深入理解华为 CANN TIK:面向算子开发者的动态编程框架解析
在昇腾 AI 处理器生态中,算子是模型执行性能的最小基本单元。如何让算子既具备可控性,又能充分释放硬件的潜能,是算子开发者必须解决的核心问题。TIK(Tensor Iterator Kernel)正是在这样的背景下应运而生——它以 Python 的灵活性为入口,通过 DSL 编译体系连接到底层的 CCE 编译器,将高层描述转化为适配昇腾 AI Core 的高效二进制代码。
深入理解华为 CANN TIK:面向算子开发者的动态编程框架解析
在昇腾 AI 处理器生态中,算子是模型执行性能的最小基本单元。如何让算子既具备可控性,又能充分释放硬件的潜能,是算子开发者必须解决的核心问题。TIK(Tensor Iterator Kernel)正是在这样的背景下应运而生——它以 Python 的灵活性为入口,通过 DSL 编译体系连接到底层的 CCE 编译器,将高层描述转化为适配昇腾 AI Core 的高效二进制代码。
在本文中,我们将从 TIK 的设计理念、编程模型、典型开发流程,到一个可运行的算子示例,系统性展开介绍,帮助你从架构到代码全面掌握 TIK 的开发方式。
一、TIK:让算子开发更“像写程序”而不是“写配置”
传统的 AI 加速算子开发往往需要直接面向底层编程模型,开发者需要细致处理多级存储、手动调度数据搬运、显式地为向量单元布置计算任务。TIK 的出现,改变了这种“繁琐门槛高”的开发方式。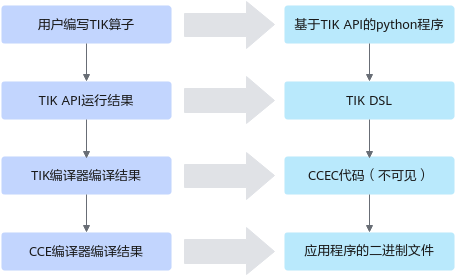
1. DSL 驱动的动态算子框架
TIK 本质上是一个 Python 模块,但它背后是一套完整的 DSL(领域专用语言)与编译链体系。TIK 程序通过 API 构建抽象的计算图,描述数据管理、算子调度与计算逻辑。最终交由 TIK 编译器和 CCE 编译器完成二级编译流程:
- Python → TIK DSL
- TIK DSL → CCEC 中间代码
- CCEC → AI Core 可执行二进制 (o 文件)
开发者可以完全不关心底层指令级细节,专注于计算本身——这是 TIK 的核心改变。
2. 四大关键优势
TIK 带来的效率提升主要来自以下几个维度:
① 自动并行化
开发者以“串行思维”写程序,由 TIK 工具链自动翻译并行任务,实现 AI Core 硬件级并行调度。
② 自动内存管理
传统的 CCE 代码需要手动管理 GM → UB → L1 → Vector 的缓存和生命周期,而 TIK 屏蔽了绝大部分复杂性,让开发者像写 Python 一样定义 Tensor。
③ 灵活的手动调度能力
对于需要极致性能的场景,开发者仍然可以显式控制数据流、循环拆分、流水线等调度手段——自动与手动并存,这对于性能调优至关重要。
④ 原生可调试性
TIK 内置 Debug 环境(tikdb),支持:
- 单步执行
- 查看 UB / GM 数据
- Hook 流程
这种“白盒调试”能力,在其他算子开发方式中极为稀缺。
二、从 TIK 到 AI Core:一个清晰的编程模型
TIK 的编程模型可以理解为一个“高抽象 → 中间描述 → 可执行代码”的逐级下沉过程。
开发者主要与以下三部分交互:
-
TIK API:Python 代码层
定义 Tensor、描述调度、调用向量计算接口。 -
编译生成 CCEC 中间代码
开发者不可见,属于 TIK 体系内部处理。 -
CCE 编译器生成 .o 及 .json
.o:真正运行在 AI Core 的核代码.json:算子的元信息
从用户角度看,整个过程几乎是无感的——写 Python,就能生成可执行算子。
三、示例:从零编写一个 Add 算子
为了直观展示 TIK 的开发流程,我们以最简单的 Add 算子为例。算子的功能如下:
输入
x1, x2的 shape 都为 (128,) 且 dtype 为 float16
输出y = x1 + x2
虽然简单,但它包含了 TIK 典型开发中的所有关键步骤。
四、算子设计分析:从数学表达式到调度流程
尽管 Add 的数学定义非常简单,但算子开发需要系统性分析:数据、格式、调度、接口、命名等。
1. 输入输出定义
| 字段 | x1 | x2 | y |
|---|---|---|---|
| shape | (128,) | (128,) | (128,) |
| dtype | float16 | float16 | float16 |
| format | NCHW / NHWC / ND… | 同左 | 同左 |
需要注意:
- TIK 开发对 format 不敏感,因为所有计算最终都展开到 Tensor 本身。
- dtype 与 shape 可以支持动态,但入门示例中采用固定值。
2. 调度流程设计(重点)
Add 的调度分为四步:
① 从 GM 分配输入输出 Tensor
外部存储(Global Memory)
② 在 UB 中分配中间缓冲区
内部存储(Unified Buffer)
③ 数据搬运 GM → UB
因为 128 × 2 bytes = 256 bytes
远小于 UB 的容量,一次搬运即可。
④ 调用向量计算接口 vec_add
一次最多计算 256 bytes
本例刚好 Fits in one instruction。
整个流程不需要循环或分块,是最典型的简单算子结构。
3. 算子命名规则
算子类型:AddTik
文件与函数名:add_tik
采用默认规则:
- 首字母:大写转小写
- 大写 →
_+ 小写
因此 AddTik → add_tik
五、完整 TIK 代码实现(可直接运行)
这是完全按照开发规范重写的版本,结构更清晰,更适合作为博客示例。
from tbe import tik
import tbe.common.platform as tbe_platform
import numpy as np
def add_tik():
"""
使用 TIK 实现 Add 算子:y = x1 + x2
输入 shape 固定为 (128,), dtype 为 float16
"""
# 1. 设置编译目标
soc_version = "Ascend310P"
tbe_platform.set_current_compile_soc_info(soc_version)
# 2. 创建 TIK 实例(开启调试)
tik_instance = tik.Tik(disable_debug=False)
# 3. 定义 GM Tensor:外部存储
data_A = tik_instance.Tensor("float16", (128,), name="data_A", scope=tik.scope_gm)
data_B = tik_instance.Tensor("float16", (128,), name="data_B", scope=tik.scope_gm)
data_C = tik_instance.Tensor("float16", (128,), name="data_C", scope=tik.scope_gm)
# 4. 定义 UB Tensor:内部存储
data_A_ub = tik_instance.Tensor("float16", (128,), name="data_A_ub", scope=tik.scope_ubuf)
data_B_ub = tik_instance.Tensor("float16", (128,), name="data_B_ub", scope=tik.scope_ubuf)
data_C_ub = tik_instance.Tensor("float16", (128,), name="data_C_ub", scope=tik.scope_ubuf)
# 5. GM → UB:数据搬运
burst_len = 128 * 2 // 32
tik_instance.data_move(data_A_ub, data_A, 0, 1, burst_len, 0, 0)
tik_instance.data_move(data_B_ub, data_B, 0, 1, burst_len, 0, 0)
# 6. Vector 加法计算
tik_instance.vec_add(128, data_C_ub[0], data_A_ub[0], data_B_ub[0], 1, 8, 8, 8)
# 7. UB → GM:写回结果
tik_instance.data_move(data_C, data_C_ub, 0, 1, burst_len, 0, 0)
# 8. 编译生成 CCE 可执行文件
tik_instance.BuildCCE(
kernel_name="simple_add",
inputs=[data_A, data_B],
outputs=[data_C]
)
return tik_instance
# ----------------- 功能调试 -----------------
if __name__ == "__main__":
tik_instance = add_tik()
data = np.ones((128,), dtype=np.float16)
feed_dict = {"data_A": data, "data_B": data}
# 启动调试器
data_C, = tik_instance.tikdb.start_debug(feed_dict=feed_dict, interactive=True)
print(data_C)
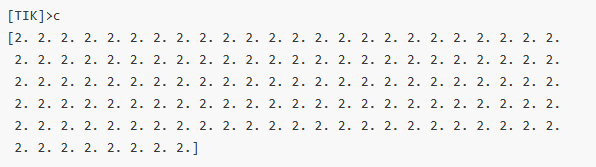
六、调试:TIK 最好用的能力之一
执行:
python3 add_tik.py
在 tikdb 中:
[TIK]> c
即可看到输出全为 2。
七、从示例总结 TIK 开发的核心思想
通过 Add 示例我们可以抽象出 TIK 开发的核心方法论:
-
Tensor 是算子的基本资源
GM(外部)与 UB(内部)需要清晰区分。 -
所有计算都基于向量接口
如 vec_add、vec_mul、data_move 等。 -
思考调度比写计算更重要
什么时候搬运?多少数据?如何分块?如何复用? -
TIK 的 Python 写法只是入口
真正执行的是底层 CCE 指令。 -
Debug 模式是性能与正确性的关键工具
能打印 UB 数据,是性能调优阶段的神器。
八、结语:TIK 是昇腾算子开发的必经之路
TIK 并不是一个“写 Python 算子”的工具,而是一个“使用 Python 来描述底层算子行为”的 DSL 框架。它既具备:
- Python 的高抽象
- 又能深入控制底层调度
- 自动并行化与自动内存管理降低了开发门槛
- 优秀的调试体验提升了开发效率
对于希望在昇腾平台上实现高性能算子的开发者而言,理解并掌握 TIK 是迈向生态深度开发的关键一步。
若你计划开发更复杂的算子(如卷积、Reduce、Softmax 等),那么 Add 的示例是最好的起点。
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 17
17 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)