异构计算的另一极:昇腾CANN中的AI CPU算子开发实战
在昇腾CANN算子开发的旅程中,我们的目光往往聚焦于AI Core(Da Vinci核心)的极致性能——我们学习Tiling、流水线、向量化,旨在榨干其强大的张量计算能力。将AI Core的性能优化技艺与AI CPU的灵活编程能力相结合,你将成为一名能够驾驭整个异构计算平台的、真正的全栈AI系统工程师。它让我们明白,昇腾NPU的强大,不仅在于AI Core的磅礴算力,更在于异构单元之间协同工作的智
前言
在昇腾CANN算子开发的旅程中,我们的目光往往聚焦于AI Core(Da Vinci核心)的极致性能——我们学习Tiling、流水线、向量化,旨在榨干其强大的张量计算能力。然而,一个完整的AI模型,并非仅由密集的卷积和矩阵乘法构成。其中常常穿插着各种逻辑复杂、数据依赖不规则、甚至包含动态形状(Dynamic Shape)的“异类”算子。
对于这些算子,强行让为大规模并行设计的AI Core去处理,就像让一辆F1赛车去跑崎岖的越野赛道——不仅跑不快,还可能“损坏”性能。这正是异构计算的智慧所在:为不同的任务,匹配最适合的计算单元。
本文将带你探索昇ENG NPU的另一极——AI CPU。我们将深入探讨AI CPU算子的适用场景,解析其与TBE算子截然不同的开发范式,并以一个极具代表性的MaskedSelect算子为例,从零开始,手把手教你如何为板载的ARM核心编写一个高效、并行的C-++核函数。掌握这项技能,你将能够驾驭整个昇腾异构平台,应对更广泛、更复杂的AI计算挑战。
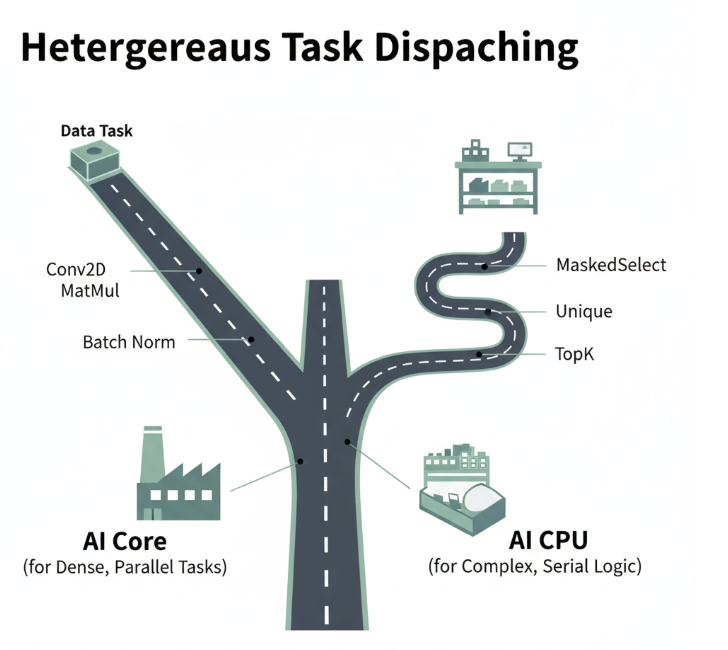
第一章:异构分工:为何需要AI CPU算子?
理解“为何”,是掌握“如何”的前提。AI Core和AI CPU在设计哲学上有着根本的不同,决定了它们的“天职”。
-
AI Core的“天职”:大规模、规则、并行计算
- 优势: 拥有海量计算单元,擅长执行结构化、数据依赖简单的计算,如矩阵乘法、卷积、向量运算。其性能的发挥,高度依赖于数据的批量化和计算模式的可预测性。
- 劣势: 对复杂的控制流(如大量的if-else)、不规则的内存访问、数据依赖驱动的计算(Data-dependent Computation)非常不友好,会导致大量的硬件空闲和流水线中断。
-
AI CPU的“天职”:复杂逻辑、不规则、串行/小规模并行
- 优势: 本质是高性能的ARM CPU核心,拥有复杂的流水线、分支预测器和多级缓存。它天生擅长处理:
- 复杂的控制逻辑: 大量的条件判断、循环。
- 动态形状推断: 输出形状依赖于输入数据的算子,如
Unique、NonZero以及本文的MaskedSelect。 - 稀疏或不规则数据访问: 需要根据索引进行Gather/Scatter类操作。
- 需要调用OS或复杂库函数的任务。
- 优势: 本质是高性能的ARM CPU核心,拥有复杂的流水线、分支预测器和多级缓存。它天生擅长处理:
结论: AI Core是“计算兵团”,负责正面战场的冲锋;而AI CPU则是“特种部队”,负责处理复杂、精细、非结构化的特种任务。两者协同,才能发挥整个NPU的最高效能。
第二章:AI CPU算子的解剖学
AI CPU算子的开发流程与TBE算子相似(都需要原型定义、编译等),但其核心的核函数(Kernel)实现却有天壤之别。
与TBE算子的核心区别:
- 编程语言: 不再是特化的Ascend C,而是标准的原生C++。你可以使用STL、C++11/14的各种特性。
- 内存模型: 没有
Local Memory的概念。 AI CPU直接在全局内存(HBM)上进行操作,但它拥有自己的多级缓存(L1/L2 Cache)。因此,优化的重点从手动管理Local Memory,转变为编写**CPU缓存友好(Cache-friendly)**的代码。 - 执行模型: 不再是
GetBlockIdx()驱动的SPMD大规模并行,而是更传统的多线程并行。CANN为此提供了简单易用的并行库。 - Tiling: 不再是为了适配
Local Memory而进行的手动Tiling,而是为了将大任务分解给多个CPU核心而进行的逻辑上的任务划分。
第三章:实战演练 —— 从零实现一个并行的MaskedSelect算子
MaskedSelect算子的功能是:根据一个布尔类型的mask张量,从input张量中挑选出对应位置为True的元素,并将其紧凑地排列成一个新的输出张量。其输出的长度是动态的、不确定的。
3.1 步骤一:原型定义 (masked_select.proto)
op_name: "MaskedSelect"
input_desc {
name: "input"
type: "all" // 支持多种数据类型
}
input_desc {
name: "mask"
type: "bool"
}
output_desc {
name: "output"
type: "all"
}
3.2 步骤二:核函数实现 (masked_select.cc)
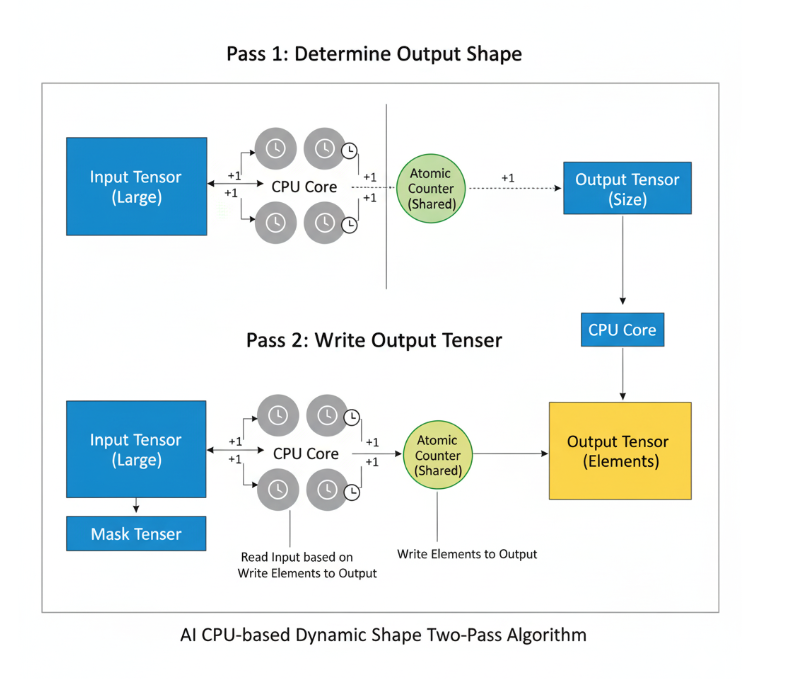
这是核心。由于输出大小不确定,我们通常采用一个**两阶段(Two-pass)**算法。
#include "cpu_kernel_utils.h" // 引入CANN提供的CPU核函数工具库
#include <atomic>
using namespace aicpu;
// 核函数的主体
uint32_t MaskedSelectKernel(CpuKernelContext &ctx) {
// 1. 获取输入输出Tensor对象
Tensor *input = ctx.Input(0);
Tensor *mask = ctx.Input(1);
Tensor *output = ctx.Output(0);
// 2. 获取数据指针和总元素数
auto input_ptr = reinterpret_cast<float *>(input->GetData()); // 假设是float类型
auto mask_ptr = reinterpret_cast<bool *>(mask->GetData());
int64_t total_elements = input->NumElements();
// --- 第一阶段 (Pass 1): 并行计算输出元素的总数 ---
std::atomic<int64_t> output_count(0);
// 使用CANN提供的并行for循环工具
CpuKernelUtils::ParallelFor(ctx, total_elements, 1, [&](int64_t start, int64_t end) {
int64_t local_count = 0;
for (int64_t i = start; i < end; ++i) {
if (mask_ptr[i]) {
local_count++;
}
}
output_count += local_count;
});
// 3. 动态设置输出的Shape
// Pass 1结束后,output_count就是输出张量的长度
std::vector<int64_t> output_shape = {output_count};
output->SetShape(dims_to_shape(output_shape));
auto output_ptr = reinterpret_cast<float *>(output->GetData());
// --- 第二阶段 (Pass 2): 并行地将数据拷贝到输出 ---
std::atomic<int64_t> current_pos(0);
CpuKernelUtils::ParallelFor(ctx, total_elements, 1, [&](int64_t start, int64_t end) {
// 创建一个临时本地缓冲区
std::vector<float> local_buffer;
for (int64_t i = start; i < end; ++i) {
if (mask_ptr[i]) {
local_buffer.push_back(input_ptr[i]);
}
}
if (!local_buffer.empty()) {
// 原子地获取写入位置,并拷贝数据
int64_t write_pos = current_pos.fetch_add(local_buffer.size());
memcpy(output_ptr + write_pos, local_buffer.data(), local_buffer.size() * sizeof(float));
}
});
return KERNEL_STATUS_OK;
}
// 注册算子和核函数
REGISTER_CPU_KERNEL("MaskedSelect", MaskedSelectKernel);
代码解读:
CpuKernelUtils::ParallelFor: 这是CANN为AI CPU算子提供的并行化“神器”。它能自动将一个大的循环任务,拆分给多个CPU核心去执行,你只需要提供一个处理单个区间的lambda函数即可。std::atomic: 在并行计算中,多个线程需要更新同一个全局计数器(如output_count),必须使用原子操作来保证线程安全。- 动态Shape: 在第一阶段计算出确切的输出大小后,我们调用
output->SetShape()来动态地设定输出张量的形状。这是AI CPU算子处理动态性的关键。 - 两阶段算法: 这是解决“写位置不确定”的并行问题的经典模式。第一阶段确定“坑”位总数,第二阶段并行地“填坑”。
3.3 步骤三:实现InferShape函数
由于输出形状在编译期无法确定,我们需要在Host侧的算子实现文件(op_proto/masked_select.cpp)中,实现一个InferShape函数,告知图引擎(GE)这个事实。
// op_proto/masked_select.cpp
IMPLEMT_COMMON_INFERFUNC(MaskedSelectInferShape) {
// 告知框架,输出的shape是未知的,需要在运行时确定
op.GetOutputDesc(0).SetShape(Shape({UNKNOWN_RANK}));
return GRAPH_SUCCESS;
}
第四章:性能考量与最佳实践
编写功能正确的AI CPU算子只是第一步,要让它跑得快,还需要遵循CPU编程的优化法则。
-
提升CPU缓存命中率:
- 数据局部性: 确保并行任务访问的数据在内存中是连续的。
ParallelFor的区间划分正是基于此。 - 避免伪共享(False Sharing): 在并行更新数据时,要小心多个CPU核心修改位于同一个缓存行(Cache Line)的不同数据,这会导致缓存行在多核间失效,性能急剧下降。
- 数据局部性: 确保并行任务访问的数据在内存中是连续的。
-
选择合适的并行粒度:
在ParallelFor中,每个任务处理的数据量(粒度)需要权衡。粒度太小,线程创建和调度的开销会超过计算本身;粒度太大,可能导致任务分配不均,部分核心提前完成而空闲。通常需要根据计算的复杂度进行经验性的调整。 -
利用SIMD(NEON指令集):
对于更极致的性能追求者,可以像在任何ARM CPU上编程一样,使用NEON intrinsics(内建函数)来编写SIMD(单指令多数据流)代码,实现数据级的并行。例如,一次性比较4个或8个布尔值。
结论:成为全栈异构计算专家
AI CPU算子开发,为我们打开了CANN世界的另一扇大门。它让我们明白,昇腾NPU的强大,不仅在于AI Core的磅礴算力,更在于异构单元之间协同工作的智慧。
掌握AI CPU算子开发,意味着你不再局限于处理规整的张量计算。你获得了处理复杂逻辑、动态形状和不规则数据的能力,能够应对AI模型中那些最“棘手”的角落。将AI Core的性能优化技艺与AI CPU的灵活编程能力相结合,你将成为一名能够驾驭整个异构计算平台的、真正的全栈AI系统工程师。
从“专科”到“全科”的进阶之路:
这种异构开发的全局视野和实践能力,正是2025年昇腾CANN训练营第二季所倡导的。
- 系统化课程: 从AI Core到AI CPU,覆盖完整的开发场景。
- 官方技术支持与社区: 让你在探索异构编程时,总能找到指引。
- 权威技能认证: Ascend C中级认证,是你全面掌握昇腾开发能力的有力证明。
- 丰富的实践激励: 完成任务更有机会赢取华为手机、平板、开发板等大奖。
如果你渴望突破单一计算单元的局限,成为一名通晓全局的异构计算专家,那么,现在就是启程的最佳时机。
报名链接: https://www.hiascend.com/developer/activities/cann20252

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐


 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)