深入理解并实现一个高性能的华为 CANN Matmul 算子:从架构机制到工程优化的完整实践
矩阵乘法(Matmul)是深度学习计算图中最核心、最昂贵的算子之一。无论是 Transformer 的注意力,CNN 的全连接层,还是大模型中的每一次前向与后向传播,本质上都由大量的 GEMM(General Matrix Multiplication)堆叠而成。在 CPU 上,你可能只需要调用 BLAS;在 GPU 上,你可以依赖 cuBLAS;但在昇腾平台上,如果你想真正理解性能的来源,或者为
深入理解并实现一个高性能的华为 CANN Matmul 算子:从架构机制到工程优化的完整实践
矩阵乘法(Matmul)是深度学习计算图中最核心、最昂贵的算子之一。无论是 Transformer 的注意力,CNN 的全连接层,还是大模型中的每一次前向与后向传播,本质上都由大量的 GEMM(General Matrix Multiplication)堆叠而成。
在 CPU 上,你可能只需要调用 BLAS;在 GPU 上,你可以依赖 cuBLAS;但在昇腾平台上,如果你想真正理解性能的来源,或者为特定模型定制算子,则必须亲手写一次 Ascend C Matmul。
这一篇文章,就是一次完整的实践总结:
从硬件数据流 → 算子实现 → Tiling 设计 → 性能调优 → 调试避坑,完整拆解 Matmul 的开发路线。
一、理解硬件:Cube 核心单元与 L0 缓存体系的实际工作方式
要写好 Matmul,必须先理解 Ascend AI Core 的内部结构。
大多数新手的问题,不是代码写得不对,而是对硬件“想当然”。
1.1 Cube 单元不是“矩阵计算加速器”,它就是矩阵计算本身
Ascend AI Core 的计算能力主要由两类单元提供:
- Vector Unit(标量/向量运算)
- Cube Unit(矩阵乘法专用阵列)
其中 Cube 是 Matmul 的灵魂。
Cube 的物理阵列是 16 × 16 × 16 的三维结构,这意味着:
- 输入 A tile 必须是
16 × 16 - 输入 B tile 必须是
16 × 16 - K 维度也必须按 16 聚合
这直接导致:
矩阵数据必须重排为分形格式(Fractal NZ)才能喂给 Cube。
1.2 数据流不是 GM→UB→计算,而是“特殊管线”
大多数算子数据流都是:
GM → UB → Vector运算 → GM
但 Matmul 是:
GM → L1 → L0A/L0B → Cube → L0C → GM
这里有几个关键点:
- UB 在 Matmul 主计算阶段几乎不参与
它只会在 Bias、激活等后处理用到。 - L0A/L0B 是 Cube 专用
它们的数据格式必须是 fractal。 - L0C 是 Cube 的输出缓存
没有 UB 参与。
刚开始写 Matmul 时,如果你把数据搬进 UB 再喂给 Cube,会直接报错。
这就是为什么官方文档一直强调:
理解数据流,本质上就是理解算子性能。
二、功能实现:利用 CANN 高阶 Matmul API 快速构建算子
如果你非要自己从 L1 → L0 搬运数据,手写 tiling,那代码量轻松破 2000 行。
而 CANN 的高阶 API 提供了一个模板化的 Matmul pipeline,大幅降低开发成本。
整体流程可以总结成四步:
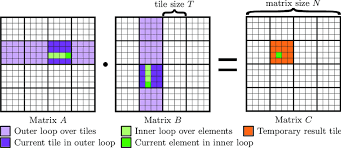
2.1 第一步:注册 Matmul 实例与 Tiling
Tiling 决定数据如何拆块,是 Matmul 的核心调度策略。
REGIST_MATMUL_OBJ(&pipe, GetSysWorkSpacePtr(), matmulObj, &tiling);
matmulObj.Init(&tiling);
高阶 API 会根据芯片型号(比如 Ascend 910B)、矩阵大小、对齐情况自动生成 Tiling 参数。
2.2 第二步:指定 GM 中的输入位置
这一部分最简单,但必须保证格式正确。
matmulObj.SetTensorA(gm_a);
matmulObj.SetTensorB(gm_b);
如果原始矩阵是普通 ND 格式,API 会在内部完成:
ND → Fractal NZ 的重排
这是很多新手不知道的点。
2.3 第三步:执行完整 Matmul 计算
最重要的一行代码:
matmulObj.IterateAll(gm_c);
你写一行,高阶 API 代你执行:
- GM → L1 的 Tile 搬运
- L1 → L0A/B 的 fractal 转换
- Cube 的 tile-by-tile 矩阵乘法
- L0C → GM 的结果写回
整个 DMA 调度、流水线、double buffer 都自动处理。
你也可以拆成手动版本:
matmulObj.Iterate();
matmulObj.GetTensorC(ub_c);
通常用于加 Bias 或 ReLU。
2.4 第四步:后处理(可选)
Bias 或激活函数必须在 UB 中完成:
for (...) {
ub_c[i] += bias[i];
ub_c[i] = max(0, ub_c[i]); // ReLU
}
这里就要用 Vector 指令。
Matmul 负责“吃大肉”,UB 和 Vector 负责“加调料”。
三、性能优化:高性能 Matmul 的关键全部藏在 Tiling 与流水线里
功能实现只是第一步,而性能才是开发算子的真正难点。
如果你直接运行 Demo,不做优化,你可能只能拿到 20% 的 Cube 利用率。
优化之后,可以提升到 80%~95%。
下面总结我在实践中最有价值的经验。
3.1 双缓冲(Double Buffer)必须打开
TensorFlow、PyTorch 里的 Matmul 都采用流水线行为:一边搬运下一块,一边计算当前块。
没有双缓冲 → Cube 计算完必须等 DMA
开启双缓冲 → DMA 与 Cube 完全重叠
在 Ascend C 中,你只需在 Tiling 参数里打开:
tiling.UseDoubleBuffer = true;
效果立竿见影。
Timeline 可以清晰看到:
| 优化前 | 优化后 |
|---|---|
| 计算、搬运交替执行 | 完全重叠,Cube “不断粮” |
3.2 Tiling 设计的关键是控制 L0/L1 容量与 Tile 粒度
Tiling 决定三件事:
- 一个 tile 的尺寸(baseM, baseN, baseK)
- Cube 单元一次可处理多少 tile
- 是否能让 L1/L0 的搬运与计算并行
自己算 Tiling 很难,需要同时满足:
- L1 能装下 A 和 B 的多个 tile
- L0C 必须能容纳一个 tile 的结果
- K 的拆分必须是 16 的倍数
最常见的错误:
- tile 设计太大 → L1 装不下 → 程序卡死
- tile 太小 → 指令调度开销反而超过计算时间
建议:
不要自己写 Tiling 逻辑,除非你非常熟悉芯片。
使用 CANN 提供的 Host 端 Tiling 库即可。
3.3 尾块 Tail Block 的细节处理
当矩阵尺寸不满足 16 对齐时,会出现尾块。
例如:
M = 1025 → 最后一块只有 1 行
N = 1000 → 非 16 对齐
K = 257 → 余 1
Cube 输入必须是 16 × 16,因此:
- B 侧尾块必须 padding
- A 侧必须 padding 到 fractal 格式
- C 侧写回时要正确截断
高阶 API 会自动处理,但如果需要手写 UB 后处理,就必须自己截断 shape。
四、调试与避坑:我的真实经验总结
这一部分是我最想写的,因为文档里“讲了但没讲清楚”的东西太多。
4.1 精度问题的根本原因:累加类型必须用 float32
输入可以是 fp16,但是累加必须 fp32,否则误差会累积爆炸。
正确写法:
typename CFgType = MatmulConfig<float16, float16, float>;
一次修正后,和 PyTorch 对比误差从 1e-1 降到 1e-5。
4.2 死锁 / 卡死现象
常见原因:
- IterateAll 与手动 iterate 混用
- UB 缓存没有按预期释放
- DMA 队列未 flush
调试方法:
MindStudio 模拟执行
可以:
- 单步查看 L0 buffer 内容
- 查看所有 DMA 通道状态
- 查看是否存在 pipeline stall
我曾经用模拟器找到一个问题:
Bias 没搬到 UB,我给所有输出加了“隐形零”,导致结果全偏小。
4.3 数据格式错位:fractal 与 ND 搞混
Cube 只能吃 fractal NZ 格式。
如果你把 ND 格式传进去,会发现:
- 代码不报错
- 但输出完全是垃圾
调试方式:
- 打印 L1 中数据 tile
- 打印 fractal tile 的物理布局(内部是按 Z 字形存的)
初学者很容易误以为“矩阵被破坏了”,其实只是格式不一致。
结语:写一次完整 Ascend C Matmul 你会学到什么?
当你真正写完一个高性能 Matmul,你会理解:
- Ascend 的每一层存储级别的作用
- Cube 是如何通过 fractal 加速矩阵乘法的
- 为什么 Tiling 与双缓冲能提升一个数量级性能
- 为什么通用编译器永远不可能做到“完全最优”
这个过程比做模型推理要难得多,但也让你看到:
AI 芯片是如何在硬件层面把矩阵乘法推到极致的。
当你看到自己的 Matmul Cube 利用率从 20% → 95% 的那一刻,你会明白:
“算子开发”才是理解 AI 计算本质最好的方式。
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 20
20 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)