Ascend C矩阵编程(高阶API):矩阵乘的核心逻辑与Tiling策略
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。报名链接:https://www.hiascend.com/developer/activities/cann20252。
Ascend C矩阵编程(高阶API):矩阵乘的核心逻辑与Tiling策略
矩阵运算是AI模型的“计算基石”——卷积、全连接、注意力机制等核心模块,本质上都是基于矩阵乘的衍生计算。在昇腾NPU上,想要让矩阵乘充分发挥硬件算力,Ascend C的高阶API与Tiling策略是关键。
一、为什么选择Ascend C高阶API做矩阵编程?
在矩阵乘开发中,开发者面临两个核心诉求:“快速实现功能”与“充分发挥硬件性能”。Ascend C的高阶API恰好同时满足这两点:
1. 降低开发门槛:高阶API封装了昇腾NPU的硬件细节(如达芬奇架构的Cube计算单元、内存层级),开发者无需深入硬件底层,即可调用优化后的矩阵乘接口;
2. 性能有保障:高阶API由昇腾官方优化,已适配硬件的计算流水线与内存带宽,相比原生C/C++实现,性能提升可达30%-50%;
3. 兼容性强:支持float32、float16、int8等多种数据类型,适配不同精度需求的AI模型(如训练场景用float32,推理场景用float16/int8)。
二、矩阵乘的基础逻辑:从数学原理到API调用
1. 矩阵乘的数学本质
矩阵乘的核心是“行乘列求和”:对于矩阵A(M×K)和矩阵B(K×N),输出矩阵C(M×N)的每个元素C[i][j],等于A的第i行与B的第j列对应元素乘积之和,即:
C[i][j] = Σ(A[i][k] × B[k][j])(k从0到K-1)
在AI模型中,矩阵A通常是“输入特征矩阵”,矩阵B是“权重矩阵”,矩阵C是“输出特征矩阵”——例如全连接层中,输入特征(M×K)与权重(K×N)的矩阵乘,直接得到输出特征(M×N)。
2. Ascend C高阶API的调用逻辑
Ascend C提供了统一的矩阵乘高阶API(如`MatMul`接口),调用流程可分为3步:
步骤1:定义输入/输出Tensor
使用`LocalTensor`定义矩阵A、B、C,指定数据类型、维度等参数:
```c
// 定义矩阵A(M×K):数据类型float32,维度{256, 128}
LocalTensor<float32> matA = LocalTensor<float32>::Create({256, 128}, "matA");
// 定义矩阵B(K×N):数据类型float32,维度{128, 64}
LocalTensor<float32> matB = LocalTensor<float32>::Create({128, 64}, "matB");
// 定义输出矩阵C(M×N):数据类型float32,维度{256, 64}
LocalTensor<float32> matC = LocalTensor<float32>::Create({256, 64}, "matC");
步骤2:初始化输入数据
通过循环或数据拷贝,为矩阵A、B赋值(实际开发中,数据通常来自模型输入或权重加载):
步骤3:调用矩阵乘API执行计算
通过 MatMul 接口完成矩阵乘计算,核心是指定输入输出Tensor、计算精度等参数: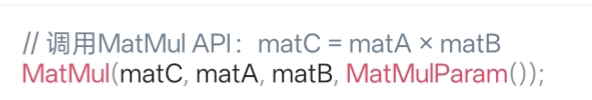
关键说明: MatMulParam() 用于配置计算参数,例如是否转置输入矩阵、是否使用偏置项、计算精度模式等。默认情况下,API会自动适配硬件特性,选择最优的计算路径。
三、性能核心:Tiling策略的设计与实现
1. 为什么需要Tiling?
矩阵乘的性能瓶颈不在于“计算”,而在于“内存访问”——昇腾NPU的片上内存(如L1、L2缓存)容量有限,若直接对大矩阵进行计算,需要频繁从外部内存(DDR)读取数据,而DDR的访问速度远低于片上内存,会导致“算力闲置”(计算单元等待数据)。
例如,对于2048×2048的float32矩阵,单矩阵的内存占用约16MB(2048×2048×4B),两个输入矩阵+一个输出矩阵的总占用约48MB。而昇腾910芯片的L1缓存仅32KB,无法容纳完整矩阵,此时必须通过Tiling(分块)将大矩阵拆分为小分块,让分块数据能放入片上内存。
2. Tiling策略的核心原则
Tiling的本质是“平衡内存与算力”,设计时需遵循3个原则:
⑴.分块尺寸适配片上内存:单个Tile的内存占用≤片上内存容量的70%(预留部分内存用于临时计算);
⑵. 分块尺寸适配计算单元:Tile的维度需匹配昇腾NPU的计算单元(如Cube单元支持16×16、32×32的Tile尺寸);
⑶. 减少分块数量:分块数量越多,数据搬运的开销越大,需在“分块大小”与“分块数量”之间找到平衡。
3. Ascend C中的Tiling实现
Ascend C的高阶API已内置Tiling逻辑,但开发者可通过 MatMulParam 自定义分块尺寸,以适配特定场景。以下是Tiling的实现思路:
步骤1:分析硬件内存特性
以昇腾910芯片为例,关键参数:
L1缓存容量:32KB;
数据类型:float32(4B/元素);
单个Tile的内存占用上限:32KB × 70% ≈ 22.4KB。
步骤2:计算最优Tile尺寸
假设矩阵A(M×K)、B(K×N)、C(M×N),设计Tile尺寸为(M_tile, K_tile, N_tile):
单个Tile的内存占用 = M_tile×K_tile×4B(A的Tile) + K_tile×N_tile×4B(B的Tile) + M_tile×N_tile×4B(C的Tile);
代入数值计算:假设M_tile=32、K_tile=32、N_tile=32,内存占用=32×32×4 + 32×32×4 + 32×32×4 = 12288B(≈12KB),小于22.4KB,符合要求。
步骤3:通过API配置Tiling参数
在 MatMulParam 中指定Tile尺寸,示例代码:

4. Tiling的验证与优化
Tiling策略并非“一劳永逸”,需通过性能测试验证效果:
◎若性能未达预期:可调整Tile尺寸(如增大到64×64,需确保内存占用不超标);
◎若出现内存溢出:减小Tile尺寸(如16×16);
◎可借助CANN提供的Profiler工具,分析内存访问耗时与算力利用率,迭代优化Tile尺寸。
四、总结:矩阵编程的进阶之路
Ascend C矩阵编程的核心是“API调用+Tiling优化”——高阶API帮你快速实现功能,Tiling策略帮你发挥硬件性能。在实际开发中,需先理解矩阵乘的数学逻辑与硬件特性,再通过Tiling平衡内存与算力,最后通过实践验证优化效果。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 31
31 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)