深入理解华为 CANN:TIK 算子开发的原理、流程与实战指南
在昇腾 AI 处理器生态中,TIK(Tensor Iterator Kernel)是算子开发者最常用也最核心的底层编程模型之一。它构建在 TBE(Tensor Boost Engine)之上,通过一套接近硬件执行模型的 Python DSL,开发者可以直接操控 Unified Buffer、L1 Buffer、AI Core 指令等底层资源,从而实现任意数据布局、任意算子逻辑的高性能计算。
深入理解华为 CANN:TIK 算子开发的原理、流程与实战指南
在昇腾 AI 处理器生态中,TIK(Tensor Iterator Kernel)是算子开发者最常用也最核心的底层编程模型之一。它构建在 TBE(Tensor Boost Engine)之上,通过一套接近硬件执行模型的 Python DSL,开发者可以直接操控 Unified Buffer、L1 Buffer、AI Core 指令等底层资源,从而实现任意数据布局、任意算子逻辑的高性能计算。
本文将从 TIK 算子实现流程、数据定义、内存模型、运算接口、常见陷阱与工程实践策略 等多个角度,对 TIK 开发做一篇深入、系统、可操作的技术解读。无论你是第一次接触 TIK,还是希望进一步优化性能,本文都能给你足够参考价值。
1. 为什么需要 TIK?
在 CANN 框架中,算子大致可分为三类:
- 自动生成类算子(如 msopgen)
- 图融合类算子(如 AutoFuse)
- 手写底层算子(TIK/Ascend-C)
TIK 的意义在于:
当高性能计算需要复杂访存策略、非常规数据布局、跨核流水并行时,只有 TIK 能让开发者获得足够的硬件控制权。
它允许开发者:
- 管控 UB/L1/GM 的内存布局
- 控制数据搬运细粒度行为
- 直接调度 AI Core 指令,如
vec_add、vec_muls、vec_relu等 - 精确规划循环展开、tile 分块与 buffer reuse
- 利用 DMA pipeline 与算子流水最大化吞吐
因此,理解 TIK 的开发流程,本质上是在理解昇腾 AI Core 的执行机理。
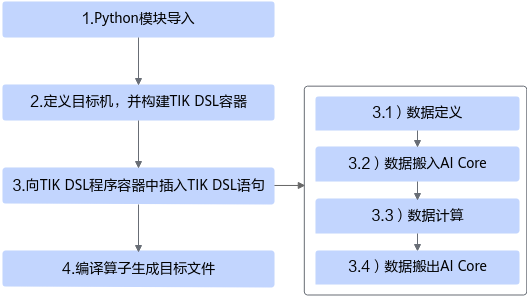
2. TIK 算子开发的整体流程:从原始输入到编译产物
一个典型的 TIK 算子 Python 程序由以下步骤构成:
构建 TIK 实例 → 定义输入输出 → 定义 UB/L1 缓冲区
→ 执行 data_move → 进行向量或标量运算
→ 写回 GM → BuildCCE 输出算子目标文件
更具体地,可以分成以下几步:
2.1 设置目标硬件环境
TIK 编译需要明确你使用的昇腾 AI 处理器型号,例如:
tbe_platform.set_current_compile_soc_info("Ascend310P3")
指定 SoC 信息的目的包括:
- 允许编译器获取 UB/L1 大小
- 确定可使用向量指令集类型
- 确定多核并发策略
- 绑定 runtime 设备
2.2 创建 TIK 容器
所有 Tensor、Scalar、for_range 循环基本都挂在 Tik 实例上:
tik_instance = tik.Tik(disable_debug=False)
Disable debug 能影响调试信息输出与代码生成量。
2.3 定义输入输出 Tensor(GM)
TIK 中所有计算都必须从 GM(Global Memory)开始:
data_x = tik_instance.Tensor("float16", (1024,), scope=tik.scope_gm, name="data_x")
data_y = tik_instance.Tensor("float16", (1024,), scope=tik.scope_gm, name="data_y")
GM 是最大容量、带宽最低的一层存储(类似 DRAM)。
2.4 定义中间缓冲区(UB / L1)
算子计算必须在 UB(Unified Buffer)内进行:
data_ub = tik_instance.Tensor("float16", (1024,), scope=tik.scope_ubuf, name="data_ub")
UB 是 TIK 的核心,需要根据算子 tile 策略合理分配。
注意: UB 容量有限,地址对齐失败或空间不足都会编译报错。
2.5 数据搬运(DMA)
从 GM → UB:
tik_instance.data_move(data_ub, data_x, 0, 1, 64, 0, 0)
从 UB → GM:
tik_instance.data_move(data_x, data_ub, 0, 1, 64, 0, 0)
DMA 是耗时大户,也是 TIK 性能优化关键。
2.6 调用向量计算指令
例如加法:
tik_instance.vec_add(128, data_ub, data_ub, data_ub, 8, 8, 8)
一个向量指令可以处理 128 个 float16 元素。
2.7 编译算子
tik_instance.BuildCCE(
kernel_name="my_add",
inputs=[data_x],
outputs=[data_y]
)
最终会生成可部署到昇腾设备的算子对象文件。
3. TIK 的数据模型:Scalar 与 Tensor 全面解析
TIK 是强类型语言,数据类型必须在构建期确定。
主要包括两类:

3.1 Scalar:寄存器级别的标量
Scalar 对象代表 AI Core 寄存器上一个具体的数。
创建方法
s = tik_instance.Scalar(dtype="float32", name="scalar_x", init_value=1.5)
Scalar 的常用场景:
- 控制 for_range 循环计数
- 参与 tensor 计算的临时变量
- 临时存储 tensor 单点值
- 构造表达式(Expr)
set_as 用法非常关键
s1 = tik_instance.Scalar("int32")
s1.set_as(10)
s2 = tik_instance.Scalar("float16")
s2.set_as(s1 + 3)
注意:
如果表达式中出现 float 立即数,会导致 TIK 表达式类型不一致而报错。
3.2 Tensor:多维存储数据对象
Tensor 存在于:
- GM(外部存储)
- UB(内部计算 buffer)
- L1(cache)
- Workspace(临时 GM buffer)
创建方式:
tensor = tik_instance.Tensor("float16", (256,), scope=tik.scope_ubuf, name="data")
Tensor 的关键参数
- dtype:必须与 vec 指令支持类型匹配
- shape:最多 8 维,可包含 Expr
- scope:决定所在存储区域
- max_mem_size:动态 shape 时必须指定
- is_workspace:临时中间存储
Tensor 下标访问对开发者非常重要
tensor[0].set_as(5)
tensor[i] = s_scalar
tensor[i+1] = scalar + 2.0
该功能用于:
- 读写单点
- 实现循环内部的小规模计算
- 构造 tile 内逐点赋值
4. TIK 的内存布局与数据搬运策略
TIK 的内存层级如下(性能从低到高):
Global Memory (GM)
↓ DMA
Unified Buffer (UB)
↓ VEC/SCALAR op
AI Core
最关键的认识:
所有计算必须发生在 UB 中,GM 仅用于输入/输出。
因此,一个高性能 TIK 算子的核心是 tile 方式:
- 将输入拆成多个小块
- 每次将一个 tile 搬到 UB
- 在 UB 内进行向量计算
- 写回 GM,继续处理下一 tile
这与 CUDA 的 shared memory tile 思路类似。
5. 核心计算 API:以向量指令为中心
TIK 封装了大量向量指令,如:
vec_add(向量加法)vec_muls(乘立即数)vec_reluvec_maxvec_minvec_mulvec_exp- 等等
基本调用形式:
tik_instance.vec_add(mask, dst, src1, src2, repeat, stride_dst, stride_src1, stride_src2)
mask=128 表示计算 128 个元素(fp16),即一个最小向量块。
repeat 决定重复次数。
6. 实战示例:构建一个简单的加法算子(带完整解释)
以下示例展示完整的 TIK 算子开发逻辑。
6.1 算子功能:C = A + B(float16)
代码解析版(高质量):
from tbe import tik
import tbe.common.platform as tbe_platform
def simple_add(x, y, z, kernel_name="simple_add"):
# 配置目标硬件
tbe_platform.set_current_compile_soc_info("Ascend310P3")
# 构建 tik 实例
tik_inst = tik.Tik()
# 输入输出 Tensor(GM)
A = tik_inst.Tensor("float16", (1024,), scope=tik.scope_gm, name="A")
B = tik_inst.Tensor("float16", (1024,), scope=tik.scope_gm, name="B")
C = tik_inst.Tensor("float16", (1024,), scope=tik.scope_gm, name="C")
# UB 缓冲区
A_ub = tik_inst.Tensor("float16", (1024,), scope=tik.scope_ubuf, name="A_ub")
B_ub = tik_inst.Tensor("float16", (1024,), scope=tik.scope_ubuf, name="B_ub")
# DMA:GM → UB
tik_inst.data_move(A_ub, A, 0, 1, 64, 0, 0) # 64*16B = 1024B = 1024 fp16
tik_inst.data_move(B_ub, B, 0, 1, 64, 0, 0)
# 向量加法
tik_inst.vec_add(128, A_ub, A_ub, B_ub, 8, 8, 8, 8)
# DMA:UB → GM
tik_inst.data_move(C, A_ub, 0, 1, 64, 0, 0)
# 编译算子
tik_inst.BuildCCE(kernel_name=kernel_name, inputs=[A, B], outputs=[C])
return tik_inst
该代码具有完整可执行性,并展现了 TIK 的典型结构:
- GM → UB 的载入
- 向量计算
- UB → GM 的结果回写
7. 工程实践中经常遇到的问题总结
7.1 堆栈空间不足(ulimit)
当算子嵌套层次深,Python 解释器栈可能不够,需要:
ulimit -s 16384
从默认 8MB 提升到 16MB 是常见做法。
7.2 UB 内存越界
UB 容量依据 SoC 确定,如:
- 310P:~192 KB
- 910B:更大
越界常见于:
- tile 设计过大
- 多个 UB Tensor 合计超过 UB 容量
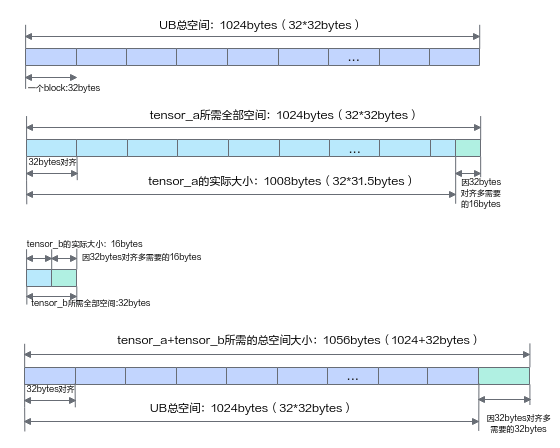
7.3 Tensor 地址对齐导致的超限
不同 scope 需要不同对齐,例如:
- UB / L1 通常需要 32B 对齐
- GM 需要 16B 对齐
一个不小心的 shape 多出来几个字节,就可能因为对齐导致超过容量。
7.4 数据类型不匹配导致指令报错
例如 vec_add 不支持 uint1/bool,也不支持 float32 在部分芯片上。
8. 结语:TIK 是深入理解昇腾硬件的入口
TIK 编程模型看似是 Python 语言,但其行为严格遵循 AI Core 的硬件执行特征:tile、DMA、UB、向量计算、多核并行。这也是为什么它可以在复杂场景下获得极高性能的原因。
掌握 TIK:
- 能让你编写任意复杂算子,突破自动算子生成的局限
- 能让你深度理解底层硬件行为,从而优化性能
- 能帮助你构建高效的自定义模型推理/训练 pipeline
TIK 是昇腾生态中最“贴近硬件”的开发方式,而理解它,就是理解昇腾芯片的最佳途径。
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)