深度解析华为 CANN算子 TIK 数据搬运:从 GM 到 UB 的高性能数据流实践指南
在昇腾 AI 处理器上进行 TIK(Tensor Iterator Kernel)算子开发时,数据搬运是最基础、也是最容易影响性能的环节。算子能否高效运行,很大程度上取决于开发者是否理解 GM(Global Memory)与 UB(Unified Buffer)之间的数据流模式、对齐要求、搬运粒度以及跨循环的计算布局。
深度解析华为 CANN算子 TIK 数据搬运:从 GM 到 UB 的高性能数据流实践指南
在昇腾 AI 处理器上进行 TIK(Tensor Iterator Kernel)算子开发时,数据搬运是最基础、也是最容易影响性能的环节。算子能否高效运行,很大程度上取决于开发者是否理解 GM(Global Memory)与 UB(Unified Buffer)之间的数据流模式、对齐要求、搬运粒度以及跨循环的计算布局。
本文将带你系统理解 TIK 的数据搬运逻辑,从连续搬运、非连续搬运到偏移场景,再到平台差异带来的对齐要求,同时辅以代码示例与数据图示,帮助你全面掌握如何在真实算子开发中安全、高效地完成数据搬入与搬出。
一、为什么 TIK 需要数据搬运?
在 Ascend 架构中,向量指令执行的操作数据必须位于 UB。UB 是片上高速缓存,延迟极低,适合进行密集向量计算;而 GM 则是高容量的外部存储,访问成本远高于 UB。
因此,一个算子的执行流程一般是:
GM → UB → Vector Compute → UB → GM
TIK 提供的 data_move 指令,是开发者控制 GM 与 UB 之间搬运行为的核心接口。理解它的参数含义,是 TIK 编程最重要的第一步。
二、data_move 核心参数深度解析
data_move 的原型为:
data_move(dst, src, sid, nburst, burst, src_stride, dst_stride)
其中最关键的六个参数为:
| 参数 | 说明 |
|---|---|
| dst | 目的地址,通常是 UB |
| src | 源地址,通常是 GM |
| nburst | 搬运次数(即段数) |
| burst | 每段搬运的长度(单位为 block,1 block = 32B) |
| src_stride | 源数据段之间的间隔 block 数 |
| dst_stride | 目的数据段之间的间隔 block 数 |
一句话总结:
nburst 决定“搬运多少段”,burst 决定“每段搬多少”,stride 决定“段与段之间怎么隔开”。
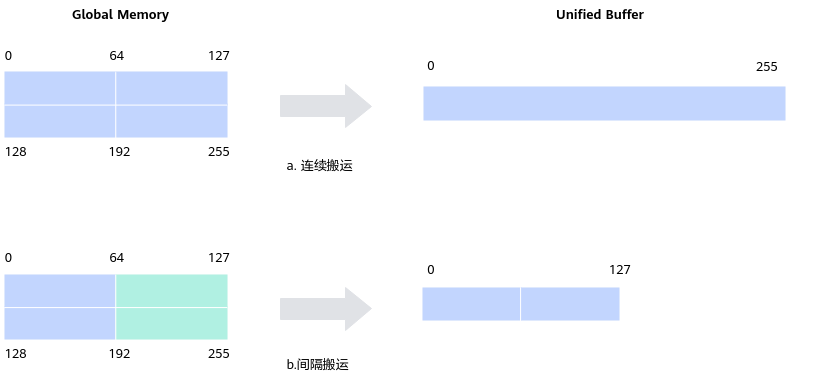
三、连续地址搬运:最典型、最常用的场景
连续搬运,即:
src_stride = 0
dst_stride = 0

示例:从 GM 连续搬运 1024B 到 UB
tik_instance.data_move(data_input_ub, data_input_gm, 0, 1, 32, 0, 0)
解析:
- 总数据量:256 * 4B = 1024B
- 一个 block = 32B
- 1024B / 32B = 32 blocks → burst=32
- 一次即可搬完 → nburst=1
这是算子开发中最常见的搬运方式,适用于大量定长张量的线性读写。
四、当数据超过 UB:分次搬运策略与多次向量计算
当一次计算所需数据超过 UB 容量(如 UB 约 248KB 可用),就必须将 GM 数据拆成多段搬入。
示例:496KB 数据分两次搬运 UB、分多次向量计算
关键逻辑:
- 分两次搬入 UB
- 分 4 次 vec_add 完成整个数据区计算
- 每段计算完成后再搬回 GM
精细之处在于:
- 向量一次最多处理 256B
- 每个循环最多重复 255 次 → 可处理
256 × 255 = 65280B - 因此 248KB 需要分 3 + 1 次处理,其中最后一段只需重复 227 次
这一段是 TIK 编程中典型的「大数据量拆分 + UB 循环计算」模式,理解它对于写大型算子至关重要。
五、间隔地址搬运:处理非连续排布的利器
非连续搬运非常适用于如下场景:
- 多 batch 数据按行存储但操作需要按列取
- 分块卷积中跨 tile 读取
- 需要写入 UB 中的特定布局
示例:
tik_instance.data_move(data_input_ub,
data_input_gm,
0,
4, # 4 段
4, # 每段 4 blocks
4, # src 每段间隔 4 blocks
2) # dst 每段间隔 2 blocks
其效果是:
GM: [####....] [####....] [####....] [####....]
UB: [####..] [####..] [####..] [####..]
按 block 粒度的间隔搬运是 Ascend 架构非常高效的硬件级操作,比软件循环计算 offset 快得多。
六、带偏移的连续搬运:从 Tensor 某个位置开始搬运
偏移 erlaubt 在实际算子中出现非常多,例如处理 padding、tail、slice 场景。
tik_instance.data_move(data_input_ub[8],
data_input_gm[16],
0, 1, 30, 0, 0)
含义:
- 从 GM 的第 3 个 block 开始读取(16 个 int32)
- 写入 UB 的第 2 个 block 开始(8 个 int32)
- 一共搬 30 blocks
这是最常用的带 offset 的搬运模式。
七、处理未对齐数据:32B 对齐与尾块回退技术
UB 通常要求:
起始地址必须 32B 对齐
但 GM 没有对齐要求。
那当输入数据不足一个 block 如何处理?
答案是:
通过“数据回退”使尾部对齐,然后重复搬运重叠部分
核心思想:
- 先搬满一个 block 的前半部分
- 再回退一部分 GM 地址,使后半部分也能搬满一个 block
- UB 中被重复搬运的区域会在最终写回 GM 时被正确覆盖
这个技巧在处理:
- 不满 32B 的 tail
- last tile
- 变长张量
时必不可少。
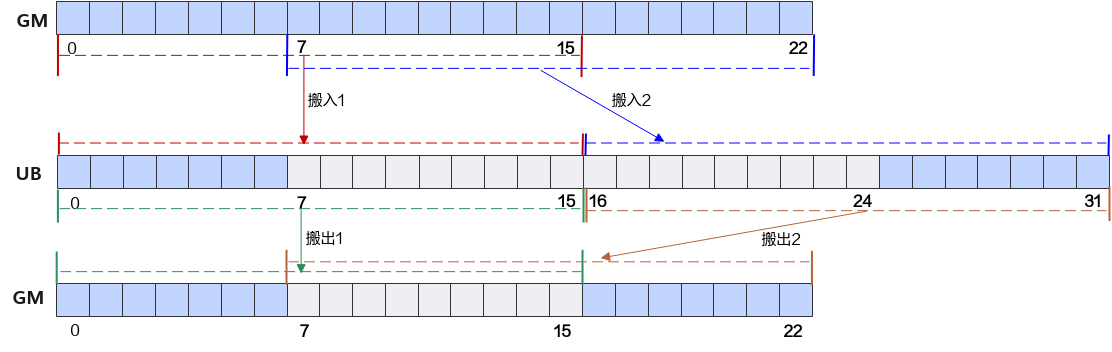
八、完整练习:实现一个带间隔与偏移的数据搬运算子
任务要求概述:
1)搬入部分(fp16 → UB)
- 从
gm[2]开始读 - 连续读取 129 个 fp16
- 写入模式:每搬 16 个 fp16,UB 需要 间隔 16 个 fp16 写入
- UB 地址必须 32B 对齐
2)搬出部分(UB → GM,int32)
- 从
ub[32]开始读 - 每搬 16 个 int32 后,UB 需 间隔 32 个 int32
- GM 中连续写入 127 个 int32
九、参考实现(可直接运行)
from tbe import tik
tik_instance = tik.Tik()
# ----- 搬入:fp16 GM -> UB -----
# 129 个 fp16,每 Block 为 16 fp16,因此共 9 Block
data_input_gm = tik_instance.Tensor("float16", (146,),
name="data_input_gm",
scope=tik.scope_gm)
data_input_ub = tik_instance.Tensor("float16", (272,),
name="data_input_ub",
scope=tik.scope_ubuf)
# 每段搬 1 Block(16 fp16),共搬 9 段
# dst_stride = 1 → UB 中隔 1 Block(16 fp16)写入
tik_instance.data_move(
data_input_ub,
data_input_gm[2],
0,
9,
1,
0,
1
)
# ----- 搬出:int32 UB -> GM -----
data_output_gm = tik_instance.Tensor("int32", (128,),
name="data_output_gm",
scope=tik.scope_gm)
data_output_ub = tik_instance.Tensor("int32", (384,),
name="data_output_ub",
scope=tik.scope_ubuf)
# 搬运 8 段,每段 2 Block(即 16 个 int32)
tik_instance.data_move(
data_output_gm,
data_output_ub[32],
0,
8,
2,
4, # 源 UB 每段之间隔 32 int32
0 # GM 连续写入
)
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 15
15 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)