Ascend C编程语言快速上手
Ascend C编程语言快速上手
昇腾训练营报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机、平板、开发板等大奖。
前言
环境搭好了,终于可以写代码了!刚开始看Ascend C代码的时候,我觉得"这不就是C++吗?"但写起来才发现,虽然语法很像,但有不少独特的地方。
今天这篇文章,我会带大家快速上手Ascend C,让你在最短时间内能看懂代码、写出简单的算子。我会用大量实例来讲解,而不是干巴巴地列语法规则。
一、Ascend C是什么?
Ascend C是华为为昇腾NPU开发设计的编程语言,专门用于编写高性能算子。
下图是昇腾算子开发页面(https://www.hiascend.com/developer/operator)展示的完整开发路径:
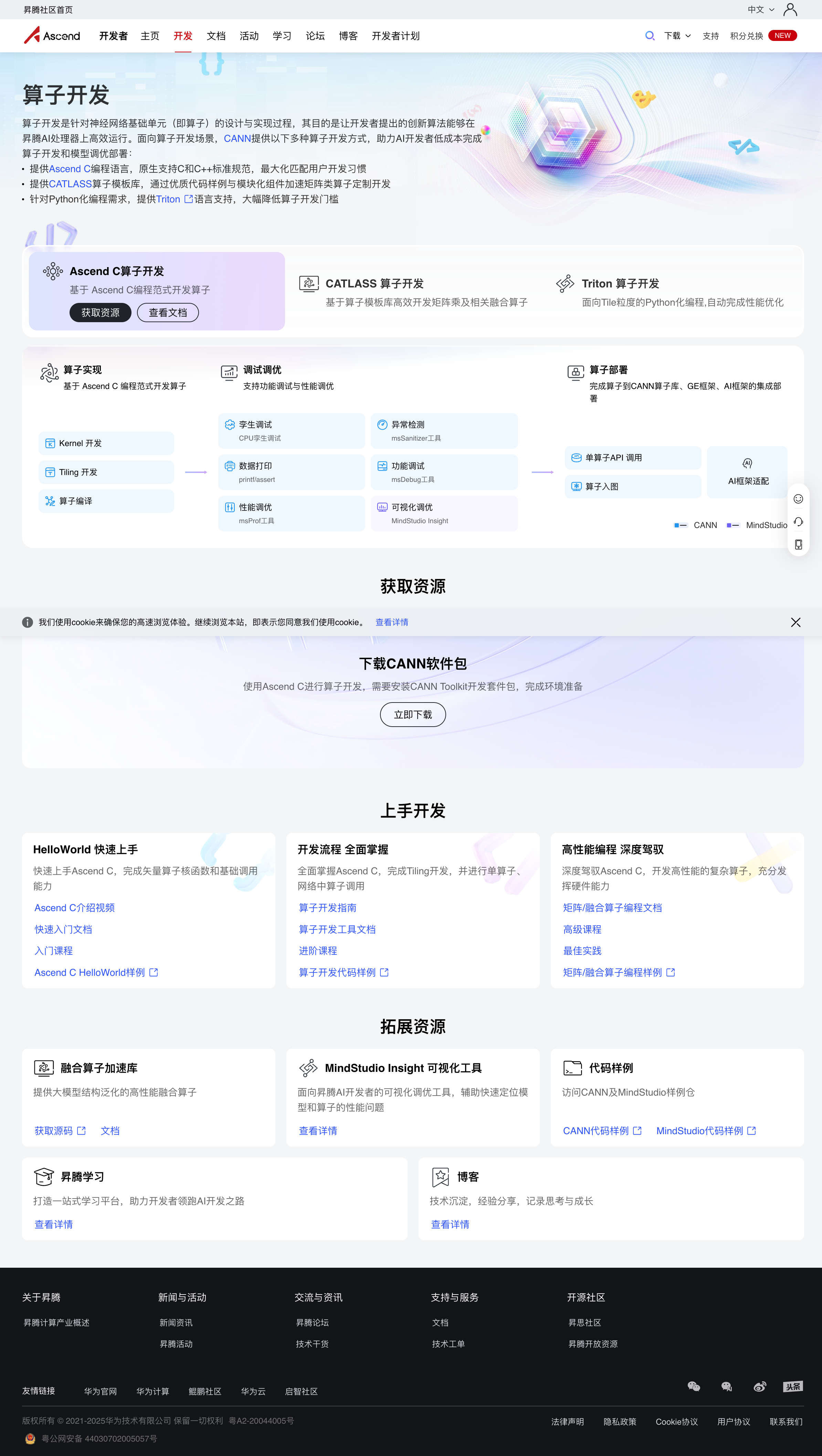
从官方页面可以看到,CANN提供三种算子开发方式:
- Ascend C:基于C/C++标准规范的原生编程语言
- CATLASS:矩阵类算子模板库,加速矩阵乘法开发
- Triton:Python化编程,降低开发门槛
1.1 与C++的关系
Ascend C基于C++14标准,所以如果你会C++,上手会非常快。主要区别在于:
| 特性 | C++ | Ascend C |
|---|---|---|
| 基础语法 | 标准C++ | 基本相同 |
| STL标准库 | 完整支持 | 部分支持 |
| 动态内存 | new/delete | 特殊API管理 |
| 并行编程 | pthread/OpenMP | NPU intrinsic指令 |
| 向量化 | 手动或编译器 | 内置Vector类型 |
简单来说:Ascend C = C++语法 + NPU专用API + 向量化扩展
1.2 为什么需要Ascend C?
你可能会问:为什么不直接用C++?
原因是NPU和CPU架构差别很大:
- NPU有专门的向量计算单元
- 内存层次更复杂(Global/Local/UB)
- 需要显式管理数据搬运
Ascend C封装了这些底层细节,让我们能更方便地发挥NPU性能。
二、第一个Ascend C程序
废话不多说,先看代码:
#include "kernel_operator.h"
using namespace AscendC;
// 定义常量:每个核处理的数据块大小
constexpr int32_t BUFFER_NUM = 2; // 双缓冲
// Kernel类:实现Add算子
class KernelAdd {
public:
__aicore__ inline KernelAdd() {}
// 初始化函数
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z, uint32_t totalLength) {
xGm.SetGlobalBuffer((__gm__ half*)x); // 输入x
yGm.SetGlobalBuffer((__gm__ half*)y); // 输入y
zGm.SetGlobalBuffer((__gm__ half*)z); // 输出z
this->totalLength = totalLength;
this->tileNum = totalLength / TILE_SIZE;
// 分配临时缓冲区
pipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_SIZE * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, TILE_SIZE * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, TILE_SIZE * sizeof(half));
}
// 主处理函数
__aicore__ inline void Process() {
for (int32_t i = 0; i < tileNum; i++) {
CopyIn(i); // 数据拷入
Compute(i); // 计算
CopyOut(i); // 数据拷出
}
}
private:
// 从Global Memory拷贝数据到Local Buffer
__aicore__ inline void CopyIn(int32_t progress) {
LocalTensor<half> xLocal = inQueueX.AllocTensor<half>();
LocalTensor<half> yLocal = inQueueY.AllocTensor<half>();
DataCopy(xLocal, xGm[progress * TILE_SIZE], TILE_SIZE);
DataCopy(yLocal, yGm[progress * TILE_SIZE], TILE_SIZE);
inQueueX.EnQue(xLocal);
inQueueY.EnQue(yLocal);
}
// 执行计算:z = x + y
__aicore__ inline void Compute(int32_t progress) {
LocalTensor<half> xLocal = inQueueX.DeQue<half>();
LocalTensor<half> yLocal = inQueueY.DeQue<half>();
LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>();
// 向量加法
Add(zLocal, xLocal, yLocal, TILE_SIZE);
outQueueZ.EnQue(zLocal);
inQueueX.FreeTensor(xLocal);
inQueueY.FreeTensor(yLocal);
}
// 将结果拷贝回Global Memory
__aicore__ inline void CopyOut(int32_t progress) {
LocalTensor<half> zLocal = outQueueZ.DeQue<half>();
DataCopy(zGm[progress * TILE_SIZE], zLocal, TILE_SIZE);
outQueueZ.FreeTensor(zLocal);
}
private:
TPipe pipe; // 数据流水线
GlobalTensor<half> xGm, yGm, zGm; // Global Memory指针
TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX, inQueueY;
TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueZ;
uint32_t totalLength;
uint32_t tileNum;
static constexpr uint32_t TILE_SIZE = 256; // 每次处理256个元素
};
// Kernel入口函数
extern "C" __global__ __aicore__ void AddKernel(GM_ADDR x, GM_ADDR y, GM_ADDR z, uint32_t totalLength) {
KernelAdd op;
op.Init(x, y, z, totalLength);
op.Process();
}
看着代码挺多,但别慌,我一点点解释。
三、核心概念解析
3.1 特殊关键字
Ascend C引入了几个新关键字:
__aicore__
表示这个函数/代码在AI Core上执行(NPU的计算核心)。
__aicore__ inline void MyFunction() {
// 这段代码运行在AI Core上
}
__gm__、__ubuf__、__ca__
用于标注内存类型:
__gm__ half* gmPtr; // Global Memory(全局内存,容量大但慢)
__ubuf__ half* ubPtr; // Unified Buffer(统一缓存,容量小但快)
__ca__ half* caPtr; // L0A Buffer(更小更快的缓存)
这些内存的关系:
我刚开始搞不清楚这些内存的区别,后来理解了:
- GM:像电脑的硬盘,很大但慢
- UB:像内存,比较快
- L0:像CPU的寄存器,超快
3.2 数据类型
Ascend C支持的基本类型:
// 浮点类型
half // FP16(常用)
float // FP32
bfloat16 // BF16(部分硬件支持)
// 整数类型
int8_t, uint8_t
int16_t, uint16_t
int32_t, uint32_t
// 向量类型(重点!)
half8 // 8个half打包
half16 // 16个half打包(128 bits)
float8 // 8个float打包
向量类型是性能关键!一条指令可以同时处理8/16个数据。
3.3 Tensor张量
Tensor是Ascend C中最重要的数据结构:
// Local Tensor(在Unified Buffer中)
LocalTensor<half> tensor1;
// Global Tensor(在Global Memory中)
GlobalTensor<half> tensor2;
// 获取Tensor的元素个数
uint32_t size = tensor1.GetSize();
// 访问元素(尽量用向量操作,少用标量访问)
half value = tensor1.GetValue(0); // 不推荐:标量访问
我的经验:尽量用向量操作,别一个个元素处理。向量化能让性能提升10倍甚至更多。
3.4 Queue队列
Queue用于管理数据流水线:
// 定义输入队列(双缓冲)
TQue<QuePosition::VECIN, 2> inQueue;
// 分配Tensor
LocalTensor<half> tensor = inQueue.AllocTensor<half>();
// 入队
inQueue.EnQue(tensor);
// 出队
LocalTensor<half> tensor2 = inQueue.DeQue<half>();
// 释放
inQueue.FreeTensor(tensor2);
双缓冲(BUFFER_NUM=2)的好处:一个buffer在计算,另一个在搬运数据,流水线并行!
四、常用API介绍
4.1 数据搬运
// DataCopy: 从源拷贝到目标
DataCopy(dstLocal, srcGm, count); // GM -> Local
DataCopy(dstGm, srcLocal, count); // Local -> GM
// 设置内存
DataFill(dstLocal, value, count); // 用value填充
4.2 向量计算
// 加法:dst = src0 + src1
Add(dst, src0, src1, count);
// 乘法:dst = src0 * src1
Mul(dst, src0, src1, count);
// 乘加:dst = src0 * src1 + src2
Mla(dst, src0, src1, src2, count);
// 比较:dst = (src0 > src1) ? 1 : 0
Compare(dst, src0, src1, CmpMode::GT, count);
// 最大值:dst = max(src0, src1)
Max(dst, src0, src1, count);
// 最小值:dst = min(src0, src1)
Min(dst, src0, src1, count);
这些都是向量化操作,一条指令处理多个数据!
4.3 数学函数
// 指数:dst = exp(src)
Exp(dst, src, count);
// 对数:dst = log(src)
Log(dst, src, count);
// 平方根:dst = sqrt(src)
Sqrt(dst, src, count);
// ReLU激活:dst = max(0, src)
Relu(dst, src, count);
// Sigmoid:dst = 1 / (1 + exp(-src))
// 需要自己组合实现,后面会讲
五、一个完整的实例:Mul算子
我们来实现一个乘法算子,巩固一下知识:
#include "kernel_operator.h"
using namespace AscendC;
constexpr int32_t BUFFER_NUM = 2;
class KernelMul {
public:
__aicore__ inline KernelMul() {}
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z, uint32_t len) {
// 设置Global Memory指针
xGm.SetGlobalBuffer((__gm__ half*)x);
yGm.SetGlobalBuffer((__gm__ half*)y);
zGm.SetGlobalBuffer((__gm__ half*)z);
this->totalLength = len;
this->blockLength = len / GetBlockNum(); // 每个核处理的长度
this->tileNum = blockLength / TILE_SIZE;
// 初始化队列
pipe.InitBuffer(queueX, BUFFER_NUM, TILE_SIZE * sizeof(half));
pipe.InitBuffer(queueY, BUFFER_NUM, TILE_SIZE * sizeof(half));
pipe.InitBuffer(queueZ, BUFFER_NUM, TILE_SIZE * sizeof(half));
}
__aicore__ inline void Process() {
int32_t loopCount = tileNum * 2; // 双缓冲需要*2
for (int32_t i = 0; i < loopCount; i++) {
if (i < tileNum) {
CopyIn(i);
}
if (i >= BUFFER_NUM && i < tileNum + BUFFER_NUM) {
Compute(i - BUFFER_NUM);
}
if (i >= BUFFER_NUM * 2) {
CopyOut(i - BUFFER_NUM * 2);
}
}
}
private:
__aicore__ inline void CopyIn(int32_t idx) {
LocalTensor<half> xLocal = queueX.AllocTensor<half>();
LocalTensor<half> yLocal = queueY.AllocTensor<half>();
uint32_t offset = GetBlockIdx() * blockLength + idx * TILE_SIZE;
DataCopy(xLocal, xGm[offset], TILE_SIZE);
DataCopy(yLocal, yGm[offset], TILE_SIZE);
queueX.EnQue(xLocal);
queueY.EnQue(yLocal);
}
__aicore__ inline void Compute(int32_t idx) {
LocalTensor<half> xLocal = queueX.DeQue<half>();
LocalTensor<half> yLocal = queueY.DeQue<half>();
LocalTensor<half> zLocal = queueZ.AllocTensor<half>();
// z = x * y
Mul(zLocal, xLocal, yLocal, TILE_SIZE);
queueZ.EnQue(zLocal);
queueX.FreeTensor(xLocal);
queueY.FreeTensor(yLocal);
}
__aicore__ inline void CopyOut(int32_t idx) {
LocalTensor<half> zLocal = queueZ.DeQue<half>();
uint32_t offset = GetBlockIdx() * blockLength + idx * TILE_SIZE;
DataCopy(zGm[offset], zLocal, TILE_SIZE);
queueZ.FreeTensor(zLocal);
}
private:
TPipe pipe;
GlobalTensor<half> xGm, yGm, zGm;
TQue<QuePosition::VECIN, BUFFER_NUM> queueX, queueY;
TQue<QuePosition::VECOUT, BUFFER_NUM> queueZ;
uint32_t totalLength;
uint32_t blockLength;
uint32_t tileNum;
static constexpr uint32_t TILE_SIZE = 256;
};
extern "C" __global__ __aicore__ void MulKernel(GM_ADDR x, GM_ADDR y, GM_ADDR z, uint32_t totalLength) {
KernelMul op;
op.Init(x, y, z, totalLength);
op.Process();
}
代码要点说明
- 多核并行:
GetBlockNum()和GetBlockIdx()用于多核分配任务 - 流水线:CopyIn、Compute、CopyOut并行执行
- 双缓冲:
loopCount = tileNum * 2,保证流水线满载
六、我踩过的坑
坑1:忘记初始化Buffer
// ❌ 错误:没有InitBuffer就使用
LocalTensor<half> tensor = queue.AllocTensor<half>();
// ✅ 正确:先InitBuffer
pipe.InitBuffer(queue, BUFFER_NUM, TILE_SIZE * sizeof(half));
LocalTensor<half> tensor = queue.AllocTensor<half>();
这个错误会导致运行时crash,而且错误信息不明显,调试了好久。
坑2:数据对齐问题
Ascend C对数据对齐有要求,TILE_SIZE通常要是32的倍数(FP16)。
// ❌ 错误
static constexpr uint32_t TILE_SIZE = 100;
// ✅ 正确
static constexpr uint32_t TILE_SIZE = 128; // 32的倍数
坑3:内存越界
// 要处理边界情况
uint32_t remainLength = totalLength % TILE_SIZE;
if (remainLength > 0) {
// 处理最后不足一个tile的数据
ProcessTail(remainLength);
}
七、Ascend C vs C++对比
让我们对比一下同样功能的代码:
标准C++实现(CPU):
void add_cpu(float* x, float* y, float* z, int n) {
for (int i = 0; i < n; i++) {
z[i] = x[i] + y[i];
}
}
Ascend C实现(NPU):
// 需要考虑:
// 1. 数据搬运(GM <-> UB)
// 2. 向量化计算
// 3. 多核并行
// 4. 内存管理
// 代码量大概是C++的5-10倍
// 但性能也提升了几十倍甚至上百倍!
这就是为什么要学Ascend C:用更复杂的代码,换取巨大的性能提升。
八、学习建议
基于我的学习经历,给大家几点建议:
- 不要一开始就啃文档:先跑通代码,有感觉了再看文档
- 多看官方samples:
/usr/local/Ascend/ascend-toolkit/latest/samples/下有很多例子 - 从简单算子开始:Add、Mul、Sub这种,逐步过渡到Conv、Attention
- 遇到问题查日志:
/var/log/npu/下有详细的错误日志 - 参加训练营:有老师指导,少走弯路
九、调试技巧
分享几个我常用的调试方法:
方法1:打印调试
// 使用printf(只能在__aicore__外使用)
// 在AI Core内不能直接printf,需要把数据拷回CPU再打印
// 在host端打印Tensor内容
void PrintTensor(half* data, int size) {
for (int i = 0; i < size && i < 10; i++) { // 只打印前10个
printf("%f ", (float)data[i]);
}
printf("\n");
}
方法2:对比CPU结果
// CPU参考实现
void RefAdd(float* x, float* y, float* z, int n) {
for (int i = 0; i < n; i++) {
z[i] = x[i] + y[i];
}
}
// 对比NPU结果和CPU结果
float maxDiff = 0;
for (int i = 0; i < n; i++) {
float diff = fabs(npu_result[i] - cpu_result[i]);
maxDiff = max(maxDiff, diff);
}
printf("Max diff: %f\n", maxDiff);
方法3:使用msopst工具
# 生成算子的中间表示
msopst --mode=1 --input=kernel.o --output=kernel.json
# 查看生成的指令
cat kernel.json
十、总结
Ascend C入门要点:
- 语法基础:类似C++,但有NPU特有的关键字和API
- 核心概念:Tensor、Queue、Pipeline
- 内存管理:GM、UB、L0三级存储
- 向量化:性能的关键,用向量操作替代标量循环
- 流水线:数据搬运和计算并行,提升效率
Ascend C不难,但需要一些时间适应NPU的编程模型。我自己大概花了一周时间,从完全看不懂到能写简单算子。现在回头看,最重要的是多动手,多实践。
下一篇文章,我会深入讲解CANN算子开发的核心概念,包括Tiling策略、数据分块等,这些是性能优化的基础。
有问题欢迎留言讨论!点赞收藏支持一下~

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐


 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)