
低比特计算驱动AI算力新纪元,华为开放全新数据格式引领芯片创新
【中国,上海,2025年9月18日至20日,华为全联接大会2025在上海举办。会上宣布开放华为研发的HiFloat数据格式,对其格式竞争力、落地芯片产品的路标以及生态构建策略进行介绍。并诚邀生态伙伴和开发者共同构建HiFloat数据格式生态。】
在人工智能算力竞争日益激烈的背景下,低比特数据格式已成为提升芯片计算效率的关键技术。通过采用8位/4位等低精度格式,AI芯片可在保持模型精度的同时大幅提升算力密度与能效比,华为开发了HiF8和HiF4数据格式,相比BF16可降低50%和75%的显存占用,并实现2~8倍的矩阵乘算力提升。新一代昇腾950芯片将于2026年Q1上市,支持HiF8格式,可使模型训推获取8-bit浮点高效计算的同时,端到端保持精度接近FP16的水平;2027年推出昇腾960芯片将进一步支持HiF4格式,实现业界最优的4-bit精度,显著提升推理吞吐量与精度表现,为AI基础设施提供更强算力支撑。而在生态构建方面,华为计划将其贡献给全球计算联盟GCC,与全球企业用户和高校等组织共建HiFloat生态,实现从应用到设备的全生态共创。
华为昇腾计算业务总裁张迪煊在其主题演讲中进一步对HiF8数据格式进行了详细介绍:“当前, 低精度计算是提升训推效率的关键。我们为此开放了HiF8数据格式标准。HiF8在传统浮点格式中引入动态点位域,使指数与尾数位长灵活可变。这一设计在扩大数值表达范围、有效避免数值溢出。HiF8的精度位宽呈锥形分布,更贴合实际数据特征,实现综合指数范围接近FP16,精度持平FP8。HiF8的技术论文已发表,并在IEEE启动标准立项,我们还将联合全球计算联盟(GCC)制定团标,并面向全球开放。当前,我们正联合国内外高校与企业,共同验证HiF8在各场景的技术与商业价值。目前HiF8已实现精度达标,其性能加速将在下一代产品中得到进一步验证”

HiFloat8:8-bit单数据格式
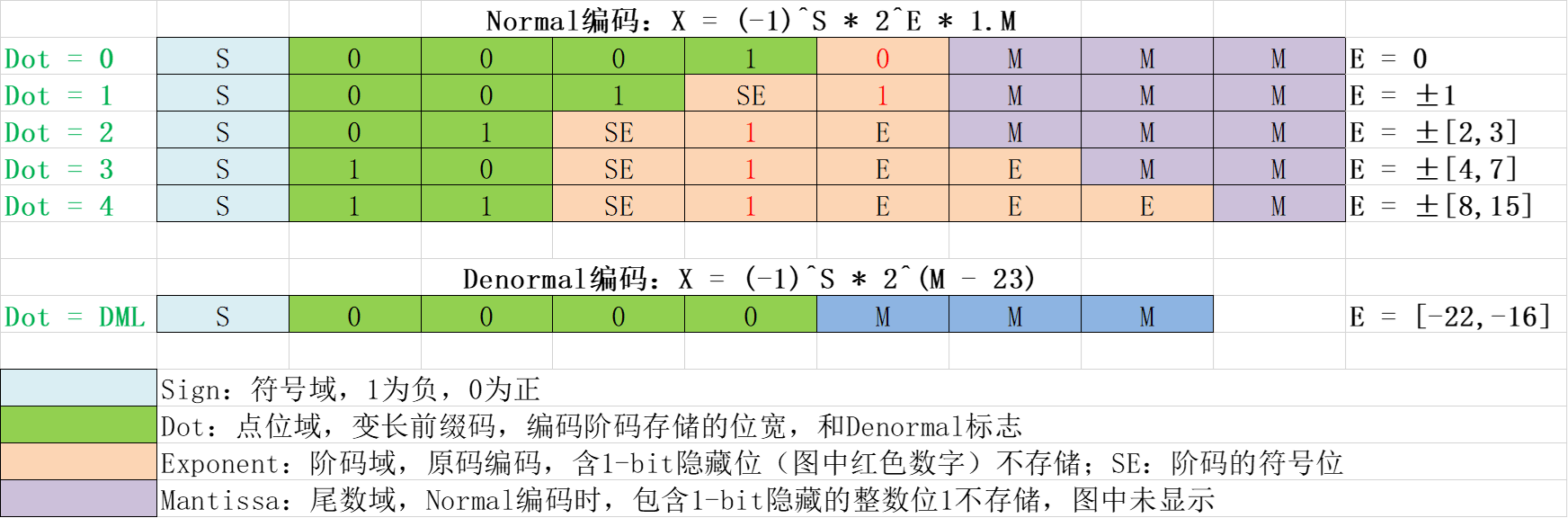
图2. HiF8编码示意图
HiF8数据格式如图2所示,其编码具有如下特征:
- HiF8利用变长前缀码编码的点位域Dot,显示指示阶码存储的位宽和Denormal标志,实现符合AI类高斯数据分布特征的锥形精度格式。
- 同时阶码采用原码编码,并隐藏了1-bit固定值不存储,确保了不同位宽的阶码表达范围不重复,进而实现无冗余编码。
- 最后通过特殊的Denormal设计,将综合阶码范围从[-15, 15]提升到了[-22, 15], 共38个阶码,接近FP16的40个综合阶码值表达。
HiF8同时支持4个特殊值,具体如下:
- 当S = 0, D = DML, M = 000,X = Zero
- 当S = 1, D = DML, M = 000,X = NaN
- 当D = 4, E = 15, M = 1时,X = ±
Inf
可以看到,HiF8用一个编码模式来表示零,且不区分正零和负零。
综上,HiF8兼顾精度和动态范围,为神经网络的训练和推理,提供了能力更全面的8-bit单数据格式表达。根据前述HiF8编码示意图和特殊值支持描述,可以画出图3所示的HiF8有效位-阶码分布图,即锥形精度图:
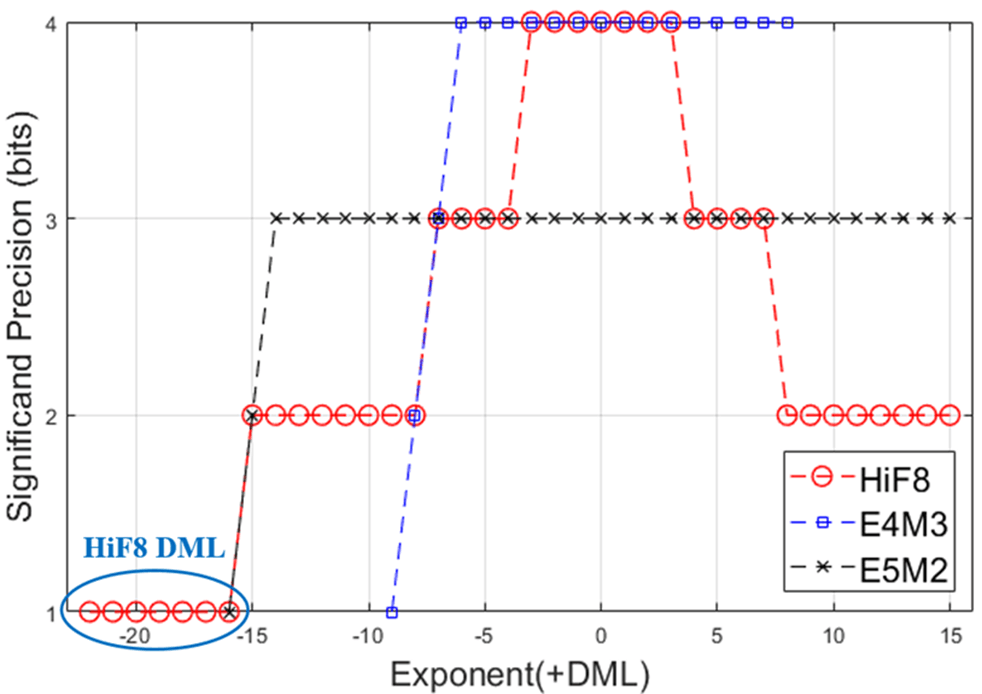
图3. HiF8有效位-阶码分布图
可以看到,
- HiF8在数值绝对值靠近1的时候,精度高;远离1,精度逐渐降低。精度不存在跳变,都是比特数为1的渐变。
- HiF8的综合阶码范围达到[-22, 15],和FP16的[-24, 15]接近,共有38个powers of 2。
总结:相比MXFP8块浮点格式,8-bit单数据格式FP8和HiF8由于训练算法更为简洁,无需按行按列分别量化激活值,权重和梯度等参数,通常能获得更高的训练性能加速比。而相比FP8,HiF8由于动态范围更大,在使用delayed-scaling训练策略时,训练稳定性更好,loss曲线不容易跑飞。同时HiF8可以适当降低Per-tensor Scaling的Amax(最大绝对值)统计频次,占用更少的Vector计算资源,从而相比FP8训练,有机会取得更高的训练性能加速比。目前已在稠密和稀疏的LLM和AIGC等典型模型上完成HiF8的精度验证。

1331
更多推荐


 0
0 0
0- 0



 已为社区贡献301条内容
已为社区贡献301条内容

所有评论(0)