Ascend CL 原生调用实战:昇腾全栈兼容的算子部署方案
本文介绍了使用AscendCL原生调用方式部署AscendC算子的完整流程。AscendCL作为昇腾AI全栈核心框架,具有硬件兼容(支持昇腾全系列芯片)、工具链集成和场景适配等优势。文章详细展示了从算子封装、库编译到部署的实战步骤,包括核心计算逻辑编写、aclnn算子注册、CMake编译配置及AscendCL调用示例。同时重点分析了AscendCL在动态shape支持、多精度适配和性能优化方面的特
前言
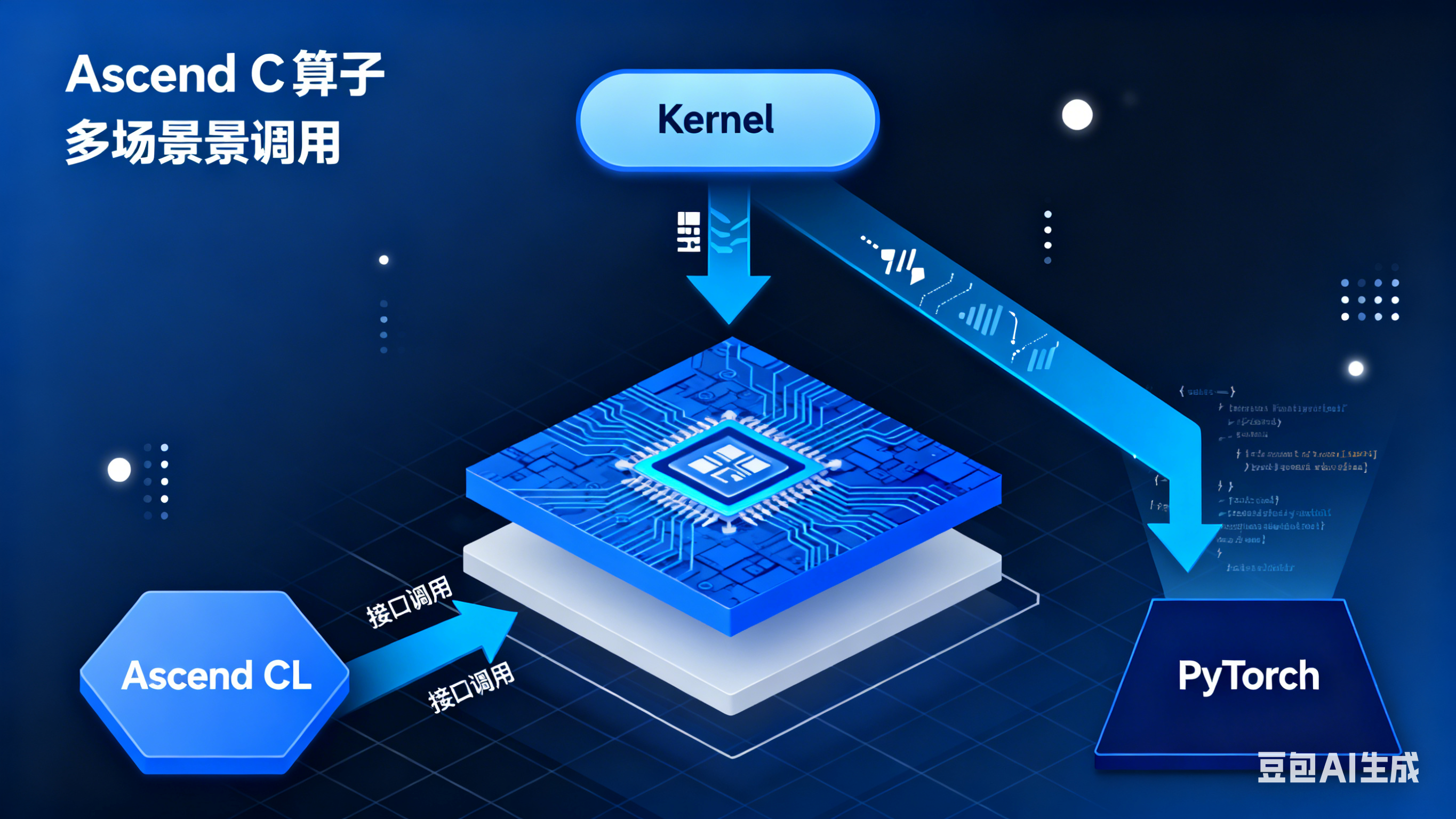
在企业级 AI 部署场景中,兼容性、灵活性与性能同样重要。Ascend CL 作为昇腾 AI 全栈的核心编程框架,提供了统一的算子调用接口,兼容昇腾 AI 处理器、开发板、云服务器等全场景。本文将聚焦 Ascend C 算子的 Ascend CL 原生调用方式,详解从算子封装、库编译到部署落地的完整流程,助力开发者实现全场景高效部署。
一、Ascend CL 原生调用核心价值
1.1 全栈兼容能力
- 硬件兼容:支持 Ascend 310/310B/910/910B 等全系列昇腾芯片,以及 Atlas 开发板、云服务器、边缘设备
- 工具链兼容:无缝集成 MindStudio、Ascend Compiler、Profiling 等昇腾全栈工具
- 场景兼容:支持静态 / 动态 shape、单卡 / 多卡、推理 / 训练等多样化部署需求
1.2 平衡性能与开发效率
- 性能接近 Kernel 直调:仅比 Kernel 直调高 5% 以内的性能损耗,远优于框架间接调用
- 开发效率高:无需手动管理线程与内存,内置动态适配能力
- 运维成本低:统一的部署接口,降低多场景维护复杂度
1.3 自动化优化能力
通过 Ascend CL 工具链,算子可获得自动化优化:
- 算子融合:自动将相邻算子融合为一个 Kernel,减少调度开销
- 内存优化:智能内存复用与缓存管理,降低内存占用
- 精度转换:支持 FP32/FP16/INT8 等多精度自动转换
二、Ascend CL 算子封装与调用实战
2.1 环境准备
- 系统要求:Ubuntu 20.04/CentOS 7.6
- 软件依赖:CANN 7.0+、Ascend CL 开发包
- 开发工具:MindStudio(推荐,提供可视化开发环境)
2.2 算子封装三步法
步骤 1:编写核心计算逻辑(复用 Kernel 代码)
cpp
运行
// dispersion_correction_core.cc
#include "dispersion_correction_core.h"
void DispersionCorrectionKernel(const float* input, float* output, int size, float alpha) {
for (int i = 0; i < size; i++) {
output[i] = input[i] * alpha + sqrt(input[i]);
}
}
步骤 2:aclnn 算子封装与注册
通过 REGISTER_ACLNN_OP 宏将核心逻辑注册为 aclnn 标准算子:
cpp
运行
// dispersion_correction_aclnn.cc
#include "acl/acl.h"
#include "acl/acl_nn.h"
#include "dispersion_correction_core.h"
// 算子描述结构体
struct DispersionCorrectionParam {
float alpha;
};
// 形状推导函数(支持动态shape)
aclError DispersionCorrectionInferShape(const aclTensorDesc *inputDesc, aclTensorDesc *outputDesc, void *param) {
// 输出形状与输入一致
return aclTensorDescCopy(outputDesc, inputDesc);
}
// 类型推导函数
aclError DispersionCorrectionInferType(const aclTensorDesc *inputDesc, aclTensorDesc *outputDesc, void *param) {
// 输出类型与输入一致
aclDataType dataType;
aclTensorDescGetDataType(inputDesc, &dataType);
return aclTensorDescSetDataType(outputDesc, dataType);
}
// 算子执行函数
aclError DispersionCorrectionExecute(const aclTensor *input, aclTensor *output, const DispersionCorrectionParam *param, aclrtStream stream) {
// 获取Tensor内存地址
const void* inputData = aclTensorGetData(input);
void* outputData = aclTensorGetData(output);
// 获取Tensor大小
int64_t size;
aclTensorDescGetElementCount(aclTensorGetDesc(input), &size);
// 调用核心计算逻辑
DispersionCorrectionKernel(static_cast<const float*>(inputData),
static_cast<float*>(outputData),
static_cast<int>(size),
param->alpha);
return ACL_SUCCESS;
}
// 注册aclnn算子
REGISTER_ACLNN_OP(DispersionCorrection, // 算子名称
1, // 输入Tensor数量
1, // 输出Tensor数量
DispersionCorrectionInferShape, // 形状推导函数
DispersionCorrectionInferType, // 类型推导函数
DispersionCorrectionExecute, // 执行函数
sizeof(DispersionCorrectionParam), // 参数大小
ACLNN_OP_TYPE_CUSTOM); // 算子类型
步骤 3:编译生成算子库
编写 CMakeLists.txt:
cmake
cmake_minimum_required(VERSION 3.15)
project(AscendCLNNDemo)
# 查找Ascend CL依赖
find_package(AscendCL REQUIRED)
include_directories(${AscendCL_INCLUDE_DIRS})
link_directories(${AscendCL_LIBRARY_DIRS})
# 编译算子库(动态库.so)
add_library(dispersion_correction_aclnn SHARED
dispersion_correction_core.cc
dispersion_correction_aclnn.cc)
# 链接Ascend CL库
target_link_libraries(dispersion_correction_aclnn ${AscendCL_LIBRARIES})
# 设置输出目录
set_target_properties(dispersion_correction_aclnn PROPERTIES
LIBRARY_OUTPUT_DIRECTORY ${PROJECT_SOURCE_DIR}/lib)
编译命令:
bash
运行
mkdir build && cd build
cmake .. -DCMAKE_BUILD_TYPE=Release
make -j8
编译完成后,在 lib 目录下生成 libdispersion_correction_aclnn.so 算子库。
2.3 Ascend CL 调用算子库
cpp
运行
// main.cc
#include "acl/acl.h"
#include "acl/acl_nn.h"
#include <iostream>
int main() {
// 1. 初始化Ascend CL环境
aclError ret = aclInit(nullptr);
if (ret != ACL_SUCCESS) {
std::cerr << "aclInit failed, error code: " << ret << std::endl;
return -1;
}
// 2. 创建设备上下文与流
aclrtContext context;
ret = aclrtCreateContext(&context, 0);
aclrtStream stream;
ret = aclrtCreateStream(&stream);
// 3. 加载算子库
const char* soPath = "./lib/libdispersion_correction_aclnn.so";
ret = aclnnLoadOpLibrary(soPath);
if (ret != ACL_SUCCESS) {
std::cerr << "Load op library failed, error code: " << ret << std::endl;
return -1;
}
// 4. 创建输入输出Tensor
int64_t shape[] = {1024, 512}; // 动态shape支持
int32_t dimCount = 2;
aclTensorDesc *inputDesc = aclTensorDescCreate(ACL_FLOAT, dimCount, shape, ACL_FORMAT_NCHW);
aclTensor *inputTensor = aclTensorCreate(inputDesc, ACL_MEM_MALLOC_HUGE_FIRST);
aclTensorDesc *outputDesc = aclTensorDescCreate(ACL_FLOAT, dimCount, shape, ACL_FORMAT_NCHW);
aclTensor *outputTensor = aclTensorCreate(outputDesc, ACL_MEM_MALLOC_HUGE_FIRST);
// 5. 初始化输入数据(模拟业务数据)
float* hostInput = new float[1024*512];
for (int i = 0; i < 1024*512; i++) {
hostInput[i] = static_cast<float>(rand()) / RAND_MAX;
}
ret = aclrtMemcpy(aclTensorGetData(inputTensor), aclTensorGetSize(inputTensor),
hostInput, aclTensorGetSize(inputTensor), ACL_MEMCPY_HOST_TO_DEVICE);
// 6. 配置算子参数
DispersionCorrectionParam param;
param.alpha = 0.8f;
// 7. 执行算子
ret = aclnnExecuteOp("DispersionCorrection", // 算子名称(与注册时一致)
1, &inputTensor, // 输入Tensor列表
1, &outputTensor, // 输出Tensor列表
¶m, sizeof(param), // 算子参数
stream);
// 8. 等待执行完成
ret = aclrtSynchronizeStream(stream);
// 9. 结果验证与资源释放(省略具体代码)
std::cout << "Operator execution success!" << std::endl;
// 资源释放(省略)
delete[] hostInput;
aclTensorDestroy(inputTensor);
aclTensorDestroy(outputTensor);
aclTensorDescDestroy(inputDesc);
aclTensorDescDestroy(outputDesc);
aclrtDestroyStream(stream);
aclrtDestroyContext(context);
aclnnUnloadOpLibrary(soPath);
aclFinalize();
return 0;
}
三、关键特性与场景适配
3.1 动态 shape 支持
通过 InferShape 与 InferType 接口,算子可自动适配不同输入形状:
- 动态 batch size:支持 1-1024 任意 batch size 输入
- 可变维度:无需修改算子代码,自动适配不同序列长度
- 形状推导:运行时自动推导输出形状,简化调用逻辑
3.2 多精度支持
通过 aclTensorDesc 设置数据类型,支持多精度部署:
cpp
运行
// 设置INT8精度
aclTensorDescSetDataType(inputDesc, ACL_INT8);
// 设置FP16精度
aclTensorDescSetDataType(inputDesc, ACL_FLOAT16);
3.3 性能优化技巧
- 算子融合:通过 MindStudio 的算子融合工具,将自定义算子与昇腾原生算子融合
- 内存预分配:使用 ACL_MEM_MALLOC_HUGE_FIRST 分配大内存,提升访问速度
- 流并发:多算子通过不同 stream 并发执行,提高硬件利用率
四、部署优势对比
| 部署方案 | 兼容性 | 开发效率 | 性能 | 运维成本 |
|---|---|---|---|---|
| Kernel 直调 | 低(固定硬件) | 低 | 最高 | 高 |
| Ascend CL 原生 | 高(全场景) | 中 | 高 | 低 |
| PyTorch 框架 | 中(框架限制) | 高 | 中 | 中 |
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

CANN开发者社区旨在汇聚广大开发者,围绕CANN架构重构、算子开发、部署应用优化等核心方向,展开深度交流与思想碰撞,携手共同促进CANN开放生态突破!
更多推荐



 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)