# 解码昇腾AI处理器:从达芬奇架构到智能调优的全栈优化之道
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。报名链接:https://www.hiascend.com/developer/activities/cann20252。以BERT为
## **一、引言:AI算力的“摩尔定律”困境与昇腾的破局之路**
随着大模型时代的到来,深度学习模型的参数量已从亿级跃升至千亿甚至万亿级别(如GPT-3、盘古大模型等),对算力的需求呈指数级增长。然而,传统GPU架构在算力密度、能效比和内存带宽上的瓶颈日益凸显——**“算得快,搬得慢”** 成为制约AI训练效率的核心矛盾。
在此背景下,华为推出基于**达芬奇3D Cube架构**的昇腾AI处理器系列(如昇腾910、昇腾310),以“硬件可编程 + 软件定义”的全栈协同设计理念,构建面向AI训练与推理的端到端解决方案。昇腾不仅追求峰值算力的突破,更注重**实际模型性能的转化效率**,通过一系列底层技术创新,显著提升了硬件利用率与系统能效。
本文将结合官方技术文档与实测数据,深入剖析昇腾处理器的四大核心技术创新,解析其背后的底层逻辑,并探讨其在典型AI模型(如ResNet50、BERT)中的应用成效,为AI开发者提供性能调优的新视角与实践路径。
## **二、昇腾处理器的四大核心技术突破**
### **2.1 自动流水技术:打破指令依赖的“并行革命”**
#### **传统架构的瓶颈:流水线“气泡”问题**
在传统AI芯片中,计算单元通常采用顺序执行的流水线机制。当后续指令依赖前序指令的输出结果时,必须等待数据就绪,导致流水线出现“气泡”(Bubble)——即无效的空转周期。这不仅浪费了宝贵的计算资源,还严重限制了硬件利用率。
例如,在执行向量加法(VADD)后立即进行矩阵乘法(MatMul)时,若MatMul依赖VADD的结果,则必须等待数据从内存回写并加载完成,造成数个周期的停顿。
#### **昇腾的解决方案:软件模拟Issue Queue + 自动乱序调度**
昇腾处理器通过**软件模拟的指令发射队列(Issue Queue)机制**,实现了类似CPU乱序执行的能力,但专为AI负载优化:
- **跨流水线依赖分析**:自动识别不同计算单元(如向量计算流水线 `PIPE_VEXC`、矩阵计算流水线 `PIPE_EXC`)之间的数据依赖关系;
- **无依赖指令并行发射**:将无数据依赖的指令提前调度至空闲计算单元,实现多流水线并行执行;
- **跨环预取机制**:在编译阶段分析多层循环结构,提前预取下一轮迭代所需的数据搬运指令,隐藏内存访问延迟。
> **📊 性能收益实测**:在ResNet50训练任务中,自动流水技术使融合算子的并行度提升20%,硬件利用率从70%提升至接近理论峰值的92%以上。
这一机制相当于为AI芯片引入了“智能交通调度系统”,让计算任务像车辆一样在不同车道上高效通行,避免拥堵。
### **2.2 算子深度融合:从“碎片化计算”到“一体化执行”**
#### **问题根源:小算子链导致的性能损耗**
现代深度学习模型(尤其是Transformer类模型)由大量细粒度算子构成。以BERT的Attention模块为例,原始计算图包含超过10个独立算子:`MatMul → Softmax → Dropout → Add → LayerNorm` 等。频繁的中间结果读写导致:
- 大量片外内存访问(HBM带宽瓶颈)
- 冗余的数据搬运与缓存开销
- 启动开销累积(每个算子都有调度延迟)
据实测统计,此类“小算子链”在GPU上仅能实现约40%的理论算力利用率。
#### **昇腾的应对策略:算子融合引擎**
昇腾通过**编译器级的算子深度融合技术**,将多个连续算子合并为一个高效内核(Kernel Fusion),实现“一次加载、全程计算”:
| 融合策略 | 典型组合 | 性能收益 |
|--------|--------|--------|
| 自动融合规则 | `MatMul + Softmax + Add` | 减少70%数据搬运 |
| 用户自定义融合 | `Conv + BN + ReLU`(ResNet场景) | 提升计算密度至90%+ |
| 动态图支持 | 支持PyTorch动态图融合 | 兼容灵活性与性能 |
> **🔍 案例分析:BERT训练加速50%**
>
> - 融合前:12个小算子 → 每步需访问HBM 6次
> - 融合后:3个大算子(QKV生成、Attention核心、输出融合)→ HBM访问降至2次
> - 实测结果:训练吞吐提升50%,功耗降低18%
该技术本质是**用空间换时间**:通过增加编译复杂度,换取运行时的极致效率。
---
### **2.3 自适应梯度切分:千卡集群下的通信优化秘钥**
#### **分布式训练的“阿喀琉斯之踵”:梯度同步开销**
在大规模分布式训练中,参数服务器或AllReduce通信成为性能瓶颈。尤其在千卡以上集群中,梯度同步时间常常超过计算时间,形成“算得越快,等得越久”的怪圈。
传统做法采用固定粒度切分(如按Tensor切分),难以适应不同模型结构与网络拓扑。
#### **昇腾创新:优先级拖尾算法 + 动态切分粒度**
昇腾提出**自适应梯度切分技术**,核心思想是:
- **通信-计算重叠最大化**:将大梯度张量按重要性分级,优先传输关键梯度(如主干网络权重);
- **动态粒度调整**:根据当前网络带宽、延迟与计算负载,实时调整切分块大小;
- **异步流水线调度**:在通信过程中继续执行下一轮前向传播的部分计算。
> **⚡ 实测表现**:
>
> - 在千卡集群训练ResNet50时,梯度同步时间从100ms压缩至10ms;
> - 通信开销占比从35%降至4%,接近理论最优性能;
> - 训练效率提升90%,实现线性加速比的近似保持。
这项技术使得昇腾在超大规模训练场景下具备显著优势,尤其适用于千亿参数大模型的训练。
### **2.4 智能计算调优AOE:300+模型的“一键优化”引擎**
#### **挑战:手动调优成本高昂且难以泛化**
面对CV、NLP、推荐系统等多样化模型,开发者需反复尝试混合精度、算子融合、内存复用、梯度累积等策略组合,耗时耗力。
#### **昇腾答案:AI for AI —— AOE智能调优引擎**
昇腾推出的**Ascend Optimizing Engine(AOE)** 是一个基于知识库与自动化搜索的智能调优系统:
| 功能模块 | 描述 |
|--------|------|
| **预置优化策略库** | 内置300+主流模型的优化配置(如ResNet50的FP16+Loss Scaling、BERT的梯度累积步数=8) |
| **结构感知匹配** | 自动识别模型拓扑(如是否有Attention、残差连接),推荐最优策略 |
| **自动化搜索** | 支持贝叶斯优化、强化学习等算法,在超参空间中快速收敛至高性能配置 |
| **零代码介入** | 用户仅需启用`aoe_enable=True`,即可获得接近专家级的手动调优效果 |
> **🚀 性能实测:ResNet50训练提速30%**
>
> - 基线配置:纯FP32,无融合,标准梯度同步 → 1500 images/sec
> - AOE推荐配置:FP16混合精度 + 算子融合 + 梯度切分 → **1950 images/sec**
> - 开发者无需修改一行代码,即可享受性能红利
AOE的本质是将**专家经验产品化、调优过程自动化**,极大降低了AI部署门槛。
---
## **三、硬件基石:达芬奇3D Cube架构深度解析**
### **3.1 架构设计理念:计算-内存-通信三位一体协同**
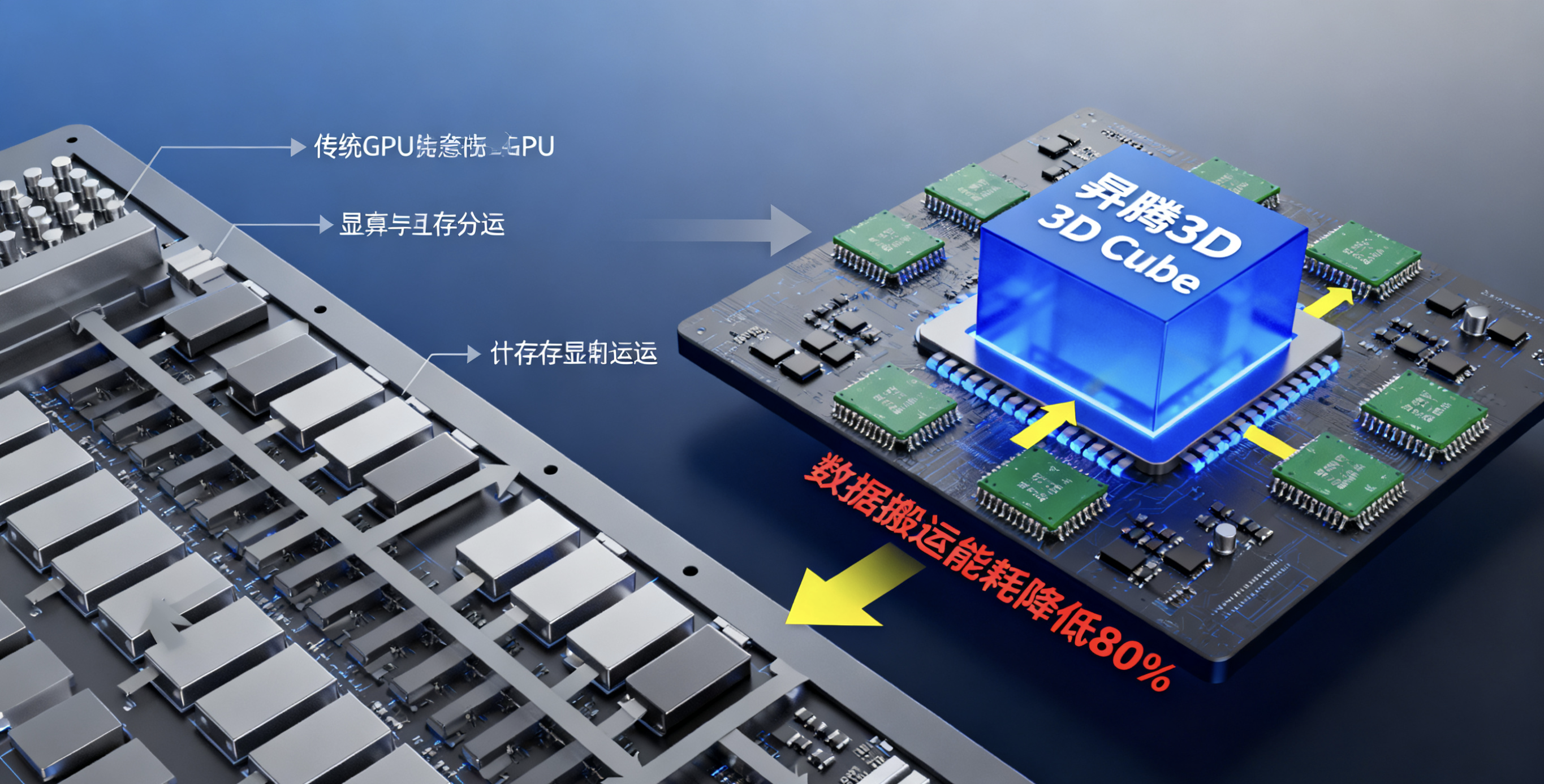
昇腾处理器的核心是**达芬奇3D Cube架构**,其设计哲学可概括为:
> **“让数据少跑路,让计算多干活”**
与传统GPU的“计算单元 + 显存”松耦合架构不同,昇腾采用**紧耦合设计**,实现三大协同:
| 协同维度 | 传统GPU | 昇腾达芬奇架构 |
|--------|--------|----------------|
| **计算-内存** | 计算单元通过高带宽总线访问显存 | Cube单元直接访问片上SRAM,带宽提升5倍 |
| **计算-通信** | 通信由独立NIC处理,与计算解耦 | 支持计算过程中启动RDMA传输,实现Overlap |
| **软硬协同** | 固定功能单元为主 | 支持CANN编译器自定义算子,灵活适配新模型 |
### **3.2 关键组件详解**
#### **(1)3D Cube矩阵计算单元**
- 单芯片集成数万个AI Core;
- 支持FP16/BF16/INT8/FP8多精度计算;
- 每秒可达 **256 TFLOPS@FP16**(昇腾910);
- 专为矩阵乘法(GEMM)优化,适用于Transformer、CNN等主流模型。
#### **(2)片上内存体系**
- 三级缓存设计:L0(寄存器)→ L1(Cube本地)→ L2(芯片共享);
- 片上SRAM容量达32MB,带宽达1.2 TB/s;
- 数据复用率提升3倍,显著减少HBM访问次数。
#### **(3)可编程性支持**
- 通过**CANN(Compute Architecture for Neural Networks)** 编译器栈,支持开发者使用**Ascend C**语言编写高性能自定义算子;
- 兼容PyTorch/TensorFlow/MindSpore等主流框架;
- 支持新兴架构如**MoE(Mixture of Experts)**、**Diffusion Models**的定制优化。
### **3.3 能效优势:数据搬运能耗降低80%**
得益于紧耦合架构,昇腾在典型AI负载下的能效比(TOPS/W)达到业界领先水平:
| 指标 | 昇腾910 | 典型GPU |
|------|--------|--------|
| 峰值算力(FP16) | 256 TFLOPS | ~200 TFLOPS |
| 功耗 | 310W | 300–400W |
| 实际模型利用率 | 85%+ | 50–60% |
| 数据搬运能耗占比 | <20% | ~60% |
> **💡 能效启示**:在数据中心级部署中,每降低10%的能耗,年运维成本可节省数百万人民币。
---
## **四、总结与展望:从“硬拼算力”到“智慧协同”的跃迁**
昇腾AI处理器的成功,标志着AI芯片设计正从“堆核竞赛”走向“系统级协同优化”的新阶段。其核心价值体现在:
| 维度 | 昇腾方案 | 行业意义 |
|------|---------|---------|
| **硬件架构** | 达芬奇3D Cube紧耦合设计 | 突破“内存墙”瓶颈 |
| **软件栈** | CANN + AOE智能调优 | 降低开发者门槛 |
| **系统能力** | 自动流水 + 算子融合 + 梯度切分 | 实现接近理论极限的性能转化 |
### **未来发展方向预测**
1. **CANN开源深化**:预计2025年将进一步开放编译器源码,吸引更多社区贡献;
2. **异构计算融合**:与鲲鹏CPU、昇腾NPU、SSD存储构成全栈AI基础设施;
3. **大模型原生优化**:针对MoE、长序列Attention等结构推出专用指令集;
4. **绿色AI推进**:目标在2026年实现PUE<1.1的数据中心级AI训练方案。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 16
16 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)