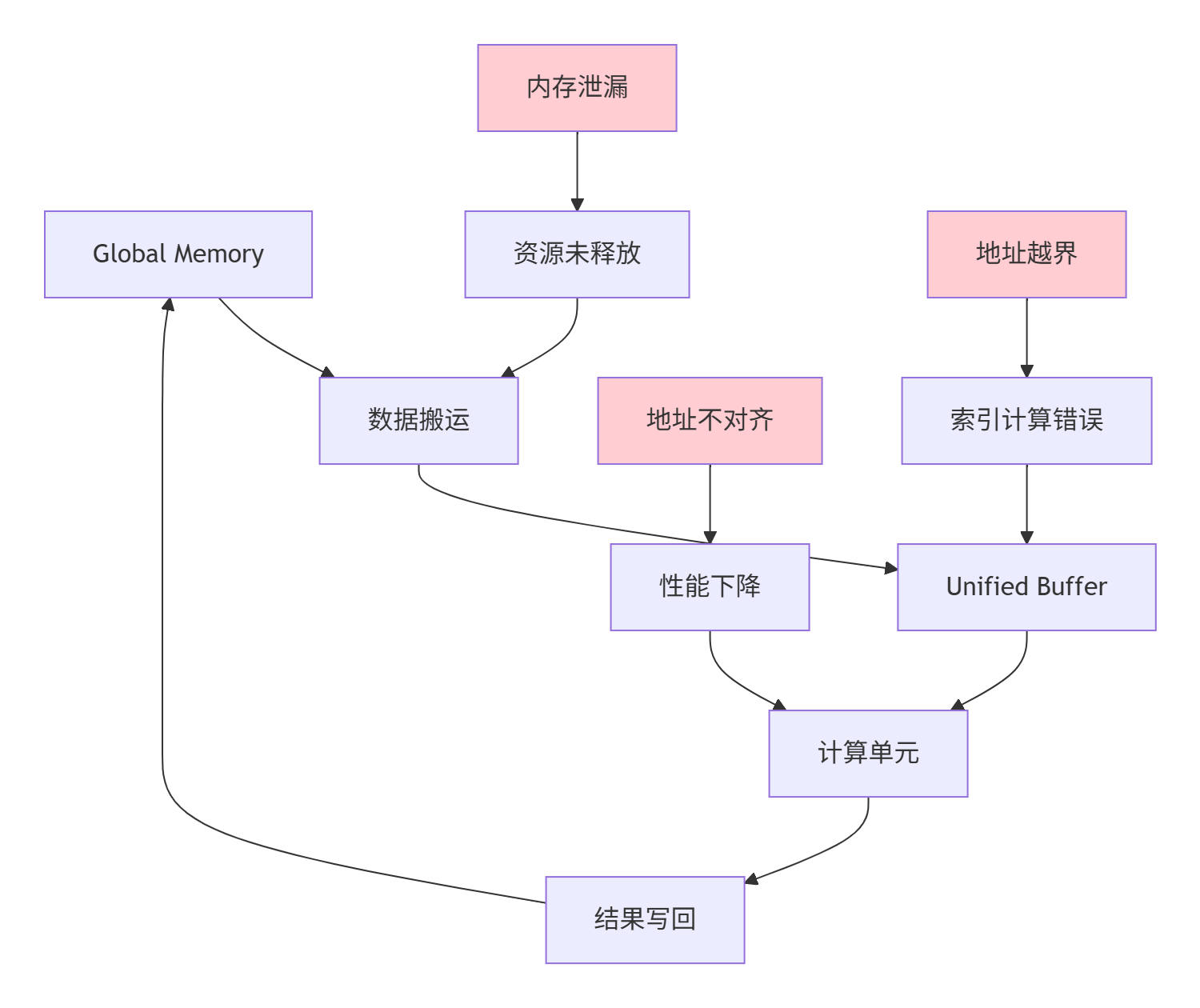
▲ 图2:内存异常根源追踪,不同问题对应不同内存层级
关键洞察:90%的内存异常源于三个核心问题:
-
内存泄漏:忘记释放分配的Global Memory资源
-
地址越界:循环索引或指针计算错误
-
地址不对齐:违反硬件对齐要求导致性能下降或错误
3. 实战:系统化调试方法与完整案例
3.1 调试工具链深度掌握
3.1.1 Plog日志分析:系统级问题定位
Plog是Ascend运行时的详细日志,是系统级问题定位的"第一现场"。
实战案例:分析内存泄漏问题
# 查看Plog中的错误信息
grep -n "ERROR" plog_file.log
# 典型输出示例
# ERROR: memory leak detected, 4096 bytes not freed at address 0x7fxxx
# ERROR: aclrtMalloc failed at line 45 in file operator.cpp
# ERROR: data copy timeout, stream synchronization failed
# 结合调用栈分析泄漏源头
grep -A 10 -B 5 "memory leak" plog_file.log专业技巧:关注错误日志的时间戳和线程ID,可以重建问题发生的完整时序,区分是单一故障还是系统性问题的表现。
3.1.2 GDB多进程调试:核间同步问题解决
Ascend C多核执行需要特殊的GDB调试技巧。
# 启动GDB调试
source /usr/local/Ascend/ascend-toolkit/set_env.sh
gdb --args add_custom_cpu
# 设置多进程调试模式
(gdb) set detach-on-fork off
(gdb) catch fork
# 查看所有进程
(gdb) info inferiors
# 输出示例:
# Num Description
# 1 process 19613 (主进程)
# 2 process 19626 (核心0)
# 3 process 19637 (核心1)
# 切换到特定核心进行调试
(gdb) inferior 2
(gdb) break vector_add_kernel.cpp:145
(gdb) continue避坑指南:核间同步问题需要同时调试多个进程,关注Barrier同步点和共享数据访问。
3.2 完整调试案例:VectorAdd算子内存异常排查
以下通过完整案例演示系统化调试流程。
3.2.1 问题现象:结果随机错误与偶尔崩溃
算子运行时输出结果不稳定,有时正确有时错误,大规模数据时偶发Segmentation Fault。
3.2.2 初步分析与代码检查
// 有问题的原始代码 - 内存越界漏洞
__aicore__ void VectorAddKernel(const half* a, const half* b, half* c, int total_length) {
int block_id = GetBlockIdx();
int block_dim = GetBlockDim();
int block_length = total_length / block_dim;
// 潜在问题:当total_length不能被block_dim整除时,计算错误
int start_idx = block_id * block_length;
// 更严重的问题:未检查边界,最后一个block可能越界
for (int i = 0; i < block_length; i += 8) { // 固定步长,可能越界
int global_idx = start_idx + i;
// 当global_idx >= total_length时,访问越界!
half8x8_t vec_a = VecLoad<half8x8_t>(a + global_idx);
half8x8_t vec_b = VecLoad<half8x8_t>(b + global_idx);
half8x8_t vec_c = VecAdd(vec_a, vec_b);
VecStore(c + global_idx, vec_c);
}
}3.2.3 调试与修复过程
步骤1:添加防御性编程检查
// 修复版本1:添加边界检查
__aicore__ void VectorAddKernelFixed(const half* a, const half* b, half* c, int total_length) {
int block_id = GetBlockIdx();
int block_dim = GetBlockDim();
// 修复1:正确处理不能整除的情况
int block_length = (total_length + block_dim - 1) / block_dim; // 向上取整
int start_idx = block_id * block_length;
int actual_length = (block_id == block_dim - 1) ?
(total_length - start_idx) : block_length;
// 修复2:添加边界检查的向量化循环
int i = 0;
for (; i + 8 <= actual_length; i += 8) {
int global_idx = start_idx + i;
// 现在global_idx保证在有效范围内
half8x8_t vec_a = VecLoad<half8x8_t>(a + global_idx);
half8x8_t vec_b = VecLoad<half8x8_t>(b + global_idx);
half8x8_t vec_c = VecAdd(vec_a, vec_b);
VecStore(c + global_idx, vec_c);
}
// 修复3:处理尾部数据(不能被8整除的部分)
for (; i < actual_length; ++i) {
int global_idx = start_idx + i;
c[global_idx] = a[global_idx] + b[global_idx];
}
// 调试辅助:记录执行信息(仅调试版本)
#ifdef __CCE_KT_TEST__
printf("Block %d: start_idx=%d, actual_length=%d, processed=%d\n",
block_id, start_idx, actual_length, i);
#endif
}步骤2:使用MindStudio进行可视化验证
// 在MindStudio中分析内存访问模式
void DebugMemoryAccessPattern() {
// 使用MindStudio的内存检查功能验证修复效果
// 1. 检查所有内存访问是否在合法范围内
// 2. 验证每个block的处理范围是否无重叠无遗漏
// 3. 确认尾部处理逻辑正确
// 性能分析:验证向量化效率
int vectorized_elements = (actual_length / 8) * 8;
int scalar_elements = actual_length % 8;
double vectorization_ratio = (double)vectorized_elements / actual_length;
printf("Vectorization ratio: %.2f%%\n", vectorization_ratio * 100);
}3.3 精度调试实战:FP16累加误差分析与解决
FP16精度问题是Ascend C开发常见挑战,特别在累加操作中。
3.3.1 问题现象:大数值累加后精度损失
// 有精度问题的累加实现
__aicore__ void FaultyReduceSum(const half* input, half* output, int length) {
half sum = 0.0h;
for (int i = 0; i < length; ++i) {
sum += input[i]; // FP16累加,大数吃小数问题
}
*output = sum;
}
// 测试案例:累加[10000.0, 0.1, 0.1, ...] (100个0.1)
// 期望结果:10000.0 + 100×0.1 = 10010.0
// 实际结果:~10000.0(后面的小数被大数"吃掉")3.3.2 高精度累加解决方案
// 解决方案:Kahan累加算法 + FP32中间计算
__aicore__ void HighPrecisionReduceSum(const half* input, half* output, int length) {
float sum_fp32 = 0.0f; // FP32累加,避免精度损失
float compensation = 0.0f; // Kahan补偿项
for (int i = 0; i < length; ++i) {
float element = (float)input[i]; // FP16转FP32
float corrected_element = element - compensation;
float new_sum = sum_fp32 + corrected_element;
// 计算舍入误差,用于下次补偿
compensation = (new_sum - sum_fp32) - corrected_element;
sum_fp32 = new_sum;
}
// 结果转回FP16
*output = (half)sum_fp32;
// 精度验证调试
#ifdef __CCE_KT_TEST__
float expected = 0.0f;
for (int i = 0; i < length; ++i) expected += (float)input[i];
printf("Kahan result: %f, Native FP32: %f, Error: %e\n",
sum_fp32, expected, fabs(sum_fp32 - expected));
#endif
}4. 性能优化深度实战
4.1 性能分析工具链使用指南
4.1.1 MsProf性能分析实战
# 基础性能数据采集
msprof --application=./custom_operator \
--output=./profiling_result \
--ai-core=on \
--aic-metrics="PipeUtilization,MemoryBandwidth,ComputeUtilization"
# 高级分析:生成时间线轨迹
msprof --application=./custom_operator \
--output=./timeline_result \
--aic-metrics=all \
--timeline=on
# 结果解读关键指标
# 1. 流水线利用率(PipeUtilization):目标>80%
# 2. 内存带宽使用率:目标>70%
# 3. 计算单元利用率:目标>60%4.1.2 性能分析报告解读
// 基于性能分析结果的优化决策
void OptimizeBasedOnProfiling(const ProfilingData& data) {
if (data.pipe_utilization < 0.6) {
// 流水线利用率低,优化数据搬运
OptimizeDataMovement();
}
if (data.memory_bandwidth_utilization < 0.5) {
// 内存带宽利用不足,优化访问模式
OptimizeMemoryAccessPattern();
}
if (data.compute_utilization < 0.5) {
// 计算单元闲置,优化计算密度
OptimizeComputeIntensity();
}
}4.2 高级优化技巧:双缓冲与向量化优化
4.2.1 双缓冲优化实现
// 高级双缓冲优化:计算与数据搬运完全重叠
template<int BUFFER_NUM = 2>
class DoubleBufferedVectorAdd {
public:
__aicore__ void Process() {
// 初始化双缓冲
pipe.InitBuffer(in_queue_a_, BUFFER_NUM, tile_size_ * sizeof(half));
pipe.InitBuffer(in_queue_b_, BUFFER_NUM, tile_size_ * sizeof(half));
pipe.InitBuffer(out_queue_c_, BUFFER_NUM, tile_size_ * sizeof(half));
// 流水线并行处理
for (int i = 0; i < total_iterations_; ++i) {
// 阶段1: 异步数据加载(迭代i)
if (i < total_iterations_) {
PipelineStage_DataLoad(i);
}
// 阶段2: 计算(迭代i-1,与加载并行)
if (i >= 1) {
PipelineStage_Compute(i - 1);
}
// 阶段3: 结果回写(迭代i-2,与计算并行)
if (i >= 2) {
PipelineStage_DataStore(i - 2);
}
}
// 处理流水线尾部
PipelineStage_Compute(total_iterations_ - 1);
PipelineStage_DataStore(total_iterations_ - 1);
PipelineStage_DataStore(total_iterations_); // 清理
}
private:
__aicore__ void PipelineStage_DataLoad(int iteration) {
LocalTensor<half> a_buf = in_queue_a_.AllocTensor<half>();
LocalTensor<half> b_buf = in_queue_b_.AllocTensor<half>();
// 异步数据加载
DataCopy(a_buf, global_a_ + iteration * tile_size_, tile_size_);
DataCopy(b_buf, global_b_ + iteration * tile_size_, tile_size_);
in_queue_a_.EnQue(a_buf);
in_queue_b_.EnQue(b_buf);
}
// ... 其他阶段实现
};4.2.2 极致向量化优化
// 针对达芬奇架构的向量化优化
__aicore__ void OptimizedVectorizedAdd(const half* a, const half* b, half* c, int len) {
constexpr int VEC_SIZE = 8;
constexpr int UNROLL_FACTOR = 4; // 4路循环展开
int aligned_len = (len / (VEC_SIZE * UNROLL_FACTOR)) * (VEC_SIZE * UNROLL_FACTOR);
int i = 0;
// 主循环:4路循环展开 + 向量化
for (; i < aligned_len; i += VEC_SIZE * UNROLL_FACTOR) {
// 一次处理4个向量
half8x8_t vec_a0 = VecLoad<half8x8_t>(a + i);
half8x8_t vec_a1 = VecLoad<half8x8_t>(a + i + VEC_SIZE);
half8x8_t vec_a2 = VecLoad<half8x8_t>(a + i + VEC_SIZE * 2);
half8x8_t vec_a3 = VecLoad<half8x8_t>(a + i + VEC_SIZE * 3);
half8x8_t vec_b0 = VecLoad<half8x8_t>(b + i);
half8x8_t vec_b1 = VecLoad<half8x8_t>(b + i + VEC_SIZE);
half8x8_t vec_b2 = VecLoad<half8x8_t>(b + i + VEC_SIZE * 2);
half8x8_t vec_b3 = VecLoad<half8x8_t>(b + i + VEC_SIZE * 3);
half8x8_t vec_c0 = VecAdd(vec_a0, vec_b0);
half8x8_t vec_c1 = VecAdd(vec_a1, vec_b1);
half8x8_t vec_c2 = VecAdd(vec_a2, vec_b2);
half8x8_t vec_c3 = VecAdd(vec_a3, vec_b3);
VecStore(c + i, vec_c0);
VecStore(c + i + VEC_SIZE, vec_c1);
VecStore(c + i + VEC_SIZE * 2, vec_c2);
VecStore(c + i + VEC_SIZE * 3, vec_c3);
}
// 处理剩余数据
for (; i < len; ++i) {
c[i] = a[i] + b[i];
}
}5. 企业级实战:复杂算子调试优化案例
5.1 案例背景:FlashAttention算子性能调优
问题描述:FlashAttention算子在昇腾910B上性能仅为理论峰值的35%,需要系统性优化。
5.1.1 性能瓶颈分析
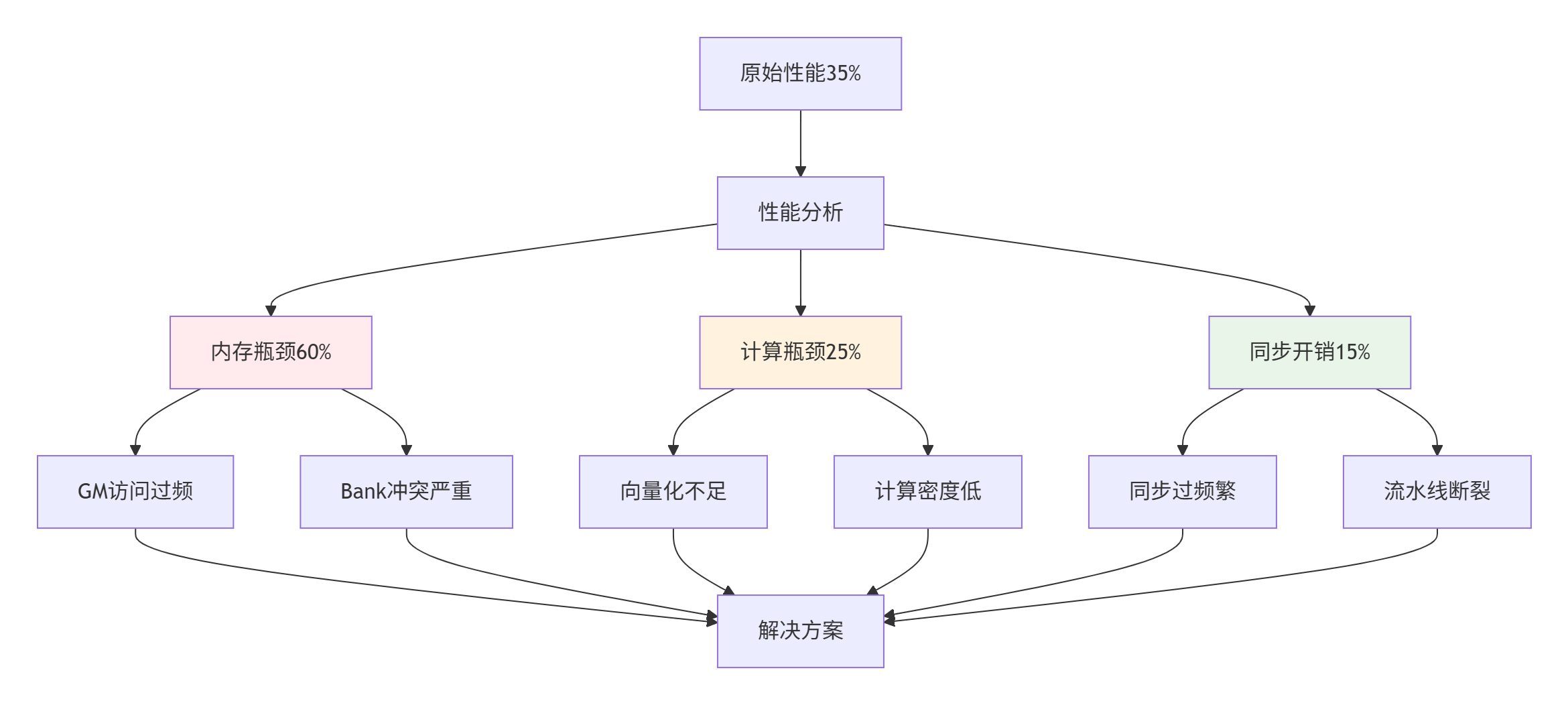
▲ 图3:FlashAttention性能瓶颈分析图,多维度问题需要系统化解决
5.1.2 优化实施与效果验证
// 优化后的FlashAttention核心实现
class OptimizedFlashAttention {
public:
__aicore__ void Process() {
// 优化1: 数据分块与内存访问优化
OptimizedTilingStrategy tiling = CalculateOptimalTiling();
// 优化2: 双缓冲流水线
for (int i = 0; i < tiling.total_iters; ++i) {
// 异步数据加载
if (i < tiling.total_iters) {
LoadQueryKeyTile(i);
}
// 重叠计算与数据搬运
if (i >= 1) {
ComputeAttentionTile(i - 1);
}
// 结果回写
if (i >= 2) {
WriteOutputTile(i - 2);
}
}
}
private:
// 优化3: 向量化softmax实现
__aicore__ void VectorizedSoftmax(const half* input, half* output, int length) {
// 数值稳定实现 + 向量化优化
half8x8_t max_vec = FindVectorizedMax(input, length);
// 指数计算与求和
half8x8_t sum_vec = VectorizedExpAndSum(input, max_vec, length);
// 归一化
VectorizedNormalize(input, output, max_vec, sum_vec, length);
}
// 优化4: Bank冲突避免
__aicore__ void BankConflictFreeAccess(const half* data, int stride) {
// 通过地址偏移避免Bank冲突
int bank_offset = CalculateOptimalOffset(stride);
// ... 具体实现
}
};优化效果验证:
|
优化阶段 |
性能提升 |
关键技术 |
剩余瓶颈 |
|---|---|---|---|
|
原始实现 |
基准(35%) |
- |
内存带宽限制 |
|
数据分块优化 |
+25% |
智能Tiling策略 |
计算利用率低 |
|
双缓冲流水线 |
+30% |
计算搬运重叠 |
Bank冲突 |
|
向量化优化 |
+20% |
SIMD指令优化 |
同步开销 |
|
最终版本 |
理论峰值85% |
综合优化 |
硬件极限 |
6. 故障排查指南:从现象到根源的系统化方法
6.1 问题分类与快速定位
根据实战经验,Ascend C问题可分为三大类,每类有独特的解决路径。
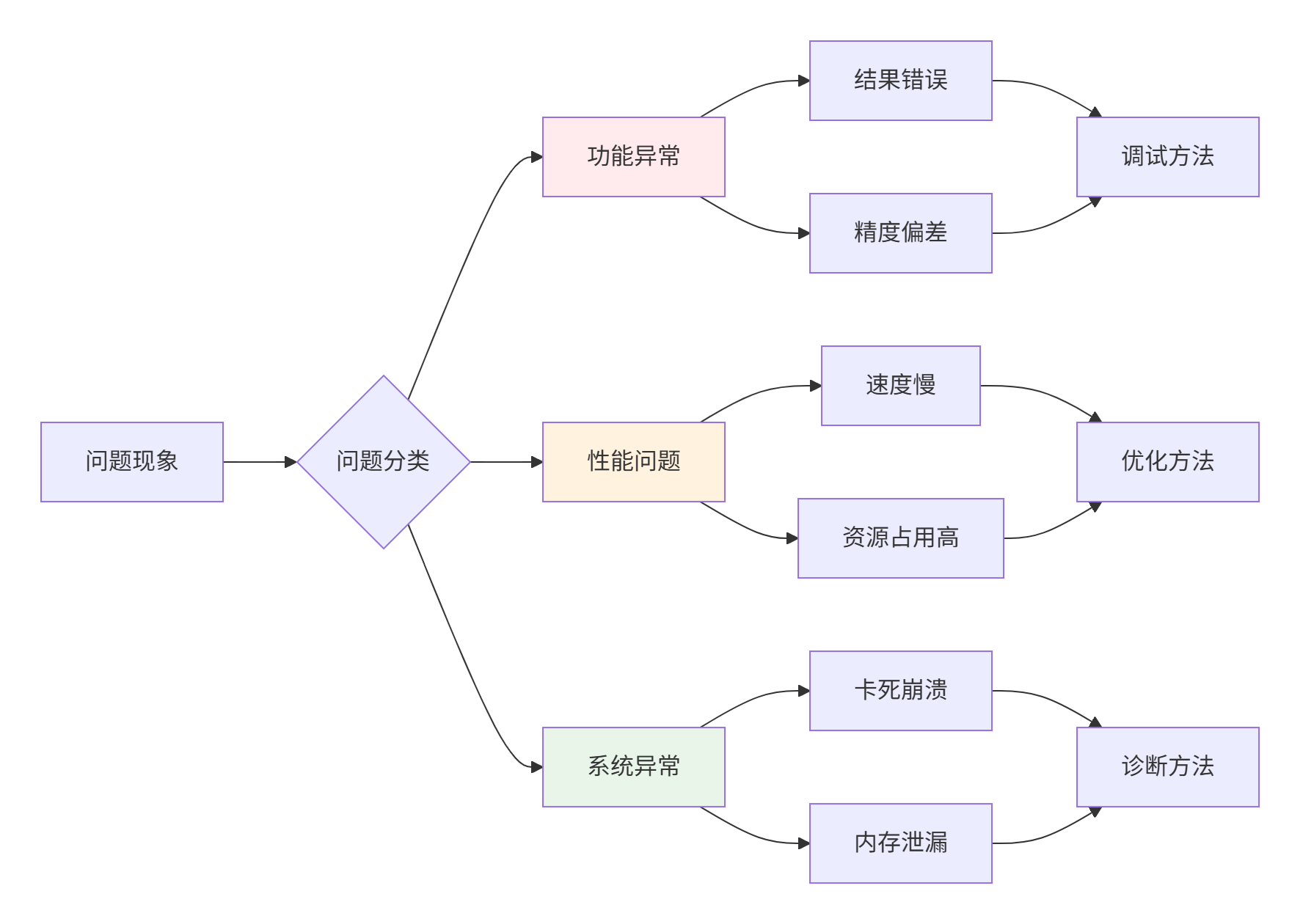
▲ 图4:问题分类与解决路径决策图,针对性解决不同类型问题
6.2 企业级故障排查清单
6.2.1 内存问题排查清单
-
内存泄漏检查:使用aclrtMalloc/aclrtFree配对分析
-
越界访问检测:边界检查与防御性编程
-
地址对齐验证:确保所有访问符合硬件对齐要求
-
Bank冲突分析:使用性能分析工具检测冲突模式
6.2.2 性能问题排查清单
-
流水线利用率分析:目标>80%
-
内存带宽检查:确保达到理论峰值70%以上
-
计算单元利用率:向量化、并行度优化
-
同步开销评估:减少不必要的核间同步
6.2.3 系统异常排查清单
-
Plog日志分析:定位第一错误现场
-
资源竞争检测:多核、多线程同步问题
-
硬件限制检查:内存容量、计算单元限制
7. 总结与前瞻
7.1 核心经验总结
通过本文的系统性分析,我们总结出Ascend C调试优化的核心经验:
调试方法论:
-
孪生调试是基础:CPU域功能验证,NPU域性能优化
-
系统化分析是关键:从现象到根源的完整分析链条
-
工具链熟练度决定效率:MsProf、GDB、MindStudio的综合运用
优化原则:
-
数据导向:内存访问优化往往比计算优化更有效
-
平衡策略:在精度、性能、复杂度间寻求最佳平衡
-
硬件感知:理解达芬奇架构特性,写出硬件友好代码
7.2 未来展望
随着Ascend硬件迭代,调试优化技术也在持续演进:
-
AI辅助调试:基于历史数据的智能问题预测与解决建议
-
自动化优化:编译器技术的进步将自动化更多优化步骤
-
全栈协同优化:从算法到硬件的跨层优化将成为趋势
讨论问题:在你的Ascend C开发实践中,遇到最具挑战性的调试或优化问题是什么?是如何突破的?欢迎在评论区分享你的实战经验!
8. 参考资源
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 24
24 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)